一、说明
在之前的博客中,我们研究了生成式预训练转换器的整个概述。现在让我们看看关于预训练、微调和不同用例应用的超级重要主题。
二、预备训练
预训练是关于在没有监督或显式监督的情况下,我们从大型未标记语料库中获得自述监督,其中每个下一个标记都是我们需要预测的标签。
在预三化期间,他们使用了:
批量大小 : 64
输入大小:(B,T,C) = (64, 512, 768),其中,T 是序列长度,C 是嵌入维度
优化:亚当与余弦学习速率调度器
策略:教师强迫(而不是自动回归训练)用于 qucker 和稳定收敛

三、为什么我们需要使用“教师”强迫?
在训练阶段,当权重在前几个时期几乎接近随机时,如果我们要求它生成一个标记,然后将该令牌作为输入,然后预测下一个标记,那么就会出现问题,因为这本身在它没有预测正确单词的地方并不敏锐和准确,然后这个错误将反向传播并产生错误结果。相反,正如我们所知道的序列的实际真实值一样,如果我们在每个正确的步骤(即教师强制)中输入正确的输入,然后对其进行训练——这样我们发送的是实际序列,而不是模型预测的中间输出。这将导致更快、更稳定的收敛——最初它需要这种训练帮助,在某个时候,如果我们愿意,我们可以删除这种训练方法。
现在让我们专注于微调。微调涉及针对各种下游任务调整模型(架构变化最小),例如,对于情感分析、问答、摘要、多个句子之间的句子关系等情况。
- 标记数据集 C 中的每个样本都由标记 x2、x2、.....xm 的序列组成,标签为 y
- 使用通过求解预训练目标学到的参数初始化参数
- 在输入端,根据下游任务的类型添加其他令牌。例如,分类任务的开始<>和结束 <e> 标记
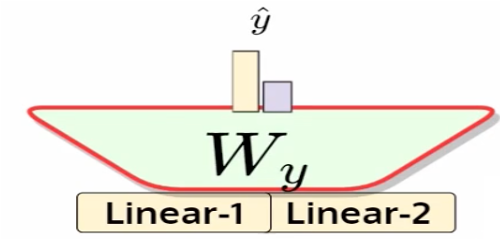
- 在输出侧,将预训练的LM头替换为分级头(线性层Wy)

看到所有先前标记的最终令牌(token)表示知道序列中的所有令牌,因为对于此令牌,此处没有应用掩码 - 无论我们在这里得到什么输出,我们都可以使用它来做出我们想要做出的预测。这个最终的令牌表示已经看到了整个文档,现在我们可以选择使用该表示,然后决定它是正面评论还是负面评论。最后一个标记的大小为 768 维,我们可以将其添加到 W 矩阵中并转换为指示 0/1 的一维输出。如果目标输出有 10 个类,那么它将转换为 10 维输出,当在此基础上应用 softmax 时,我们会得到哪个类具有最大概率的所需输出。
现在我们的目标是预测输入序列的标签。

