布隆过滤器(Bloom Filter)介绍

布隆过滤器(Bloom Filter)是1970年由布隆提出来的,它是一种空间效率高、用于测试一个元素是否为某个集合成员的概率数据结构。
它可以准确判断元素“不在”集合中;如果判断元素“在”,则有一定的误判率。
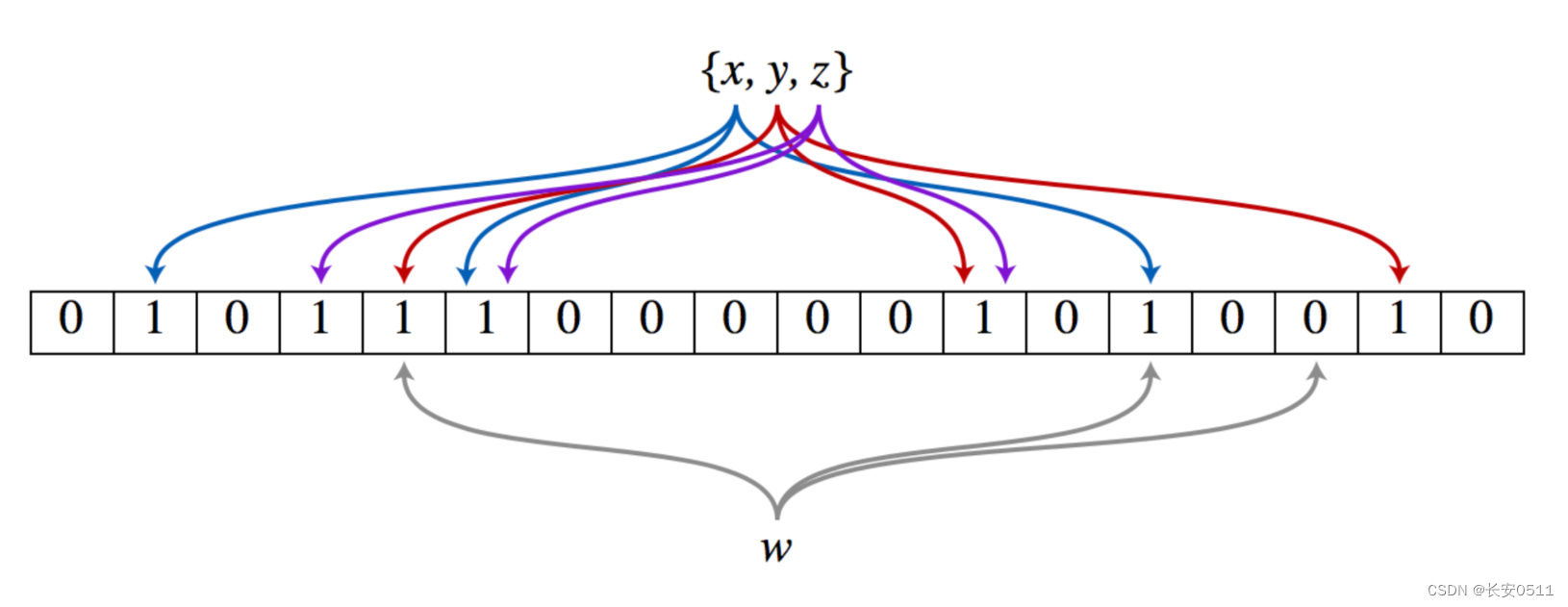
布隆过滤器使用多个哈希函数将每个元素映射到位数组中的多个点上,并在这些位置上放置标记(通常设置为1)。
优点:空间效率和查询时间都超过一般的列表和集合。
缺点:存在一定误判率,且原始数据的删除比较困难。
典型应用:网络浏览器的恶意网址检测、数据库快速查找、数据快速检索、分布式系统中的数据同步等领域。
应用场景
假设有10亿条手机号,然后判断某条手机号是否在列表内?
