系列文章目录
【论文精读】Transformer:Attention Is All You Need
【论文精读】BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding
【论文精读】VIT:vision transformer论文
文章目录
一、前言
- Transformer:
- 使用纯注意力机制的编码器结构
- 在机器翻译任务上比RNN架构更好
- Bert:
- 基于transformer编码器的架构,将transformer拓展到更一般的NLP任务上面
- 使用了完形填空的自监督训练机制,不需要使用标号,而是通过预测一个句子中看不见的masked的词,从而获取对文本特征的抽取的能力,所以Bert可以在大规模的,没有标号的数据上,训练出很好的模型
- (Bert预测的东西相对简单,所以其解码器就是最后那一个全连接输出层)
- Vit:
- 可以理解成transformer在图像方面的应用
- 将图片分割成一个个小的patch,每个方块当作一个词,然后放进transformer中去训练,
- vit证明在训练数据集足够大的时候,精度相对于cnn精度会更高
- MAE:
- 可以认为是Bert的cv版本,将整个训练拓展到没有标号的数据上面。通过完形填空获得对图片的理解。
二、文章概览
(一)研究背景
自监督预训练在nlp领域得到了很好的发展(基于GPT中的自回归语言建模和 BERT中的屏蔽自动编码),但视觉自动编码方法的进展却落后于 NLP。
视觉和语言之间的屏蔽自动编码的不同之处:
- 在视觉领域,卷积网络在过去十年中占据主导地位,卷积通常在规则网格上运行,将掩码标记或位置嵌入等“指标”集成到卷积网络中并不简单;
- 语言和视觉之间的信息密度不同,语言具有高度语义和信息密度。当训练模型仅预测每个句子中的几个缺失单词时,此任务似乎会引发复杂的语言理解。而图像是具有大量空间冗余的自然信号,可以从邻近的patch中恢复丢失的patch,而几乎没有高级别的信息;
为了克服视觉与语言之间存在的这种差异并使得模型学习到有用的特征,文章采用的策略是屏蔽很大一部分的随机patch。这种策略不仅在很大程度上减少了冗余,并创造了一项具有挑战性的自我监督任务,需要超越低级图像统计的整体理解。

- 语言和视觉的输出级别不同:在语言中,解码器预测包含丰富语义信息的缺失单词,而在视觉中,解码器重建图像像素,像素的语义级别要更低。因此,虽然在 BERT 中,解码器可能很简单(MLP),但对于图像,解码器设计在确定学习的潜在表示的语义级别方面起着关键作用。
(二)MAE的主要思想:
屏蔽输入图像的随机patch并重建丢失的像素(屏蔽的是块,预测的是块里的所有像素)
- 非对称编码器-解码器架构:
- 编码器作用于可见的patch
- 轻量级解码器用于用于根据潜在表示和掩码标记重建原始图像
非对称:编码器和解码器看到的内容是不一致的
- 屏蔽高比例的输入图像(例如 75%)会产生一项不平凡且有意义的自我监督任务
- 意思就是说如果屏蔽的内容太少,任务过于简单,模型很难学到有意义的内容
- 屏蔽的内容较多时,模型能够学到更多有意义的内容

(三)相关工作
- 掩码语言建模
- 自动编码
- 掩码图像编码
- 自监督学习
三、模型细节
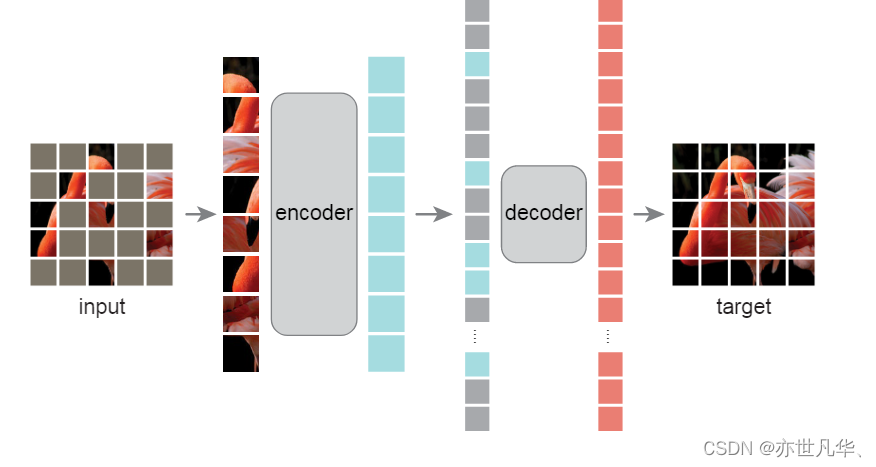
掩码自动编码器(MAE)是一种简单的自动编码方法,可以在给定部分观察的情况下重建原始信号:
- 与所有自动编码器一样,MAE方法由编码器和解码器组成。编码器将观察到的信号映射到潜在表示,解码器从潜在表示中重建原始信号。
- 与经典自动编码器不同,MAE采用非对称设计,允许编码器仅对部分观察到的信号(没有掩码标记)进行操作,并采用轻量级解码器,从潜在表示和掩码标记中重建完整信号。
(一)掩码
将图像划分为规则的不重叠的块,然后随机采样patch的子集,屏蔽(即删除)剩余没有采样到的patch。
随机采样遵循均匀分布,不放回。均匀分布可以防止潜在的中心偏差(即图像中心附近有更多的掩模斑块)。
(二)MAE编码器
MAE的编码器就是ViT,没有做任何改动,但是它之作用在可见的、未屏蔽的补丁。
具体做法与ViT一致,通过添加位置嵌入的线性投影来嵌入patch,然后通过一系列 Transformer 块处理结果集。对于被mask掉的patch,不会输入MAE编码器。
(三)MAE解码器
- MAE 解码器的输入是完整的标记集,包括编码的可见patch和掩码标记。这个完整集合中的所有标记都会加入位置嵌入,从而获取他们在图像中的位置信息。
- 所有被mask掉的patch的编码是一个共享的、课学习的向量。
- MAE 解码器仅在预训练期间用于执行图像重建任务。因此可以以独立于编码器设计的方式灵活地设计解码器架构。(进行其他任务时可以灵活的选择对应的解码器)
(四)重建目标
解码器的最后一层是线性投影,其输出通道的数量等于patch中像素值的数量。
如果一块patch里的像素是16x16,线性层就是256的维度。
损失函数:像素空间中重建图像和原始图像之间的均方误差(MSE)
仅在屏蔽patch上计算损失
(五)简单实现
- 将图像划分成 patches:(B,C,H,W)->(B,N,PxPxC);
- 对各个 patch 进行 embedding(实质是通过全连接层),生成 tokens,并加入位置信息(position embeddings):(B,N,PxPxC)->(B,N,dim);
- 随机均匀采样。将序列随机打乱(shuffle),前25%作为unmask tokens 输入 Encoder,后面的丢掉
- 编码后的 tokens 与 masked tokens( 可以学习的向量,加入位置信息)unshuffle,还原到原来的顺序,然后喂给 Decoder。
如果 Encoder 编码后的 token 的维度与 Decoder 要求的输入维度不一致,则需要先经过 linear projection 将维度映射到符合 Decoder 的要求
- Decoder 解码后取出 masked tokens 对应的部分送入到全连接层,对 masked patches 的像素值进行预测,最后将预测结果(B,N’,PxPxC)与 masked patches 进行比较,计算 MSE loss。
四、ImageNet数据集上的实验
(一)MAE与ViT的比较
- scratch,original:ViT-L/16模型在ImageNet-1k上从头训练,效果其实不是很稳定。(200epoch)
- scratch,our impl.:ViT-L/16加上比较强的正则,从72.5提升到了82.5。
- baseline MAE:先使用MAE做预训练,然后在ImageNet上做微调,这时候就不需要训练完整的200个epoches,只需要50个就可以了,从82.5提升到了84.9。