这里层 l = 12 和 m = 第 512 个位置令牌
四、多种任务的对应方法
4.1 任务:情绪分析
考虑一下我们只有 5 个字的评论
发短信:哇,印度已经登月了
情绪:阳性
![]()
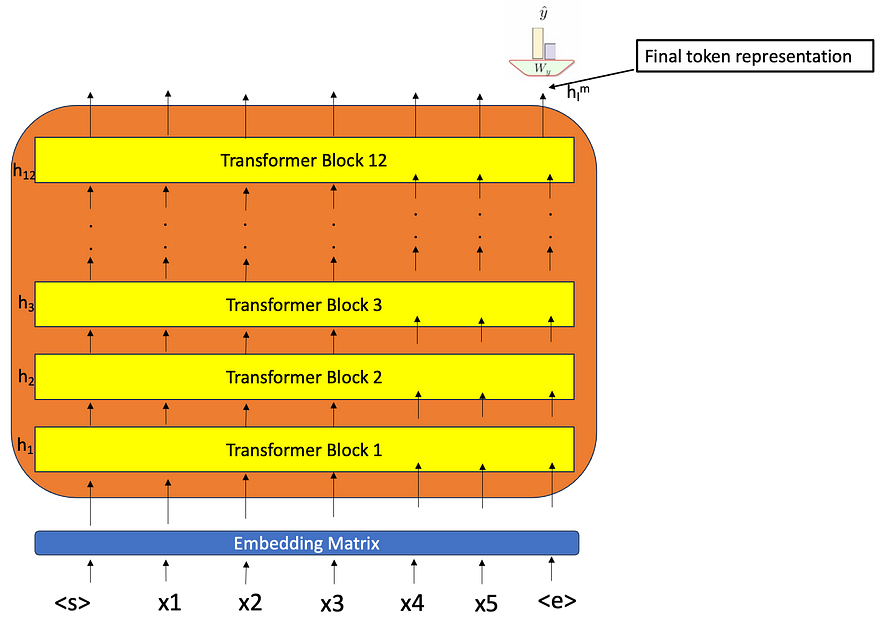
最后一步的输出将是 768 维,然后 Wy 将用 2 维向量转换输出——其中我们必须检查将最大化并返回传播的类和所有参数(注意力参数、FFN 参数等)。会随着变化而变化。
4.2 任务 : 文本蕴涵/矛盾
发短信:一个有多个男性玩的足球游戏
假设:有些男人正在参加一项运动
蕴涵:真
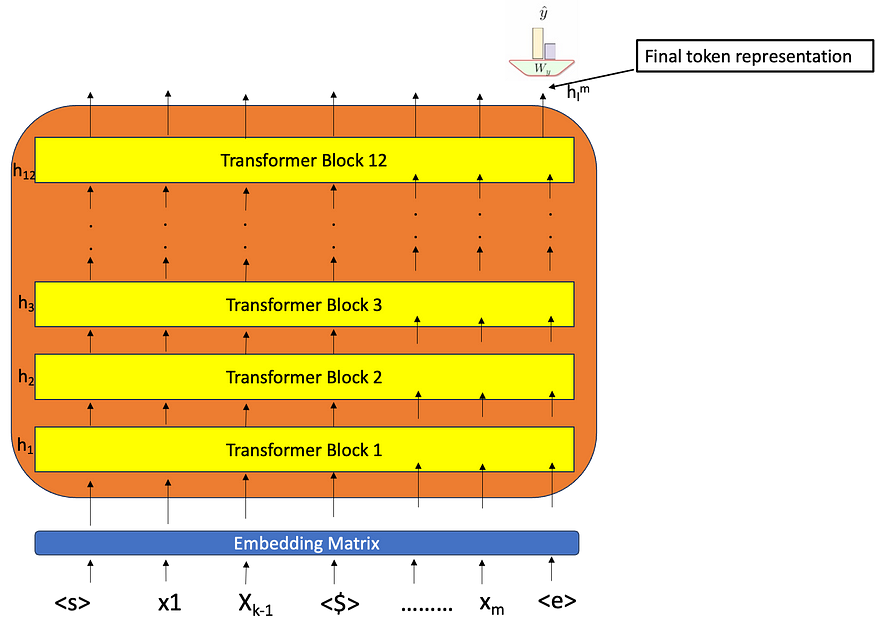
这里我们有 2 个带有文本和假设的输入——在这种情况下,我们需要使用分隔符标记 ($) 来区分文本和假设。假设如果我们这里有 3 个类(真/假/不能说)——我们将有 768 维输出——Wy 将接受这个 768 维输入并将其映射到 3 个类,并预测应用 softmax 后的概率分布。如果它将一个类作为输出,那么我们将把 -log(predicted) 类作为损失函数,并通过网络反向传播并微调所有参数。
为什么我们称它为微调?因为我们已经对网络进行了预训练,并且我们在特定配置下有称重,现在我们只是针对这个特定任务调整它们,而不是从随机初始化开始,然后尝试调整这个本来会训练的任务的所有权重,但这是一个微调,因为我们已经在一些配置中并尝试针对这个任务进行调整。
4.3 任务 : 多项选择
问题:以下哪种动物是两栖动物?
选择1:青蛙
选择-2:鱼
输入问题以及选项 1
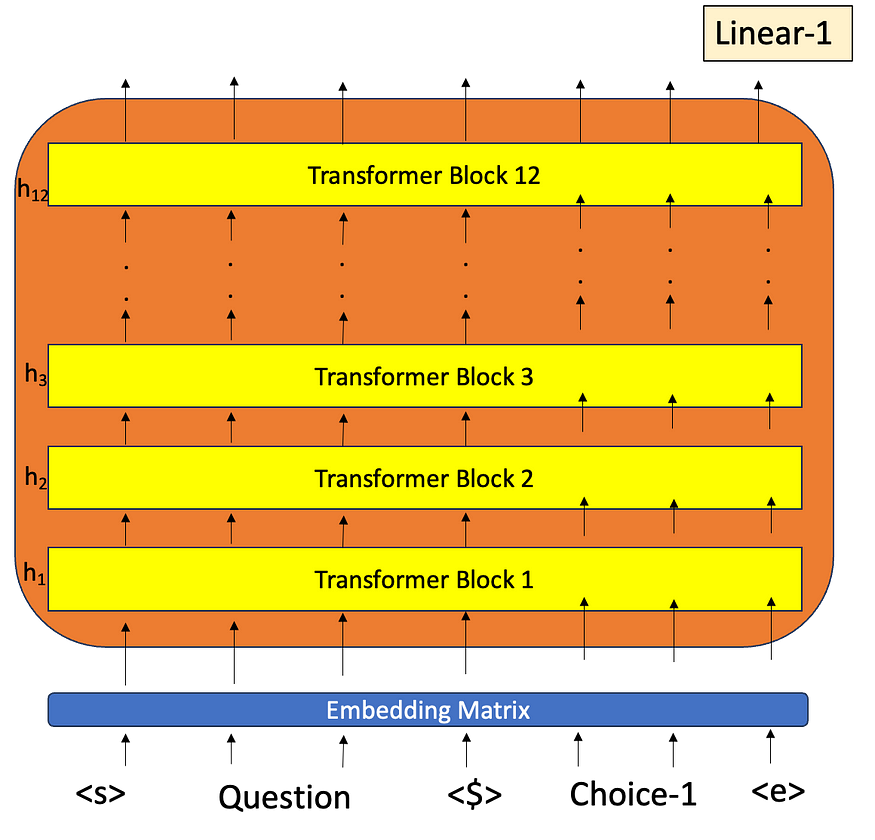
输入问题以及选项 2
对所有选项重复此操作

