前言
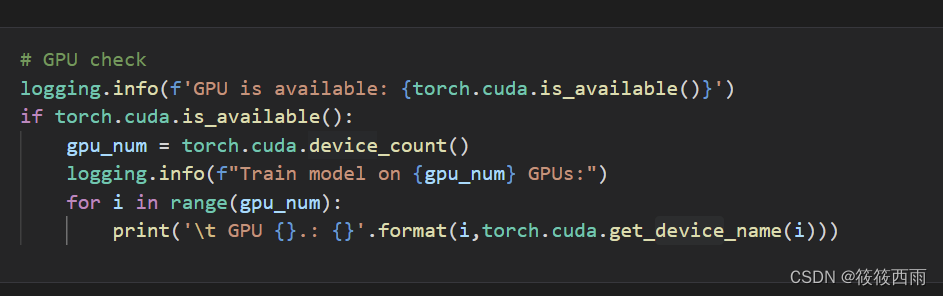
在训练模型和推理测试时,电脑中有多个显卡,需要指定某个GPU,以免出现显出不够问题。
查询显卡情况
使用下面的命令,查询显卡情况
nvidia-smi会看到显卡的ID号、温度、名称、电压、显存、使用情况等信息
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.161.07 Driver Version: 535.161.07 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A100-PCIE-40GB Off | 00000000:37:00.0 Off | 0 |
| N/A 29C P0 37W / 250W | 37150MiB / 40960MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-PCIE-40GB Off | 00000000:38:00.0 Off | 0 |
| N/A 30C P0 36W / 250W | 23586MiB / 40960MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 2 NVIDIA A100-PCIE-40GB Off | 00000000:3B:00.0 Off | 0 |
| N/A 75C P0 258W / 250W | 34304MiB / 40960MiB | 51% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 3 NVIDIA A100-PCIE-40GB Off | 00000000:40:00.0 Off | 0 |
| N/A 62C P0 78W / 250W | 25882MiB / 40960MiB | 76% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 4 NVIDIA A100-PCIE-40GB Off | 00000000:41:00.0 Off | 0 |
| N/A 63C P0 155W / 250W | 33552MiB / 40960MiB | 84% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 5 NVIDIA A100-PCIE-40GB Off | 00000000:44:00.0 Off | 0 |
| N/A 64C P0 108W / 250W | 13886MiB / 40960MiB | 88% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 6 NVIDIA A100-PCIE-40GB Off | 00000000:48:00.0 Off | 0 |
| N/A 62C P0 97W / 250W | 15434MiB / 40960MiB | 78% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 7 NVIDIA A100-PCIE-40GB Off | 00000000:50:00.0 Off | 0 |
| N/A 60C P0 106W / 250W | 29824MiB / 40960MiB | 79% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 819029 C python3 12352MiB |
| 0 N/A N/A 3848455 C python3 24784MiB |
| 2 N/A N/A 814833 C python 34296MiB |
| 3 N/A N/A 649616 C python 25874MiB |
方案1:在Python代码内设置环境变量
在Python代码内设置环境变量时,需要注意:环境变量设置,应该在PyTorch代码之前。
使用os.environ来设置CUDA_VISIBLE_DEVICES,如果是默认的第一张显卡, 对应显卡ID为0。
下面的示例是指定使用第二张显卡,对应显卡ID为1,对应nvidia-smi中查询的GPU Fan.