(二)消融实验
第一列(ft)表示所有可以学习的权重都跟着调,第二列(lin)表示只调最后一个线性层
解码器深度(需要用到多少个transformer块):ft方式虽然比较贵,但是效果会好很多。使用8块比较好,不过解码器深度关系并不是很大,都是84左右。如果只调最后一层的话,用深一点的会比较好。
解码器宽度(每个token表示成一个多长的向量):512比较好。
编码器中要不要加入被盖住的那些块:不加入被盖住的那些块,精度反而更高一些,而且计算量更少,所以本文采用的非对称的架构。
重建目标对比:fine-tune的值是差不多的,所以在值差不多的情况下,当然是倾向于使用更简单的办法
- 第一行:MAE现行做法
- 第二行:预测时对每个patch内部做normalization,效果最好。
- 第三行:PCA降维
- 第四行:BEiT的做法,通过vit把每一块映射到一个离散的token上面再做预测。
数据增强方法:one表示什么都不做,第二行表示只裁剪(固定大小),第三行表示按照随机的大小裁剪,最后一行表示再加上一些颜色的变化。从表中可以发现,做简单的随即大小的裁剪,效果就已经很不错了,所以作者说MAE对于数据的增强不那么敏感。
采样策略。随机采样,按块采样,按网格采样。发现随机采样这种做法最简单,效果也最好 。


掩码率:掩码率越大,不管是对fine-tune也好,还是对于只调最后一层来讲也好,效果都是比较好的。特别是只调最后一层的话,对掩码率相对来讲更加敏感一点

训练时间:使用vit-large而且解码器只使用一层transformer块的时候,精度也是不错的,时间是最小的,和第一行(使用所有的带掩码的块)相比,加速是3.7倍。如果是vit-huge的话,加速时间也是比较多的。

预训练的轮数:在ImageNet-1k上训练1000个数据轮的话,能够看到精度的提升,这也是一个非常不错的性质,说明在一直训练的情况下,过拟合也不是特别严重(1000轮其实是非常多的,一般在ImageNet上训练200轮就差不多了)

(三)MAE与之前工作的对比
基本上MAE的效果是最好的:

MAE基本只需要微调最后4层就可以了。这表示底部层学到的东西稍微是比较低层次一点,在换另外一个任务的时候也不需要变化太多,但是上面的层还是和任务比较相关的,最好还是做一些调整。

(四)迁移学习的效果
COCO数据集上的目标检测结果:用MAE当作主干网络之后效果是最好的

COCO数据集上的语义分割结果:用MAE当作主干网络之后效果是最好的

五、总结
MAE的算法就是利用vit来做和BERT一样的自监督学习,其在vit基础之上提出了几点:
- 盖住更多的块,使得剩下的那些块,块与块之间的冗余度没有那么高,这样整个任务就变得复杂一点
- 使用一个transformer架构的解码器,直接还原原始的像素信息,使得整个流程更加简单一点
- 加上vit工作之后的各种技术,使得它的训练更加鲁棒一点
以上三点加起来,使得MAE能够在ImageNet-1k数据集上使用自监督训练的效果超过了之前的工作。
参考:
MAE 论文逐段精读【论文精读】
李沐精读论文:MAE 《Masked Autoencoders Are Scalable Vision Learners》























![[BJDCTF2020]Easy MD5 1](https://img-blog.csdnimg.cn/direct/6c0f1c6b3d784337956f2736fb2a1540.png)