通过 softmax 规范化
无论哪个有正确的选择,我们都会反向传播并获得最大化的概率。
所有这些 NLP 任务都经过调整,其中网络在经过预训练后已经适应了这些任务。我们已经找到了合适的输入表示,在某些情况下,我们必须添加 $,并且我们还在输出中找到了合适的操作,这意味着我们忽略下一个标记预测,只添加一个层来预测这些任务所需的类。这就是微调中所做的。
4.4 文本生成
Input:
Prompt : I like

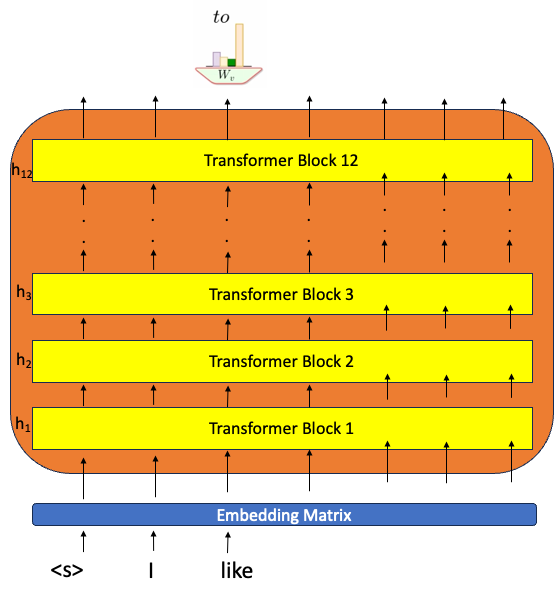
它是否为给定的提示生成相同的输出序列?
- 是的,它给出了相同的序列,因为它是确定性的——这不是一个有利的输出,因为每当我们开始一次又一次地编写相同的提示时,我们可能需要一些更有创意的输出。因此,为此,我们需要了解不同的解码策略,这将有助于通过使用相同的提示来产生一些不同的输出。
因此,文本生成案例的愿望清单是:
- 劝阻退化(即重复或不连贯)的文本
就像——我喜欢思考,我喜欢思考........
我喜欢认为参考知道如何思考畅销书
- 鼓励它创造性地为同一提示生成序列




























![[SWPU2019]Web4](https://img-blog.csdnimg.cn/img_convert/24bf6468f3e5c8edf04371d00a33be69.png)