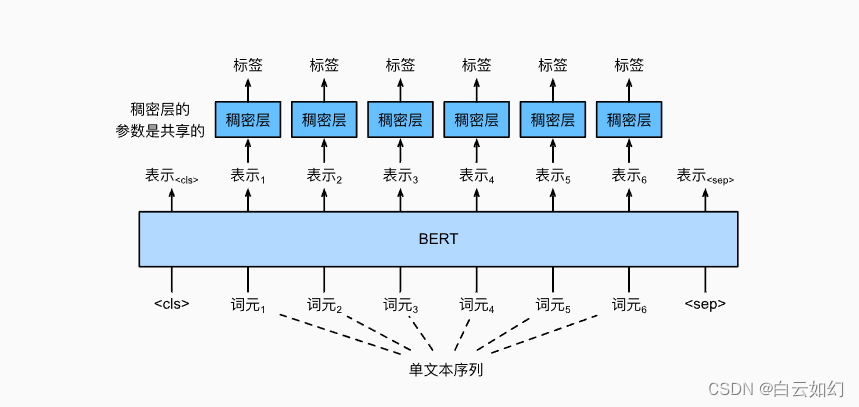
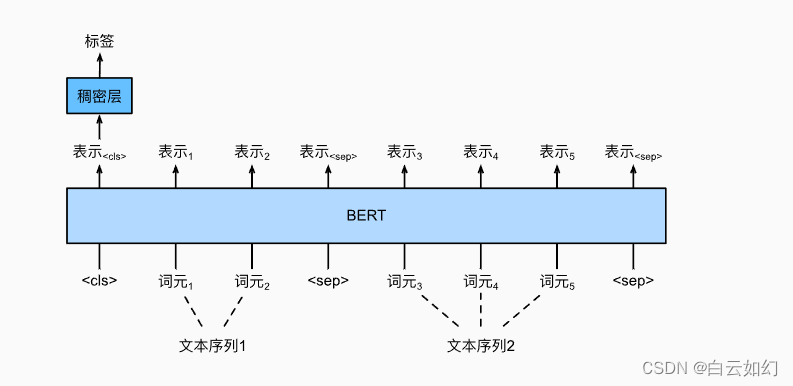
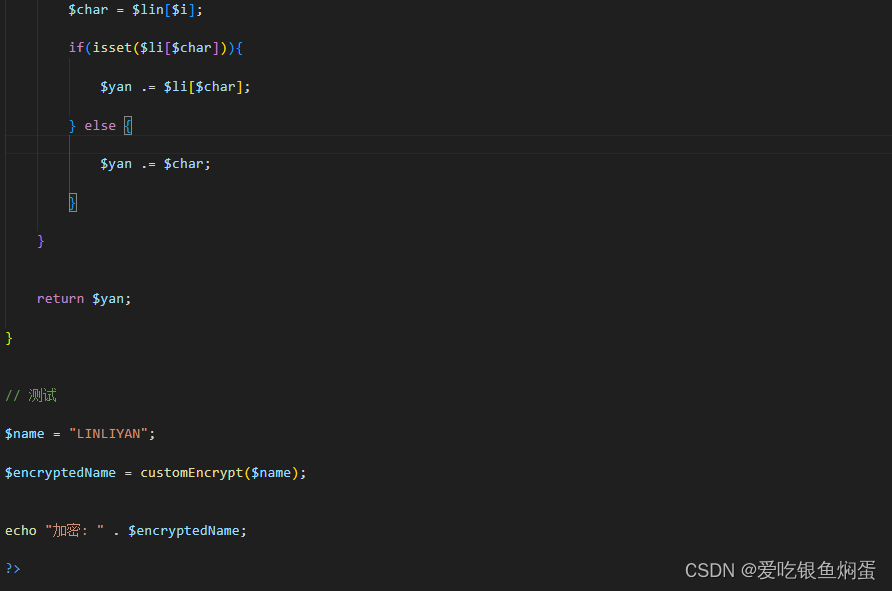
大语言模型分布式训练技术原理
- 开发
- 48
-
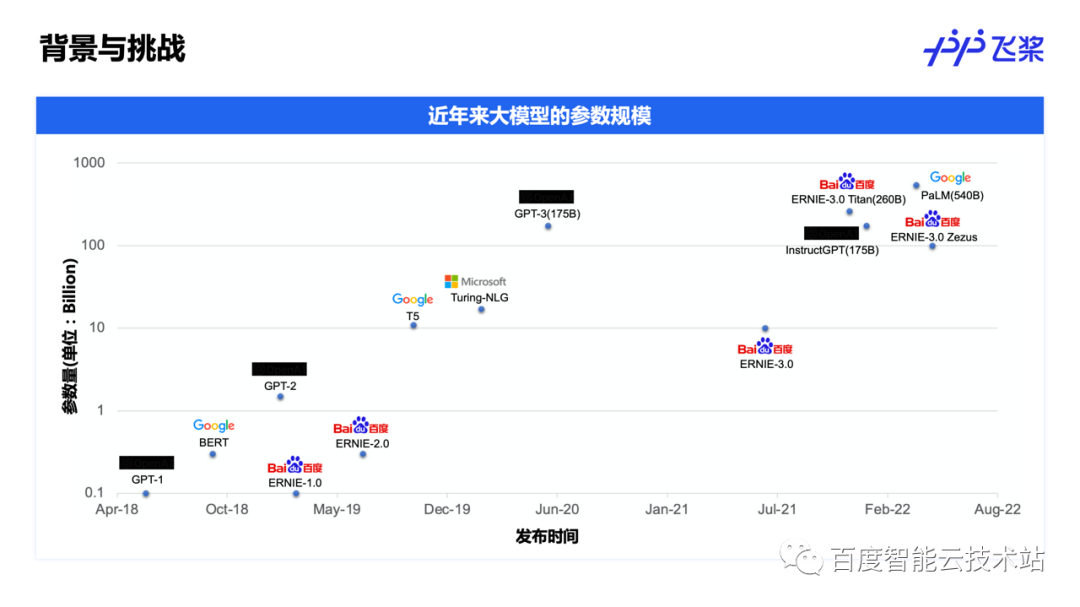
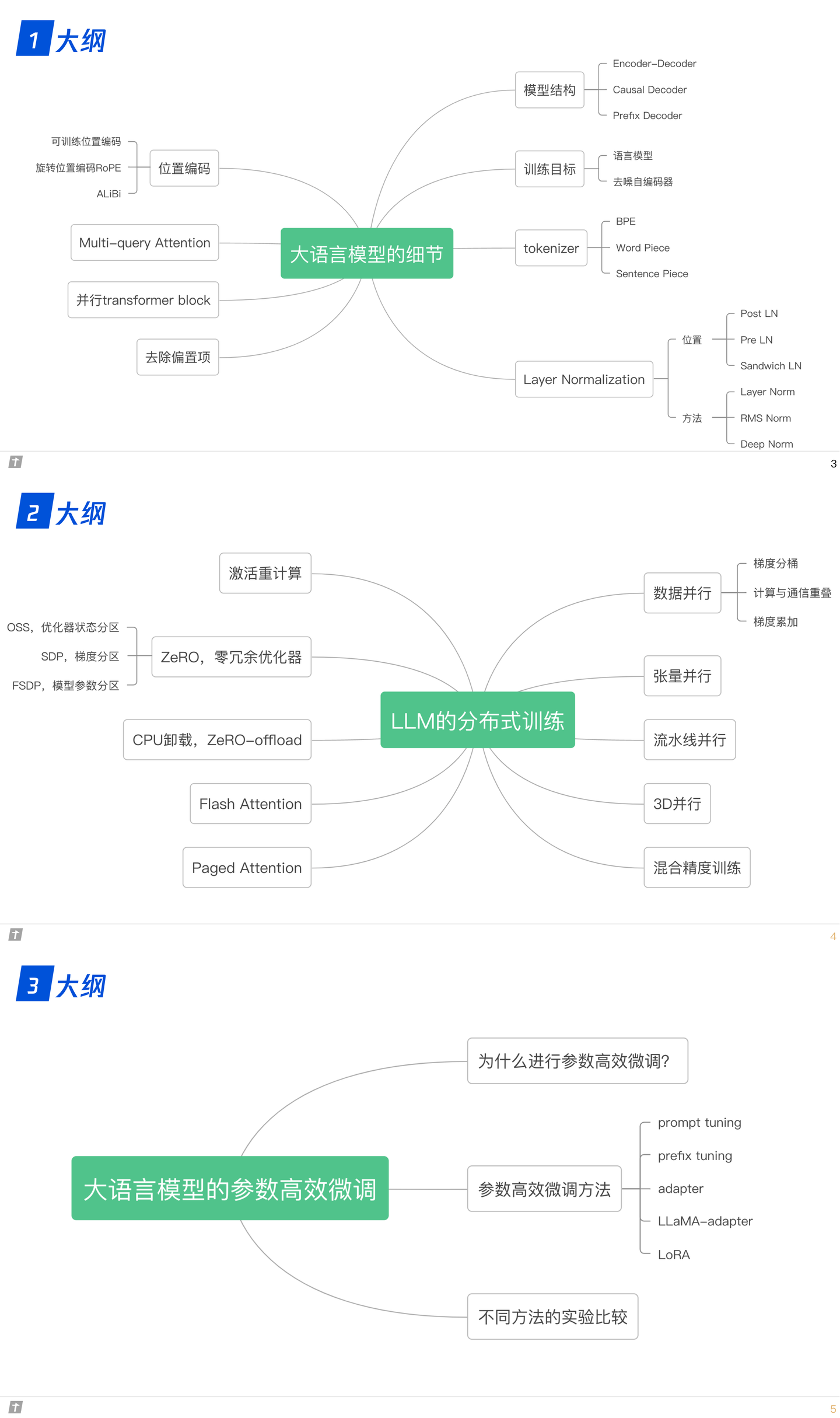
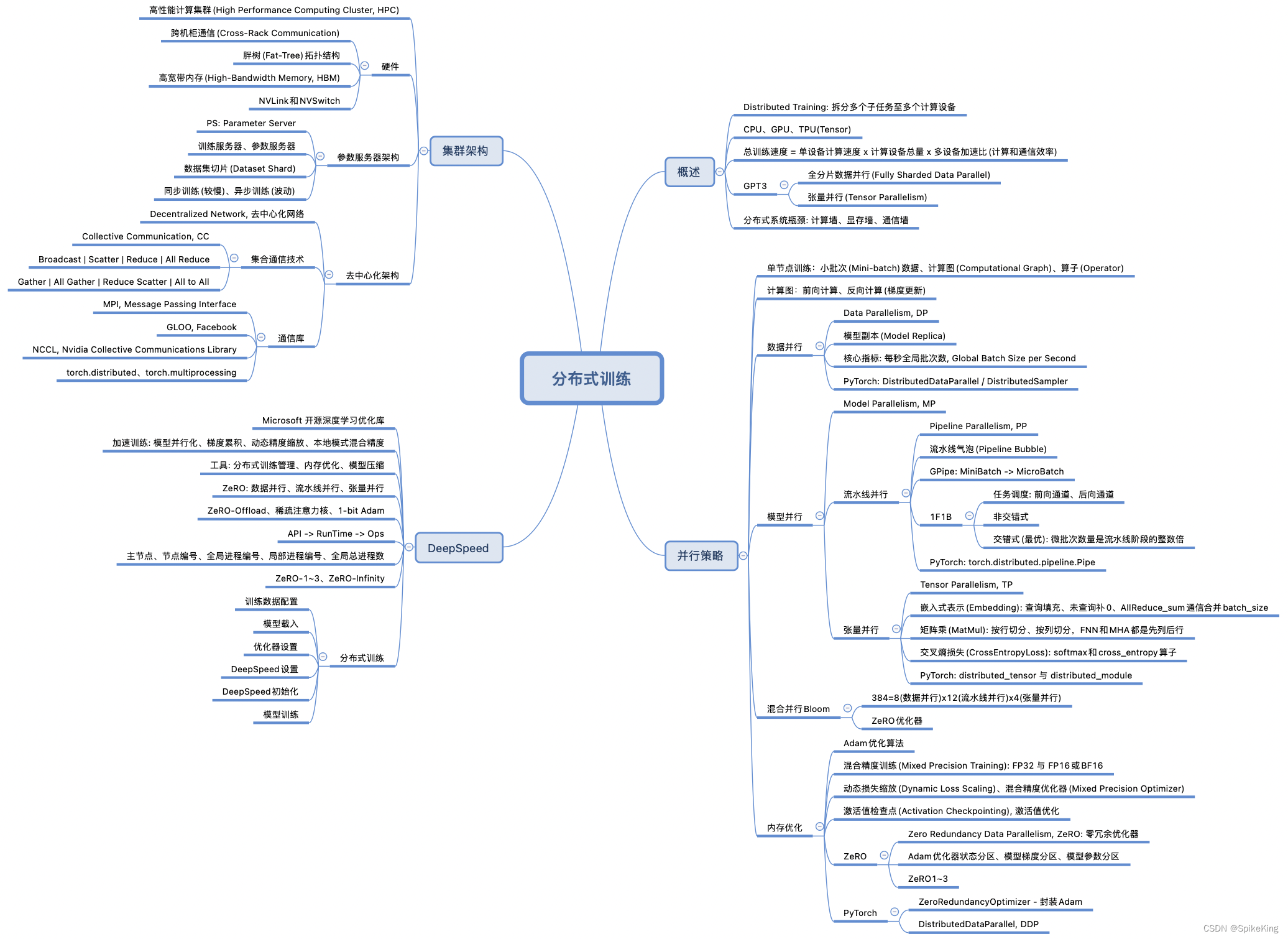
分布式训练技术原理
- 数据并行
