Redis之缓存穿透、缓存雪崩、缓存击穿
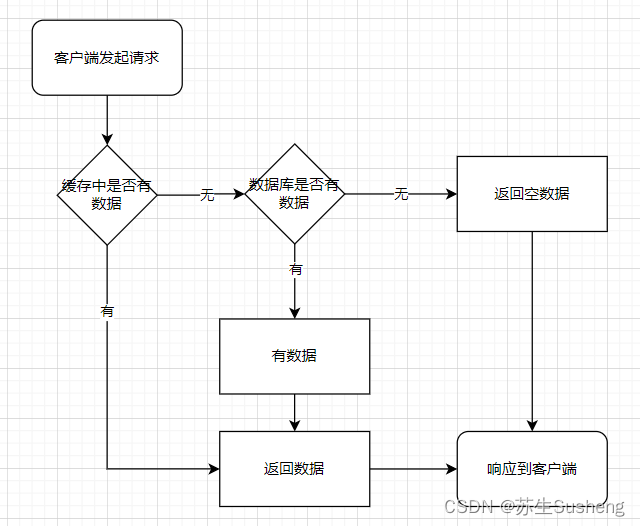
什么是缓存穿透?

如果有人故意将请求打到未缓存的数据上,会对数据库造成巨大的压力
如何解决?
做好参数校验,比如请求的id不能<0,在访问数据库前就把这些异常访问拦截了
缓存一些无效key,假如访问的key既不再Redis中也不在数据库中,那么就把当前这个key缓存在Redis中,这种方式可以防止恶意请求使用同一个key进行缓存穿透。但是这种方法不能从根本上解决问题。人也不傻,一看,哎呀第一次访问这么慢(假设500ms),后面怎么变快了(100ms),看来要变化一下请求参数了😈
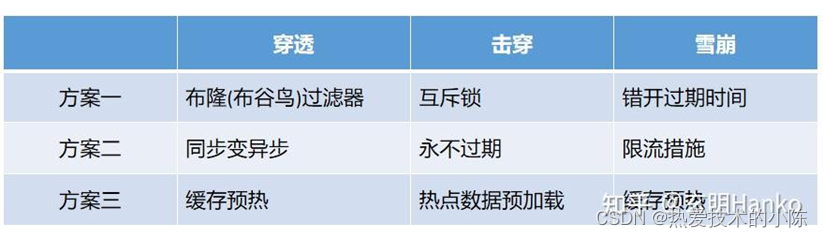
布隆过滤器,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除
布隆过滤器的原理如下:

