hadoop概述
Apache Hadoop 为可靠的,可扩展的分布式计算开发开源软件。作为一个数据框架允许使用简单的编程模型跨计算机群集分布式处理大型数据集(海量的数据)。分别由一下三个模块组成:
1、Hadoop分布式文件系统(HDFS):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
2、Hadoop YARN:作业调度和集群资源管理的框架。
3、Hadoop MapReduce:一种用于并行处理大型数据集的基于YARN的框架。
上述每个模块有自己独立的功能,而模块之间又有相互的关联。HADOOP通常是指一个更广泛的概念——HADOOP生态圈。
Hadoop起源
为了解决海量数据的可扩展性问题——“如何解决十亿网页的存储和索引问题”。
2003年Google发表了一篇技术学术论文谷歌文件系统(GFS)。GFS也就是google File System,google公司为了存储海量搜索数据而设计的专用文件系统。
2004年Nutch创始人Doug Cutting基于Google的GFS论文实现了分布式文件存储系统名为HDFS。
2004年Google又发表了一篇技术学术论文MapReduce。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行分析运算。
2005年Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
Hadoop生态圈及各个组件简介
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库(列式存储)
ZOOKEEPER:分布式协调服务基础组件
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
数据处理流程
采集数据->数据预处理->导入HIVE仓库—>ETL->报表统计——>结果导出导MYSQL->数据可视化
HDFS 简介
特点:
1.高可靠性:HADOOP的HA,会有两个namenode,避免了单点故障
2.高效性
3.容错性:hadoop 存储数据是有冗余机制(备份),replication
4.高扩展性:可以添加节点,一种是静态模式,一种是动态模式添加(一边提供服务,一边添加节点数量)
HDFS 的文件在物理上四分块存储的,块的大小可以配置dfs.blocksize
会给客户端提供一个统一的抽象目标树,
namenode
文件的各个block的存储管理由DataNode节点承担
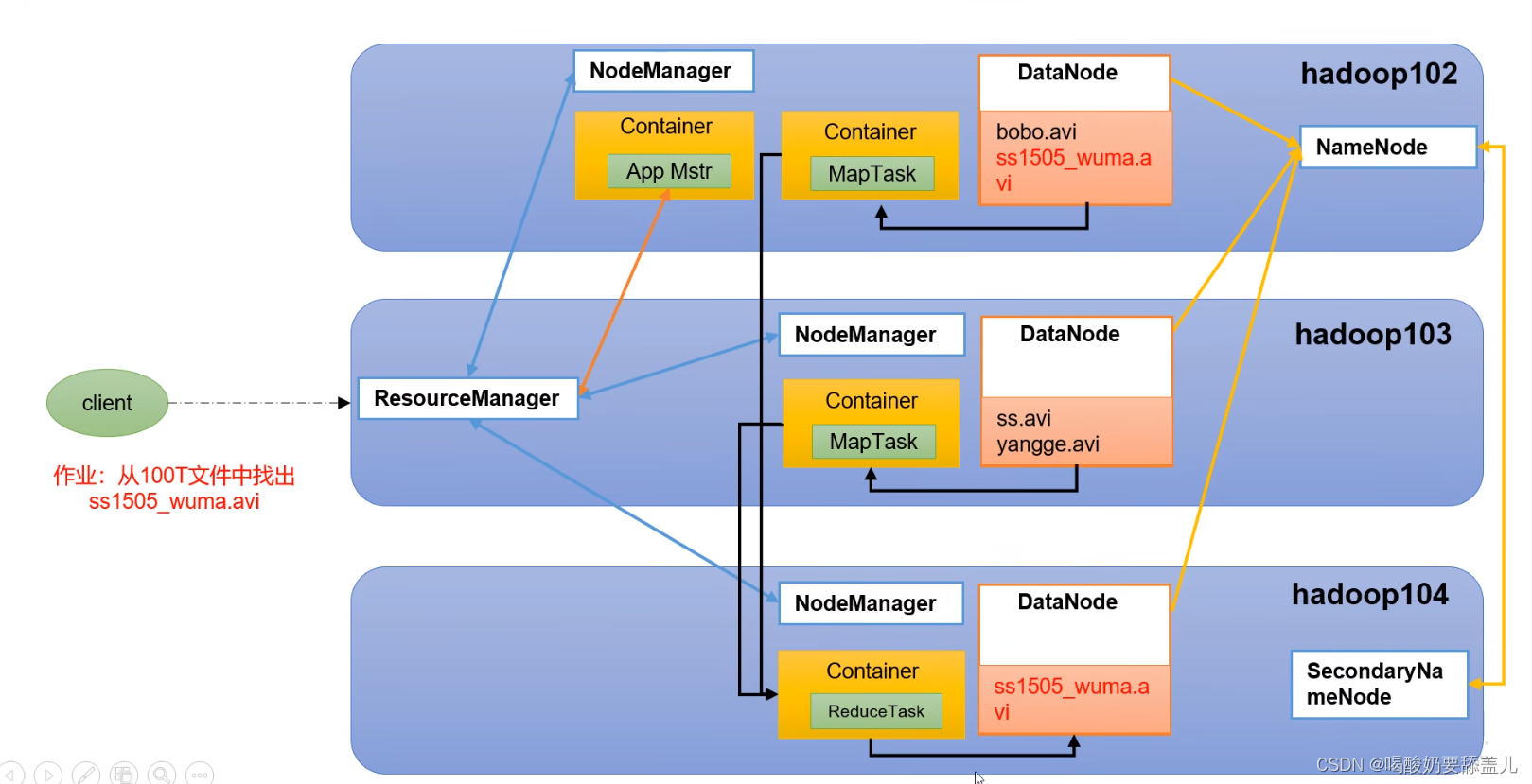
hdfs集群的三大角色:namenode(老板) 、secondarynamenode(秘书),datanode(员工)
namenode负责管理整个文件系统的元数据
DataNode负责管理用户的文件数据块
secondarynamenode职责是合并namenode的edit logs 到fsimage文件
文件会按固定blocksize切成若干份后分布式存储在若干台DataNode上
datanode会定期向namenode汇报自身所保存的block信息(心跳机制),namenode会负责保存文件的副本数量
HDFS的内部工作机制会客户机保持透明,客户端请求访问HDFS都是通过namenode申请来进行的
HDFS的shell
hadoop fs -ls / #查看目录存储文件
