大数定律与中心极限定理
大数定律描述了独立同分布随机变量序列的算术平均值依概率收敛到分布的数学期望;中心极限定理描述了独立同分布随机变量序列之和的分布逼近于正分布。在很多场合中都能见到被冠以“大数定律”和“中心极限定理”的各类结论。
大数定律
在随机事件的大量重复出现中,往往呈现几乎必然的规律,这个规律就是大数定律。通俗地说,这个定理就是,在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。偶然中包含着某种必然。
我们知道,大数定律研究的是随机现象统计规律性的一类定理,当我们大量重复某一相同的实验的时候,其最后的实验结果可能会稳定在某一数值附近。就像抛硬币一样,当我们不断地抛,抛个上千次,甚至上万次,我们会发现,正面或者反面向上的次数都会接近一半。除了抛硬币,现实中还有许许多多这样的例子,像掷骰子,最著名的实验就是蒲丰投针实验。这些实验都像我们传达了一个共同的信息,那就是大量重复实验最终的结果都会比较稳定。那稳定性到底是什么?怎样去用数学语言把它表达出来?这其中会不会有某种规律性?是必然的还是偶然的?这一系列问题其实就是大数定律要研究的问题。
切比雪夫不等式
切比雪夫不等式可以对随机变量偏离期望值的概率做出估计,这是大数定律的推理基础。设随机变量X的数学期望E(x)和方差D(x)都存在,则对任意的 ε > 0 \varepsilon>0 ε>0,总有
P ( ∣ X − E ( X ) ∣ ≥ ε ) ≤ D ( x ) ε 2 P(|X-E(X)| \geq \varepsilon) \leq \frac{D(x)}{\varepsilon^2} P(∣X−E(X)∣≥ε)≤ε2D(x)
切比雪夫不等式有时也可写成(由逆概率事件公式):
P ( ∣ X − E ( X ) ∣ < ε ) ≥ 1 − D ( x ) ε 2 P(|X-E(X)| < \varepsilon) \geq 1-\frac{D(x)}{\varepsilon^2} P(∣X−E(X)∣<ε)≥1−ε2D(x)
证明: 只证明连续随机变量的情形。设X的概率密度为f(x),则有
P ( ∣ X − E ( X ) ∣ ≥ ε ) = ∫ ∣ X − E ( X ) ∣ ≥ ε f ( x ) d x ≤ ∫ ∣ X − E ( X ) ∣ ≥ ε ∣ X − E ( X ) ∣ 2 ε 2 f ( x ) d x ≤ 1 ε 2 ∫ − ∞ ∞ ( X − E ( X ) ) 2 f ( x ) d x ≤ D ( x ) ε 2 \begin{equation}\begin{split} P(|X-E(X)| \geq \varepsilon) &= \int_{|X-E(X)| \geq \varepsilon} f(x)\text{d} x \\ & \leq \int_{|X-E(X)| \geq \varepsilon} \frac{|X-E(X)|^2}{\varepsilon^2} f(x)\text{d} x\\ & \leq \frac{1}{\varepsilon^2}\int_{-\infty}^{\infty} {(X-E(X))^2} f(x)\text{d} x\\ & \leq \frac{D(x)}{\varepsilon^2} \end{split}\end{equation} P(∣X−E(X)∣≥ε)=∫∣X−E(X)∣≥εf(x)dx≤∫∣X−E(X)∣≥εε2∣X−E(X)∣2f(x)dx≤ε21∫−∞∞(X−E(X))2f(x)dx≤ε2D(x)
切比雪夫不等式给出了当随机变量的分布未知,只知道数学期望E(x)和方差D(x)时,估计概率 P ( ∣ X − E ( X ) ∣ ≥ ε ) P(|X-E(X)| \geq \varepsilon) P(∣X−E(X)∣≥ε)的上界,这个估计是比较粗糙的。