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1' # 指定只有第二张GPU对PyTorch可见
# PyTorch代码从这里开始
import torch
.......如果指定多张显卡,只需用逗号隔开,指定对应的显卡ID即可。
下面的示例是指定使用第一显卡和第三张下那块,对应ID为0和2。
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,2' # 指定第一张和第三张显卡
# PyTorch代码从这里开始
import torch
.......方案2:直接设置环境变量
在命令行中设置CUDA_VISIBLE_DEVICES环境变量,然后运行python代码。
这个环境变量控制着CUDA对程序可见的GPU。
例如,指定使用第二张显卡,对应显卡ID为1,在Linux或MacOS上使用以下命令:
export CUDA_VISIBLE_DEVICES=1
python your_code.py
在Windows上,使用以下命令:
set CUDA_VISIBLE_DEVICES=1
python your_code.py
如果指定多张显卡,只需用逗号隔开,指定对应的显卡ID即可。
下面的示例是指定三张显卡同时使用,对应显卡ID为0、1、2。
export CUDA_VISIBLE_DEVICES=0,1,2
python your_code.py
实践示例
通常在训练模型或模型测试,代码默认使用第一张显卡,GPU ID为0。
如果不指定指定其它GPU,可能出现显出不够问题。
这时可以参考上面的两种方案,来设置环境变量,指定代码运行使用那张显卡。
比如在训练代码中,运行python train.py,指定使用第2、3、4张显卡,对应显卡ID:1,2,3。
如果采用方案1,只需在train.py,最开头地方加入下面代码即可
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2,3' # 指定第二张、第三张和第四张显卡
# PyTorch代码从这里开始
import numpy as np
import sys
import logging
from time import time
from tensorboardX import SummaryWriter
import argparse
import kornia
import torch
from loss import SimpleLoss, DiscriminativeLoss
from data.dataset_front import semantic_dataset
from data.const import NUM_CLASSES
from evaluation.iou import get_batch_iou
from evaluation.angle_diff import calc_angle_diff
from model_front import get_model
from evaluate import onehot_encoding, eval_iou_2
import random
def write_log(writer, ious, title, counter):
writer.add_scalar(f'{title}/iou', torch.mean(ious[1:]), counter)
for i, iou in enumerate(ious):
writer.add_scalar(f'{title}/class_{i}/iou', iou, counter)
def train(args):
if not os.path.exists(args.logdir):
os.mkdir(args.logdir)
logging.basicConfig(filename=os.path.join(args.logdir, "results.log"),
filemode='w',
format='%(asctime)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
level=logging.INFO)
logging.getLogger('shapely.geos').setLevel(logging.CRITICAL)
logger = logging.getLogger()
logger.addHandler(logging.StreamHandler(sys.stdout))
data_conf = {
'num_channels': NUM_CLASSES + 1,
'image_size': args.image_size,
'depth_image_size': args.depth_image_size,
'xbound': args.xbound,
'ybound': args.ybound,
'zbound': args.zbound,
'dbound': args.dbound,
'zgrid': args.zgrid,
'thickness': args.thickness,
'angle_class': args.angle_class,
}
train_loader, val_loader = semantic_dataset(
args.version, args.dataroot, data_conf, args.bsz, args.nworkers, depth_downsample_factor=args.depth_downsample_factor, depth_sup=args.depth_sup, use_depth_enc=args.use_depth_enc, use_depth_enc_bin=args.use_depth_enc_bin, add_depth_channel=args.add_depth_channel,use_lidar_10=True,data_aug=args.data_aug,data_seed=args.data_seed)
model = get_model(args.model, data_conf, args.instance_seg, args.embedding_dim,
args.direction_pred, args.angle_class, downsample=args.depth_downsample_factor, use_depth_enc=args.use_depth_enc, pretrained=args.pretrained, add_depth_channel=args.add_depth_channel)
model.cuda()
opt = torch.optim.SGD(model.parameters(), lr=args.lr,
momentum=0.9, dampening=0.9,
weight_decay=args.weight_decay)
if args.resumef:
print("Resuming from ", args.resumef)
checkpoint = torch.load(args.resumef)
starting_epoch = checkpoint['epoch']+1
model.load_state_dict(checkpoint['state_dict'])
opt.load_state_dict(checkpoint['optimizer'])
else:
print("Training From Scratch ..." )
starting_epoch = 0
print("starting_epoch: ", starting_epoch)
writer = SummaryWriter(logdir=args.logdir)
loss_fn = SimpleLoss(args.pos_weight).cuda()
embedded_loss_fn = DiscriminativeLoss(
args.embedding_dim, args.delta_v, args.delta_d).cuda()
direction_loss_fn = torch.nn.BCELoss(reduction='none')
depth_loss_func = kornia.losses.FocalLoss(alpha=0.25, gamma=2.0, reduction="mean")
model.train()
counter = 0
last_idx = len(train_loader) - 1
for epoch in range(starting_epoch, args.nepochs):
model.train()
for batchi, (imgs, trans, rots, intrins, post_trans, post_rots, lidar_data, lidar_mask, car_trans,
yaw_pitch_roll, semantic_gt, instance_gt, direction_gt, final_depth_map, final_depth_map_bin_enc, projected_depth) in enumerate(train_loader):
t0 = time()
opt.zero_grad()