- FSDP
- FSDP算法是由来自DeepSpeed的ZeroRedundancyOptimizer技术驱动的,但经过修改的设计和实现与PyTorch的其他组件保持一致。FSDP将模型实例分解为更小的单元,然后将每个单元内的所有参数扁平化和分片。分片参数在计算前按需通信和恢复,计算结束后立即丢弃。这种方法确保FSDP每次只需要实现一个单元的参数,这大大降低了峰值内存消耗。(数据并行+Parameter切分)
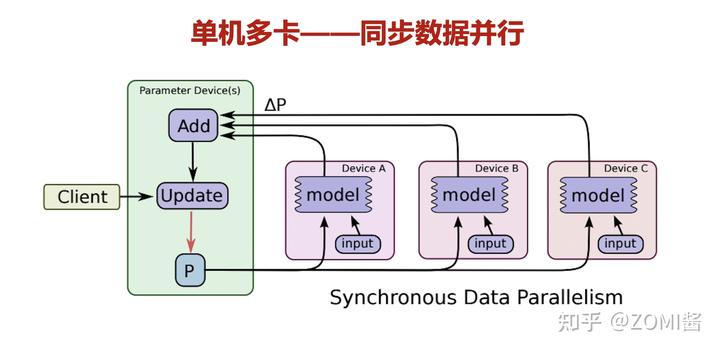
- DDP
- DistributedDataParallel (DDP), 在每个设备上维护一个模型副本,并通过向后传递的集体AllReduce操作同步梯度,从而确保在训练期间跨副本的模型一致性 。为了加快训练速度, DDP将梯度通信与向后计算重叠 ,促进在不同资源上并发执行工作负载。
- ZeRO
- Model state
- Optimizer->ZeRO1
- 将optimizer state分成若干份,每块GPU上各自维护一份
- 每块GPU上存一份完整的参数W,做完一轮foward和backward后,各得一份梯度,对梯度做一次 AllReduce(reduce-scatter + all-gather) , 得到完整的梯度G,由于每块GPU上只保管部分optimizer states,因此只能将相应的W进行更新,对W做一次All-Gather
- Gradient+Optimzer->ZeRO2
原文地址:https://blog.csdn.net/weixin_32393347/article/details/135859502
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1751003096219258880.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!