【注】显然,如果已知随机变量的分布,则所求概率 P ( ∣ X − E ( X ) ∣ ≥ ε ) P(|X-E(X)| \geq \varepsilon) P(∣X−E(X)∣≥ε)可以明确地计算出来,也就没必要用切比雪夫不等式估计了,切比雪夫不等式只适用于分布未知的情形。
依概率收敛
设 X 1 , X 2 , X 1 , ⋯ , X n X_1, X_2, X_1, \cdots, X_n X1,X2,X1,⋯,Xn是一个随机变量序列(一系列随机变量),A是一个常数,如果对任意的 ε > 0 ε>0 ε>0,有
lim n → ∞ P ( ∣ X n − A ∣ < ε ) = 1 \lim_{n \rightarrow \infty} P(|X_n-A| < \varepsilon )= 1 n→∞limP(∣Xn−A∣<ε)=1
则称随机变量序列 X 1 , X 2 , X 1 , ⋯ , X n X_1, X_2, X_1, \cdots, X_n X1,X2,X1,⋯,Xn依概率收敛于常数A,也记作 X n → P A X_n {\rightarrow}^{P} A Xn→PA
切比雪夫大数定律
设 X 1 , X 2 , X 1 , ⋯ , X n X_1, X_2, X_1, \cdots, X_n X1,X2,X1,⋯,Xn是一个两两不相关的随机变量序列(相互独立),存在常熟 C C C,使 D ( X i ) ≤ C D(X_i)\leq C D(Xi)≤C,则对任意的 ε > 0 \varepsilon > 0 ε>0有
lim n → ∞ P ( ∣ 1 n ∑ i = 1 n X i − 1 n ∑ i = 1 n E ( X i ) ∣ ≤ ε ) = 1 \lim_{n \rightarrow \infty} P \left( |\frac{1}{n} \sum_{i=1}^nX_i-\frac{1}{n} \sum_{i=1}^n E(X_i)| \leq \varepsilon\right) = 1 n→∞limP(∣n1i=1∑nXi−n1i=1∑nE(Xi)∣≤ε)=1
将该公式应用于抽样调查,就会有如下结论:随着样本容量 n n n的增加,样本平均数将接近于总体平均数。从而为统计推断中依据样本平均数估计总体平均数提供了理论依据。
特别需要注意的是,切比雪夫大数定理并未要求 X 1 , X 2 , X 1 , ⋯ , X n X_1, X_2, X_1, \cdots, X_n X1,X2,X1,⋯,Xn同分布,相较于伯努利大数定律和辛钦大数定律更具一般性。
辛钦大数定律
设 X 1 , X 2 , X 1 , ⋯ , X n X_1, X_2, X_1, \cdots, X_n X1,X2,X1,⋯,Xn是独立同分布的随机变量序列,具有数学期望 E X i = μ \mathbb{E} X_i= \mu EXi=μ,则对任意的 ε > 0 \varepsilon > 0 ε>0有
lim n → ∞ P ( ∣ 1 n ∑ i = 1 n X i − μ ∣ ≤ ε ) = 1 \lim_{n \rightarrow \infty} P \left( |\frac{1}{n} \sum_{i=1}^nX_i-\mu| \leq \varepsilon\right) = 1 n→∞limP(∣n1i=1∑nXi−μ∣≤ε)=1
伯努利大数定律
n n n重伯努利试验:
- 实验结果只有 A A A与 A ˉ \bar A Aˉ两种结果
- 每次试验 A A A发生的概率 P ( A ) P(A) P(A)保持不变
- 试验独立重复进行 n n n次
伯努利大数定律是辛钦大数定律的一个重要推论,设随机变量 X n ∼ B ( n , p ) X_n \sim B(n,p) Xn∼B(n,p),则对任意的 ε > 0 \varepsilon>0 ε>0有:
