文章目录
坚持学习,老年痴呆追不上我,Hello 大家好,我是阿月。Kafaka 是后端找工作面试中绕不过去的一个知识,今天一起学习几道 Kafka 架构设计类的面试题。
1. Kafka 是如何保证高可用性和容错性的?
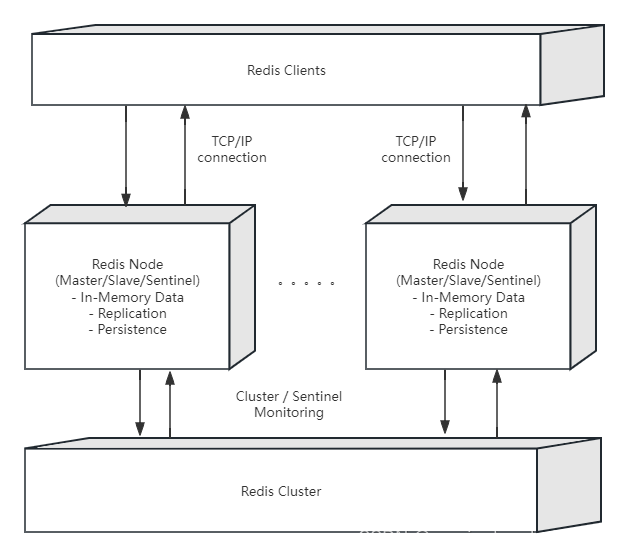
Kafka 使用分布式架构来保证高可用性和容错性。它通过数据的复制和分区的设计来实现这一目标。每个主题可以分成多个分区,并且每个分区可以有多个副本(replica)。副本分布在不同的 broker 上,当一个 broker 失效时,副本仍然可以在其他 broker 上继续服务。Kafka 还使用 ZooKeeper 来管理集群的状态和元数据,确保集群的稳定运行。
2. Kafka 的存储机制是怎样的?它是如何处理大量数据的?
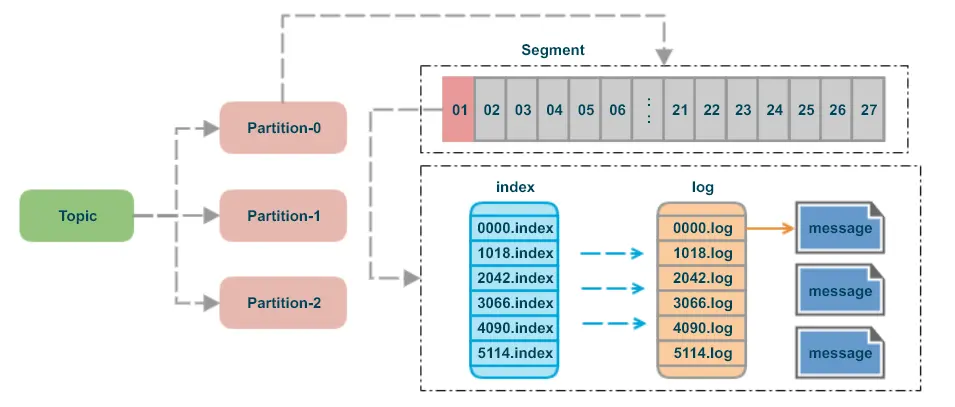
Kafka 使用基于磁盘的存储来持久化消息。消息被追加到分区的末尾,并保留一定的时间(通过配置)或一定的大小。这种存储机制使得 Kafka 能够处理大量的数据,并且能够在断电或节点故障时保持数据的完整性和可靠性。
3. Kafka 如何处理消费者的消费速率低于生产者的生产速率?
Kafka 使用分区和消费者组的概念来处理消费者的消费速率低于生产者的生产速率。每个消费者组可以包含多个消费者,每个消费者订阅一个或多个分区。Kafka 将消息广播到所有订阅了该主题的消费者组中的消费者。如果消费者的消费速率低于生产者的生产速率,则 Kafka 会保留未被消费的消息,并在消费者准备好时重新发送这些消息。
4. Kafka 集群中的 Controller 是什么?它的作用是什么?
在 Kafka 集群中,Controller 是一个特殊的 broker,负责管理集群中的分区和副本的分配、故障检测和恢复等工作。Controller 通过与 ZooKeeper 协作来确保集群的稳定运行,并处理集群中的各种状态转换和变更。
5. Kafka 的消息传递模型是怎样的?它与传统消息队列有什么不同?
Kafka 的消息传递模型是基于发布/订阅(publish/subscribe)模式的,生产者将消息发布到主题,消费者从主题订阅并消费消息。与传统消息队列不同的是,Kafka 的消息传递是持久化的,消息存储在磁盘上,并且支持多个消费者组对同一主题的并行消费。这使得 Kafka 能够处理大规模的数据,并提供高吞吐量和低延迟的消息传递。

![[AIGC] redis 持久化相关的<span style='color:red;'>几</span><span style='color:red;'>道</span><span style='color:red;'>面试</span><span style='color:red;'>题</span>](https://img-blog.csdnimg.cn/img_convert/444aeb38d9678ee80abbe8066cbc2675.png)