解决方案一:使用HashSet
HashSet 基于 HashMap 实现,可以提供接近 O(1) 的查找效率。但是要注意的是,10亿条手机号如果直接存储在内存里可能会消耗很大的内存空间,造成OOM。
解决方案二:使用Mysql
正常情况下,如果数据量不大,我们可以考虑使用mysql存储。将所有数据存储到数据库,然后每次去库里查询判断是否存在。但是如果数据量太大,超过千万,mysql查询效率是很低的,特别消耗性能。
解决方案三:使用布隆过滤器
- 插入和查询效率高,占用空间少,但是返回的结果是不确定的。
- 一个元素如果判断为存在的时候,它不一定真的存在。但是如果判断一个元素不存在,那么它一定是不存在的。(存在不一定存在,不存在一定不存在 true maybe not true, false if always false)
- 布隆过滤器可以添加元素,但是一定不能删除元素,会导致误判率增加。
布隆过滤器原理
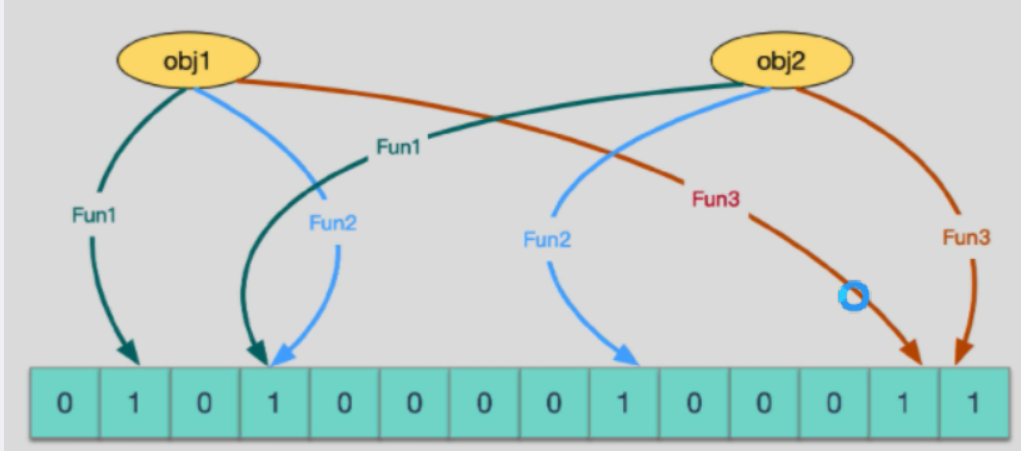
布隆过滤器其实就是是一个BIT数组,通过一系列hash算法映射出对应的hash,然后将hash对应的数组下标位置改为1。查询时就是对数据在进行一系列hash算法得到下标,从BIT数组里取数据如如果是1 则说明数据有可能存在,如果是0 说明一定不存在。
为什么会有误差率
我们知道布隆过滤器其实是对数据做hash,那么不管用什么算法,都有可能两条不同的数据生成的hash确是相同的,也就是我们常说的hash冲突。
Guava实现布隆过滤器
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
package your.package;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class BloomFilterExample {
public static void main(String[] args) {
// 创建一个预计存储1000个元素,误判率为0.01的布隆过滤器
BloomFilter<String> filter = BloomFilter.create(
Funnels.stringFunnel(Charset.defaultCharset()),
100000000,
0.01);
// 添加元素
filter.put("10086");
filter.put("10085");
filter.put("10084");
// 检查元素是否可能存在于过滤器中
System.out.println(filter.mightContain("10086")); // 输出: true
System.out.println(filter.mightContain("10085")); // 输出: true
System.out.println(filter.mightContain("10084")); // 输出: true
System.out.println(filter.mightContain("100")); // 输出: false(在没有误判的情况下)
}
}
总的来说,选择具体实现方案应该基于实际的数据量、硬件资源和性能需求等因素综合考虑。对于10亿条手机号的问题,通常需要结合内存和持久化存储来解决。例如,可以将全部号码存入数据库,再在内存中使用缓存技术如 BloomFilter 来提高读取效率。