bin/hdfs dfs -ls /
bin/hdfs dfs -cat /wc/input/2.txt #查看文件内容
hadoop fs -charp -R root /wc #改变文件组属性
Hadoop fs -chmod 777 文件名
hadoop fs -chown 改变文件的所有者
hsdoop fs -put (-copyFromLocal,-moveFromLocal)(可以实现剪切的效果):本地文件上传到HDFS
hadoop fs -get (-copyTolocal):复制文件到本地路径
hadoop fs -cp 复制文件
hadoop fs -du 展示文件大小
hadoop fs -dus 显示文件大小
-ls/-lsr 返回文件或目录列表
-mkdir 创建目录 -p 创建递归目录
-mv 移动文件或者改名
-rm(-rmr) 删除文件和递归删除
-setrep 改变文件的副本数量
-tail 把文件尾部内容1k字节输出
-touchz 创建空文件
-getmerge 将多个文件合并到一个文件hdfs 的读写机制
HDFS 数据存放策略就是采用同节点与同机架并行的存储方式。在运行客户端的当前节点上存放第一个副本,第二个副本存放在于第一个副本不同的机架上的节点,第三个副本放置的位置与第二个副本在同一个机架上而非同一个节点


HDFS各节点详解
namenode在内存和磁盘中(fsimage和editslog)上分别存在一份元数据镜像文件,内存中元数据镜像保证了HDFS文件系统文件访问效率,磁盘上的元数据文件保证HDFS文件系统的安全。
fsimage:保存文件系统至上次checkpoint为止目录和文件元数据
edits:保存文件系统从上次checkpoint起对HDFS的所有操作记录日志信息
文件启动
启动namenode
读取fsimage元数据镜像文件,加载到内存中
读取edits日志文件,加载到内存中,使当前内存元数据信息与上次关闭系统时一致,然后 在磁盘上生成一份内存中元数据镜像相同的fsimage文件,同时生成一个新的空的edits文件用于记录以后的HDFS文件系统的更改
启动datanode
namenode接收datanode发送注册请求
接收DataNode发送的blockreport
2.namenode 元数据管理
1. 内存镜像=fsimage+edits
2. edits文件过大将会导致namenode重启速度慢
3. secondary namenode 负责定期合并他们
3.secondaryNamenode 工作流程
secondary通知Namenode切换Edits文件
secondary通过HTTP请求从namenode获得fsimage和edits文件
secondary将fsimage载入内存,然后合并edits
secondary将新的fsimage发回给Namenode,用新的fsimage替换旧的
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。
HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为: timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval 而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。