lim n → ∞ P ( ∣ X n n − p ∣ < ε ) = 1 \lim_{n \rightarrow \infty} P\left( | \frac{X_n}{n}-p| < \varepsilon\right)=1 n→∞limP(∣nXn−p∣<ε)=1
二项分布 X n ∼ B ( n , p ) X_n \sim B(n,p) Xn∼B(n,p)可以写成n个独立的符合0-1分布 B ( 1 , p ) B(1,p) B(1,p)的随机变量之和,即 X n = Y 1 + Y 2 + ⋯ + Y n X_n=Y_1+Y_2+\cdots+Y_n Xn=Y1+Y2+⋯+Yn,其中 Y 1 , Y 2 , ⋯ , Y n Y_1,Y_2,\cdots,Y_n Y1,Y2,⋯,Yn独立同分布, Y i ∼ B ( 1 , p ) Y_i \sim B(1,p) Yi∼B(1,p),又 E Y i = p EY_i=p EYi=p,则由辛钦大数定律可得
lim n → ∞ P ( ∣ 1 n ∑ i = 1 n Y i − p ∣ < ε ) = lim n → ∞ P ( ∣ X n n − p ∣ < ε ) = 1 \lim_{n \rightarrow \infty} P\left( | \frac{1}{n}\sum_{i=1}^nY_i-p| < \varepsilon\right)= \lim_{n \rightarrow \infty} P\left( | \frac{X_n}{n}-p| < \varepsilon\right)=1 n→∞limP(∣n1i=1∑nYi−p∣<ε)=n→∞limP(∣nXn−p∣<ε)=1
伯努利大数定律表明,只要试验次数足够多,事件 { ∣ X n n − p ∣ < ε } \{|\frac{X_n}{n}-p| < \varepsilon \} {∣nXn−p∣<ε}是一个小概率事件,而小概率事件在实际中是几乎不发生的,这就是频率稳定性的真正含义。在实际应用中,当试验次数很大时,就可以用事件的频率来代替事件的概率。
中心极限定理
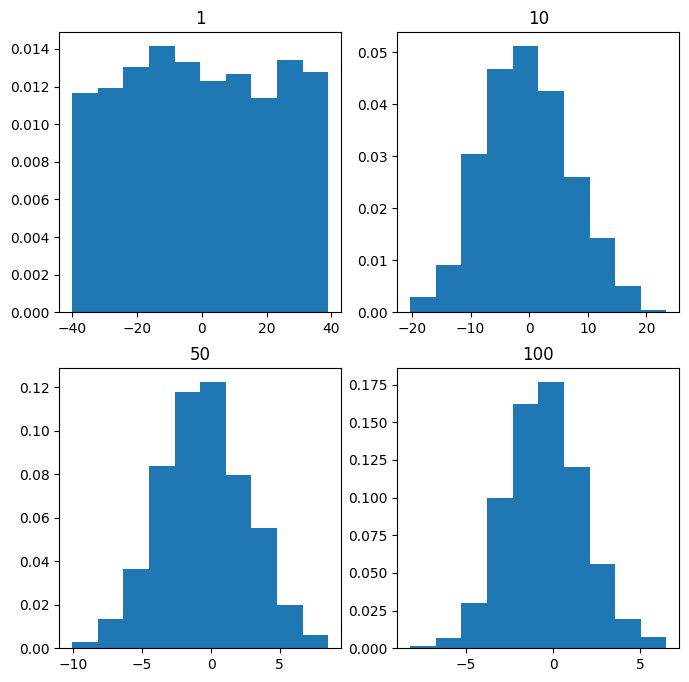
大数定律研究的是一系列随机变量 X n {X_n} Xn的均值 X ˉ n = 1 n ∑ i = 1 n X i \bar X_n=\frac{1}{n}\sum_{i=1}^nX_i Xˉn=n1∑i=1nXi是否会依概率收敛于其期望 E X ˉ n \mathbb{E} \bar X_n EXˉn这个数值,而中心极限定理进一步研究 X ˉ n \bar X_n Xˉn服从什么分布。若 X n {X_n} Xn满足一定的条件,当n足够大时, X ˉ n \bar X_n Xˉn近似服从正态分布,这就是中心极限定理的主要思想,这也体现了正态分布的要与普遍性。
在客观实际中有很多随机变量,它们是由大量的相互独立的随机因素综合作用而成,其中每个因素在总的影响中所起的作用都是微小的,这种随机变量往往近似地服从正态分布。此现象就是中心极限定理的客观背景。
列维-林德伯格中心极限定理(Lindeberg-Levy central limit theorem)
设 X 1 , X 2 , X 1 , ⋯ , X n X_1, X_2, X_1, \cdots, X_n X1,X2,X1,⋯,Xn独立同分布,存在数学期望 E ( X i ) = μ E(X_i)=\mu E(Xi)=μ和方差 D ( X i ) = σ 2 D(X_i)=\sigma^2 D(Xi)=σ2,则对于任意实数,有
lim n → ∞ P ( ∑ i = 1 n X i − n μ n σ ≤ x ) = 1 2 π ∫ − ∞ x e − t 2 2 d t = Φ ( x ) \lim_{n \rightarrow \infty }P \left( \frac{\sum_{i=1}^n X_i -n\mu}{\sqrt n \sigma} \leq x\right) = \frac{1}{\sqrt {2\pi}} \int_{-\infty}^xe^{-\frac{t^2}{2} \text{d} t}=\Phi(x) n→∞limP(nσ∑i=1nXi−nμ≤x)=2π1∫−∞xe−2t2dt=Φ(x)