semantic, embedding, direction, depth = model(imgs.cuda(), trans.cuda(), rots.cuda(), intrins.cuda(),
post_trans.cuda(), post_rots.cuda(), lidar_data.cuda(),
lidar_mask.cuda(), car_trans.cuda(), yaw_pitch_roll.cuda(), final_depth_map_bin_enc.cuda(), projected_depth.cuda())
semantic_gt = semantic_gt.cuda().float()
instance_gt = instance_gt.cuda()
if args.depth_sup:
final_depth_map = final_depth_map.cuda()
seg_loss = loss_fn(semantic, semantic_gt)
if args.instance_seg:
var_loss, dist_loss, reg_loss = embedded_loss_fn(
embedding, instance_gt)
else:
var_loss = 0
dist_loss = 0
reg_loss = 0
if args.direction_pred:
direction_gt = direction_gt.cuda()
lane_mask = (1 - direction_gt[:, 0]).unsqueeze(1)
direction_loss = direction_loss_fn(
torch.softmax(direction, 1), direction_gt)
direction_loss = (direction_loss * lane_mask).sum() / \
(lane_mask.sum() * direction_loss.shape[1] + 1e-6)
angle_diff = calc_angle_diff(
direction, direction_gt, args.angle_class)
else:
direction_loss = 0
angle_diff = 0
if args.depth_sup:
depth_loss = depth_loss_func(depth, final_depth_map)
else:
depth_loss = 0
final_loss = seg_loss * args.scale_seg + var_loss * args.scale_var + \
dist_loss * args.scale_dist + direction_loss * args.scale_direction + depth_loss*args.scale_depth
final_loss.backward()
torch.nn.utils.clip_grad_norm_(
model.parameters(), args.max_grad_norm)
opt.step()
counter += 1
t1 = time()
if counter % 10 == 0:
intersects, union = get_batch_iou(
onehot_encoding(semantic), semantic_gt)
iou = intersects / (union + 1e-7)
logger.info(f"TRAIN[{epoch:>3d}]: [{batchi:>4d}/{last_idx}] "
f"Time: {t1-t0:>7.4f} "
f"Loss: {final_loss.item():>7.4f} "
f"IOU: {np.array2string(iou[1:].numpy(), precision=3, floatmode='fixed')}")
write_log(writer, iou, 'train', counter)
writer.add_scalar('train/step_time', t1 - t0, counter)
writer.add_scalar('train/seg_loss', seg_loss, counter)
writer.add_scalar('train/var_loss', var_loss, counter)
writer.add_scalar('train/dist_loss', dist_loss, counter)
writer.add_scalar('train/reg_loss', reg_loss, counter)
writer.add_scalar('train/direction_loss',
direction_loss, counter)
writer.add_scalar('train/final_loss', final_loss, counter)
writer.add_scalar('train/angle_diff', angle_diff, counter)
iou = eval_iou_2(model, val_loader)
logger.info(f"EVAL[{epoch:>2d}]: "
f"IOU: {np.array2string(iou[1:].numpy(), precision=3, floatmode='fixed')}")
write_log(writer, iou, 'eval', counter)
model_name = os.path.join(args.logdir, f"model.pt")
state = {
'epoch': epoch,
'state_dict': model.state_dict(),
'optimizer': opt.state_dict(),
}
torch.save(state, model_name)
logger.info(f"{model_name} saved")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='SuperFusion training.')
# logging config
parser.add_argument("--logdir", type=str, default='./runs')
# nuScenes config
parser.add_argument('--dataroot', type=str, default='/path/to/nuScenes/')
parser.add_argument('--version', type=str, default='v1.0-trainval',
choices=['v1.0-trainval', 'v1.0-mini'])
# model config
parser.add_argument("--model", type=str, default='SuperFusion')
# training config
parser.add_argument("--nepochs", type=int, default=30)
parser.add_argument("--max_grad_norm", type=float, default=5.0)
parser.add_argument("--pos_weight", type=float, default=2.13)
parser.add_argument("--bsz", type=int, default=4)
parser.add_argument("--nworkers", type=int, default=10)
parser.add_argument("--lr", type=float, default=0.1)
parser.add_argument("--lr_gamma", type=float, default=0.1)
parser.add_argument("--weight_decay", type=float, default=1e-7)
# finetune config
parser.add_argument('--finetune', action='store_true')
parser.add_argument('--modelf', type=str, default=None)
# data config
parser.add_argument("--thickness", type=int, default=5)
parser.add_argument("--depth_downsample_factor", type=int, default=4)
parser.add_argument("--image_size", nargs=2, type=int, default=[256, 704])
parser.add_argument("--depth_image_size", nargs=2, type=int, default=[256, 704])
parser.add_argument("--xbound", nargs=3, type=float,
default=[-90.0, 90.0, 0.15])
parser.add_argument("--ybound", nargs=3, type=float,
default=[-15.0, 15.0, 0.15])
parser.add_argument("--zbound", nargs=3, type=float,
