一.KNN算法
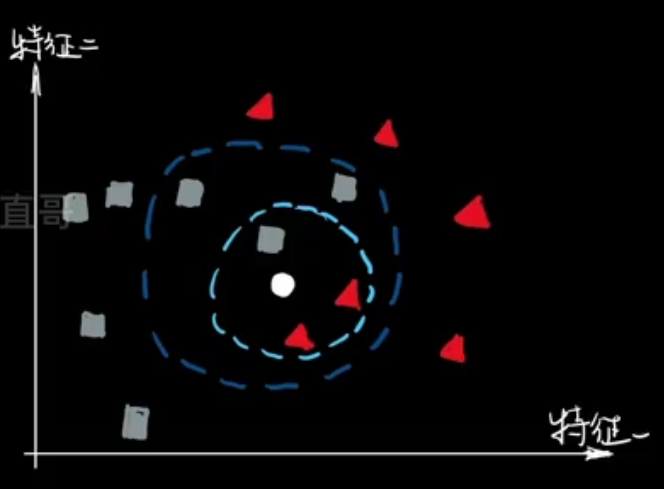
KNN:即K近邻算法。当需要表示一个样本(值)的时候,就使用与该样本最接近的K个邻居来决定。KNN即可以用于分类,也可以用于回归。
KNN算法的过程为:
1.从训练集中选择离待预测样本最近的k个样本。
2.根据这k个样本计算待预测样本的值(属于哪个类别或者一个具体数值)。
二.KNN分类
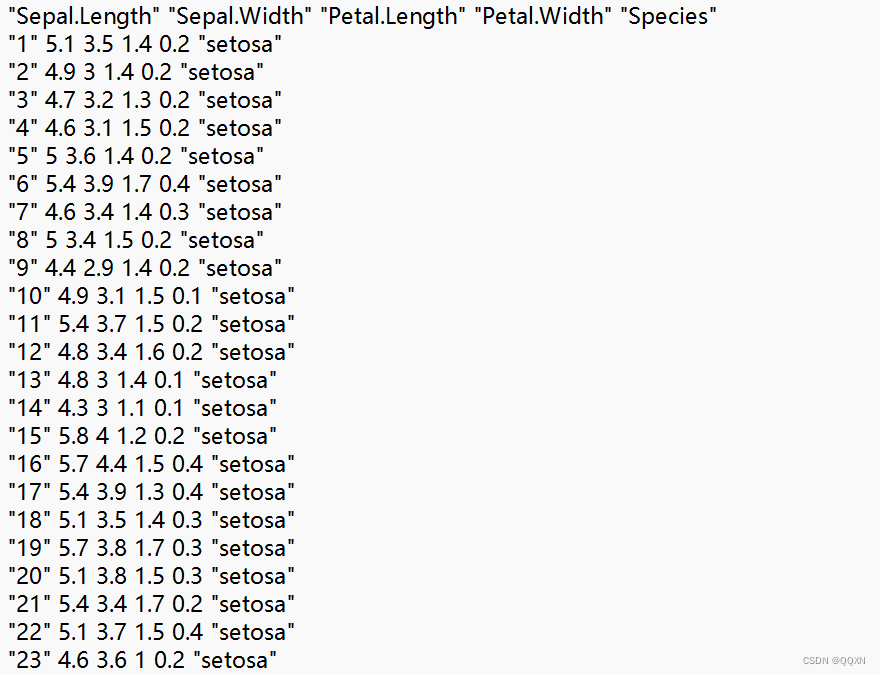
用python语言,读取csv文件header参数来指定标题的行。默认为0,如果没有标题,则使None。
显示前n行的记录,默认n的值为5。data.haed()
显示末尾的n行记录,默认n的值为5。data.tail()
随机抽取样本,默认抽取一条,我们可以通过参数进行指定抽取样本的数量。data.sample(10)
将类别文本映射成为数值类型。data[] = data[].map([])
删除不需要的Id列。data.drop("Id",axis=1,inplace=True)
查看数据集的记录数。Ien(data)
删除重复的记录。data.drop_duplicates(inplace=True)
查看各个类别的xxx具有多少条记录。data[].value_counts()
三.KNN算法实现
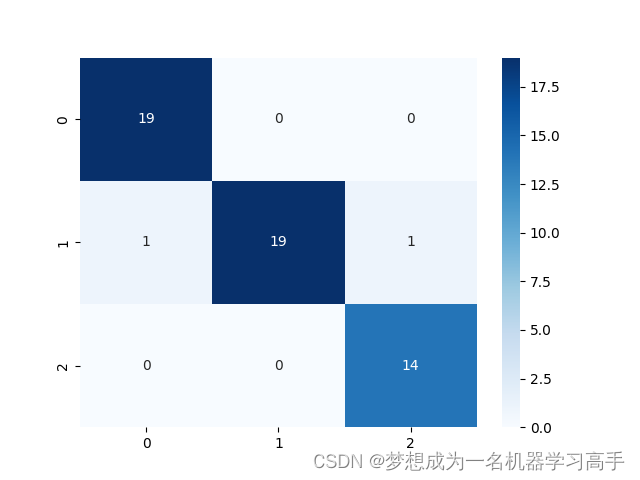
使用python语言实现K近邻算法。(实现分类)