中心极限定理表明,当n充分大时, ∑ i = 1 n X i \sum_{i=1}^n X_i ∑i=1nXi的标准化 ∑ i = 1 n X i − n μ n σ \frac{\sum_{i=1}^n X_i -n\mu}{\sqrt n \sigma} nσ∑i=1nXi−nμ近似服从正态分布 N ( 0 , 1 ) N(0,1) N(0,1),或者说 ∑ i = 1 n X i \sum_{i=1}^n X_i ∑i=1nXi近似服从 N ( n μ , n σ 2 ) N(n\mu,n\sigma^2) N(nμ,nσ2),即
P ( a < ∑ i = 1 n X i < b ) ≈ Φ ( b − n μ n σ ) − Φ ( a − n μ n σ ) P(a < \sum_{i=1}^n X_i <b) \approx \Phi( \frac{b-n\mu}{\sqrt n \sigma}) - \Phi( \frac{a-n\mu}{\sqrt n \sigma}) P(a<i=1∑nXi<b)≈Φ(nσb−nμ)−Φ(nσa−nμ)
中心极限定理是数理统计中大样本统计推断的基础。注意,定理中独立同分布、数学期望存在、方差存在三者缺一不可。只要问题涉及独立同分布随机变量的和 ∑ i = 1 n X i \sum_{i=1}^n X_i ∑i=1nXi,就可以考虑使用中心极限定理。
棣莫弗-拉普拉斯中心极限定理(De Moivre-Laplace central limit theorem)
棣莫弗-拉普拉斯中心极限定理是列维-林德伯格中心极限定理的重要推论。1733年,棣莫弗-拉普拉斯经过推理证明,得出了二项分布的极限分布是正态分布的结论,后来他又在原来的基础上做了改进,证明了不止二项分布满足这个条件,其他任何分布都是可以的,为中心极限定理的发展做出了伟大的贡献。
设随机变量 X n ∼ B ( n , p ) X_n \sim B(n,p) Xn∼B(n,p),则对任意的实数 x > 0 x>0 x>0有
lim n → ∞ P ( X n − n p n p ( 1 − p ) ≤ x ) = 1 2 π ∫ − ∞ x e − t 2 2 d t = Φ ( x ) \lim_{n \rightarrow \infty}P \left( \frac{X_n-np}{\sqrt{np(1-p)} } \leq x\right) = \frac{1}{\sqrt {2\pi}} \int_{-\infty}^xe^{-\frac{t^2}{2} \text{d} t}=\Phi(x) n→∞limP(np(1−p)Xn−np≤x)=2π1∫−∞xe−2t2dt=Φ(x)
证明: 二项分布 X n ∼ B ( n , p ) X_n \sim B(n,p) Xn∼B(n,p)可以写成n个独立的符合0-1分布 B ( 1 , p ) B(1,p) B(1,p)的随机变量之和,即 X n = Y 1 + Y 2 + ⋯ + Y n X_n=Y_1+Y_2+\cdots+Y_n Xn=Y1+Y2+⋯+Yn,其中 Y 1 , Y 2 , ⋯ , Y n Y_1,Y_2,\cdots,Y_n Y1,Y2,⋯,Yn独立同分布, Y i ∼ B ( 1 , p ) Y_i \sim B(1,p) Yi∼B(1,p),又 E Y i = p \text EY_i=p EYi=p, D Y i = p ( 1 − p ) \text DY_i=p(1-p) DYi=p(1−p),则由列维-林德伯格中心极限定理可得