default=[-10.0, 10.0, 20.0])
parser.add_argument("--zgrid", nargs=3, type=float,
default=[-3.0, 1.5, 0.15])
parser.add_argument("--dbound", nargs=3, type=float,
default=[2.0, 90.0, 1.0])
# embedding config
parser.add_argument('--instance_seg', action='store_true')
parser.add_argument("--embedding_dim", type=int, default=16)
parser.add_argument("--delta_v", type=float, default=0.5)
parser.add_argument("--delta_d", type=float, default=3.0)
# direction config
parser.add_argument('--direction_pred', action='store_true')
parser.add_argument('--angle_class', type=int, default=36)
# depth config
parser.add_argument('--depth_sup', action='store_true')
# loss config
parser.add_argument("--scale_seg", type=float, default=1.0)
parser.add_argument("--scale_var", type=float, default=1.0)
parser.add_argument("--scale_dist", type=float, default=1.0)
parser.add_argument("--scale_direction", type=float, default=0.2)
parser.add_argument("--scale_depth", type=float, default=1.0)
parser.add_argument("--opt", type=str, default='sgd')
parser.add_argument('--use_depth_enc', action='store_true')
parser.add_argument('--pretrained', action='store_true')
parser.add_argument('--use_depth_enc_bin', action='store_true')
parser.add_argument('--add_depth_channel', action='store_true')
parser.add_argument('--data_aug', action='store_true')
parser.add_argument('--data_seed', action='store_true')
parser.add_argument('--resumef', type=str, default=None)
args = parser.parse_args()
random.seed(0)
torch.manual_seed(0)
np.random.seed(0)
torch.cuda.manual_seed(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
train(args)
在模型推理和测试时,运行python test.py,指定使用第2张显卡,对应显卡ID:1。
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1' # 指定第二张显卡
import argparse
import tqdm
import torch
from data.dataset_front import semantic_dataset
from data.const import NUM_CLASSES
from model_front import get_model
def onehot_encoding(logits, dim=1):
max_idx = torch.argmax(logits, dim, keepdim=True)
one_hot = logits.new_full(logits.shape, 0)
one_hot.scatter_(dim, max_idx, 1)
return one_hot
def get_batch_iou(pred_map, gt_map):
intersects = []
unions = []
with torch.no_grad():
pred_map = pred_map.bool()
gt_map = gt_map.bool()
for i in range(pred_map.shape[1]):
pred = pred_map[:, i]
tgt = gt_map[:, i]
intersect = (pred & tgt).sum().float()
union = (pred | tgt).sum().float()
intersects.append(intersect)
unions.append(union)
return torch.tensor(intersects), torch.tensor(unions)
def eval_iou(model, val_loader):
model.eval()
total_intersects = 0
total_union = 0
total_intersects_split_30_60 = 0
total_union_split_30_60 = 0
total_intersects_split_60_90 = 0
total_union_split_60_90 = 0
with torch.no_grad():
for imgs, trans, rots, intrins, post_trans, post_rots, lidar_data, lidar_mask, car_trans, yaw_pitch_roll, semantic_gt, instance_gt, direction_gt, final_depth_map, final_depth_map_bin_enc, projected_depth in tqdm.tqdm(val_loader):
semantic, embedding, direction, _ = model(imgs.cuda(), trans.cuda(), rots.cuda(), intrins.cuda(),
post_trans.cuda(), post_rots.cuda(), lidar_data.cuda(),
lidar_mask.cuda(), car_trans.cuda(), yaw_pitch_roll.cuda(), final_depth_map_bin_enc.cuda(), projected_depth.cuda())
semantic_gt = semantic_gt.cuda().float()
split = int(semantic_gt.shape[3]/3)
intersects, union = get_batch_iou(
onehot_encoding(semantic[:,:,:,:split]), semantic_gt[:,:,:,:split])
total_intersects += intersects
total_union += union
intersects, union = get_batch_iou(
onehot_encoding(semantic[:,:,:,split:2*split]), semantic_gt[:,:,:,split:2*split])
total_intersects_split_30_60 += intersects
total_union_split_30_60 += union
intersects, union = get_batch_iou(
onehot_encoding(semantic[:,:,:,2*split:]), semantic_gt[:,:,:,2*split:])
total_intersects_split_60_90 += intersects
total_union_split_60_90 += union
return total_intersects / (total_union + 1e-7), total_intersects_split_30_60 / (total_union_split_30_60 + 1e-7), total_intersects_split_60_90 / (total_union_split_60_90 + 1e-7)
def main(args):
data_conf = {
'num_channels': NUM_CLASSES + 1,
'image_size': args.image_size,
'xbound': args.xbound,
'ybound': args.ybound,
'zbound': args.zbound,
'dbound': args.dbound,