lim n → ∞ P ( ∑ i = 1 n Y i − n p n p ( 1 − p ) ≤ x ) = lim n → ∞ P ( X n − n p n p ( 1 − p ) ≤ x ) = Φ ( x ) \lim_{n \rightarrow \infty}P \left( \frac{\sum_{i=1}^n Y_i-np}{\sqrt{np(1-p)}} \leq x\right) = \lim_{n \rightarrow \infty}P\left( \frac{X_n-np}{\sqrt{np(1-p)}} \leq x\right)=\Phi(x) n→∞limP(np(1−p)∑i=1nYi−np≤x)=n→∞limP(np(1−p)Xn−np≤x)=Φ(x)
中心极限定理表明,当n充分大时, B ( n , p ) B(n,p) B(n,p)的随机变量 X n X_n Xn的标准化 X n − n p n p ( 1 − p ) \frac{X_n-np}{\sqrt{np(1-p)}} np(1−p)Xn−np近似服从标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1),或者说 X n X_n Xn近似服从 N ( n p , n p ( 1 − p ) ) N(np,np(1-p)) N(np,np(1−p))即
P ( a < X n < b ) ≈ Φ ( b − n p n p ( 1 − p ) ) − Φ ( a − n p n p ( 1 − p ) ) P(a <X_n <b) \approx \Phi( \frac{b-np}{\sqrt {np(1-p)} }) - \Phi( \frac{a-np}{\sqrt {np(1-p)}}) P(a<Xn<b)≈Φ(np(1−p)b−np)−Φ(np(1−p)a−np)
在这之后大数定律的发展出现了停滞。直到20世纪,李雅普诺夫又在拉普拉斯定理的基础上做了自己的创新,他得出了特征函数法,将大数定律的研究延伸到函数层面,这对中心极限定理的发展有着重要的意义。到1920年,数学家们开始探讨中心极限定理在什么条件下普遍成立,这才有了后来发表的林德伯格条件和费勒条件,这些成果对中心极限定理的发展都功不可没。
李雅普诺夫中心极限定理(Lyapunov’s central limit theorem)
the sum of multiple independent
random variables follows a normal distribution
设 X 1 , X 2 , X 1 , ⋯ , X n X_1, X_2, X_1, \cdots, X_n X1,X2,X1,⋯,Xn相互独立,存在数学期望 E ( X i ) = μ i E(X_i)=\mu_i E(Xi)=μi和方差 D ( X i ) = σ i 2 D(X_i)=\sigma_i^2 D(Xi)=σi2,则随机变量服从正态分布。
参考:
- 中心极限定理——概率论中最重要的结论之一
- 大数定律与中心极限定理
- 概率论复习笔记五——大数定律和中心极限定理
- 大数定律和中心极限定理(清华)
- 大数定律和中心极限定理(中国科学技术大学)
- https://baike.baidu.com/item/%E5%A4%A7%E6%95%B0%E5%AE%9A%E5%BE%8B/410082
- https://zhuanlan.zhihu.com/p/77312635
- https://blog.csdn.net/SpiritedAway1106/article/details/107954388
- https://blog.csdn.net/weixin_43287568/article/details/113596881
- https://www.zhihu.com/question/26854682