'thickness': args.thickness,
'angle_class': args.angle_class,
'depth_image_size': args.depth_image_size,
}
train_loader, val_loader = semantic_dataset(
args.version, args.dataroot, data_conf, args.bsz, args.nworkers, depth_downsample_factor=args.depth_downsample_factor, depth_sup=args.depth_sup, use_depth_enc=args.use_depth_enc, use_depth_enc_bin=args.use_depth_enc_bin, add_depth_channel=args.add_depth_channel,use_lidar_10=args.use_lidar_10)
model = get_model(args.model, data_conf, args.instance_seg, args.embedding_dim,
args.direction_pred, args.angle_class, downsample=args.depth_downsample_factor, use_depth_enc=args.use_depth_enc, pretrained=args.pretrained, add_depth_channel=args.add_depth_channel,add_fuser=args.add_fuser)
if args.model == 'HDMapNet_fusion' or args.model == 'HDMapNet_cam':
model.load_state_dict(torch.load(args.modelf), strict=False)
else:
checkpoint = torch.load(args.modelf)
model.load_state_dict(checkpoint['state_dict'])
model.cuda()
iou_front, iou_back, iou_60_90 = eval_iou(model, val_loader)
print("iou_0_30: ", iou_front)
print("iou_30_60: ", iou_back)
print("iou_60_90: ", iou_60_90)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# nuScenes config
parser.add_argument('--dataroot', type=str,
default='/path/to/nuScenes/')
parser.add_argument('--version', type=str, default='v1.0-trainval',
choices=['v1.0-trainval', 'v1.0-mini'])
# model config
parser.add_argument("--model", type=str, default='SuperFusion')
# training config
parser.add_argument("--bsz", type=int, default=4)
parser.add_argument("--nworkers", type=int, default=10)
parser.add_argument('--modelf', type=str, default=None)
# data config
parser.add_argument("--thickness", type=int, default=5)
parser.add_argument("--image_size", nargs=2, type=int, default=[256, 704])
parser.add_argument("--xbound", nargs=3, type=float,
default=[-90.0, 90.0, 0.15])
parser.add_argument("--ybound", nargs=3, type=float,
default=[-15.0, 15.0, 0.15])
parser.add_argument("--zbound", nargs=3, type=float,
default=[-10.0, 10.0, 20.0])
parser.add_argument("--dbound", nargs=3, type=float,
default=[2.0, 90.0, 1.0])
# embedding config
parser.add_argument('--instance_seg', action='store_true')
parser.add_argument("--embedding_dim", type=int, default=16)
parser.add_argument("--delta_v", type=float, default=0.5)
parser.add_argument("--delta_d", type=float, default=3.0)
# direction config
parser.add_argument('--direction_pred', action='store_true')
parser.add_argument('--angle_class', type=int, default=36)
parser.add_argument('--lidar_cut_x', action='store_true')
parser.add_argument("--TOP_X_MIN", type=int, default=-20)
parser.add_argument("--TOP_X_MAX", type=int, default=20)
parser.add_argument("--camC", type=int, default=64)
parser.add_argument("--lidarC", type=int, default=128)
parser.add_argument("--crossC", type=int, default=128)
parser.add_argument("--num_heads", type=int, default=1)
parser.add_argument('--cross_atten', action='store_true')
parser.add_argument('--cross_conv', action='store_true')
parser.add_argument('--add_bn', action='store_true')
parser.add_argument('--pos_emd', action='store_true')
parser.add_argument('--pos_emd_img', action='store_true')
parser.add_argument('--lidar_feature_trans', action='store_true')
parser.add_argument("--depth_downsample_factor", type=int, default=4)
parser.add_argument('--depth_sup', action='store_true')
parser.add_argument("--depth_image_size", nargs=2, type=int, default=[256, 704])
parser.add_argument('--lidar_pred', action='store_true')
parser.add_argument('--use_cross', action='store_true')
parser.add_argument('--add_fuser', action='store_true')
parser.add_argument('--add_fuser2', action='store_true')
parser.add_argument('--use_depth_enc', action='store_true')
parser.add_argument('--add_depth_channel', action='store_true')
parser.add_argument('--use_depth_enc_bin', action='store_true')
parser.add_argument('--add_fuser_AlignFA', action='store_true')
parser.add_argument('--add_fuser_AlignFAnew', action='store_true')
parser.add_argument('--use_lidar_10', action='store_true')
parser.add_argument('--pretrained', action='store_true')
args = parser.parse_args()
main(args)
分享完成~