- 位数组:布隆过滤器使用一个位数组作为基本的存储结构,初始时所有位都被设置为0。
- 多个哈希函数:布隆过滤器使用多个哈希函数,每个哈希函数可以将输入元素映射到位数组中的多个位置。这些哈希函数通常是独立且均匀分布的,可以确保元素被哈希到位数组的不同位置。
- 插入操作:当一个元素被插入到布隆过滤器中时,该元素经过多个哈希函数得到对应的多个哈希值,然后将位数组中对应位置的值设置为1。
- 查询操作:当查询一个元素是否存在于布隆过滤器中时,将该元素经过多个哈希函数得到对应的多个哈希值,然后检查位数组中对应位置的值是否都为1。如果所有位置都为1,则判断该元素可能存在于布隆过滤器中;如果有任何一个位置为0,则可以确定该元素一定不存在于布隆过滤器中。
布隆过滤器的优点是插入和查询操作的时间复杂度都是常数级别的,具有很高的查询速度和空间效率。但是由于哈希冲突的存在和误判率的问题,布隆过滤器可能会出现误判,即判断某个元素存在于布隆过滤器中,但实际上该元素并没有被插入。因此,在使用布隆过滤器时,需要根据具体情况来权衡误判率和空间需求,以及对查询性能的要求。
关于更多的详细介绍可以看:五分钟搞懂布隆过滤器
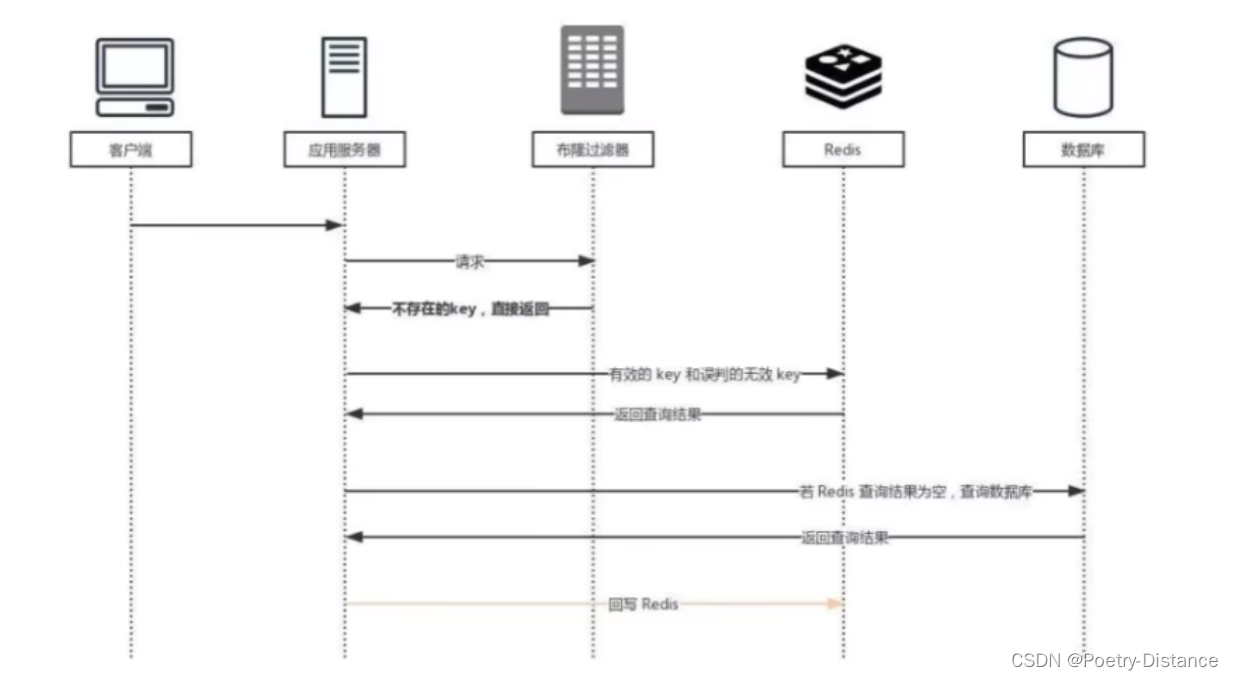
使用布隆过滤器解决缓存穿透的流程
- 将所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来时,只需要判断,布隆过滤器中是否存在请求的数据(比如数据的id)
- 如果不存在,可以认为这是一个恶意请求,直接返回空,不走数据库;
- 如果存在就正常走缓存和数据库
缓存雪崩
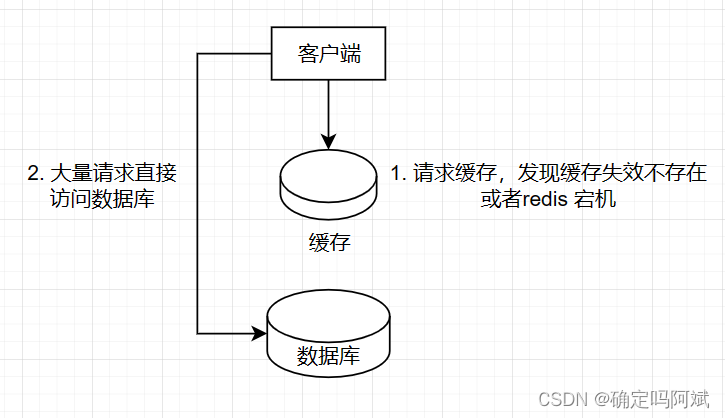
缓存雪崩是指在同一时间内大量的缓存key同时失效或者Redis服务器宕机,导致大量的请求到达数据库,带来巨大压力

解决方案
避免大量的缓存key同时失效
- 可以给缓存随机的失效时间,避免同一时间大量的Key同时失效
- 缓存预热,将一些热点数据提前加载到Redis中
缓存预热的实现方式
- 定时任务,比如基于Spring的定时任务
/**
* 每5分钟加载1次热点数据
*/
@Scheduled(fixedRate = 5 * 60 * 1000)
public void loadHotData() {
// 查询数据库...
// 将热点数据缓存在Redis中
}
- 使用消息队列,比如RabbitMQ异步进行缓存预热,将数据库中的热点数据的主键发送到消息队列中,然后由缓存消费队列中的数据,根据消息主键查询数据库并更新缓存
避免Redis服务器宕机
- 限流,避免流量压垮Redis
- 多级缓存,可以使用本地缓存+Redis缓存的模式,先查询本地缓存,如果命中就直接返回,无需访问Redis,减轻Redis压力
- 采用Redis集群,例如主从架构,主节点宕机了,从节点可以顶上
缓存击穿

缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
解决方案
- 互斥锁方案,同一时间下只能有一个线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值;
优点:可以保证一致性,实现简单,没有额外的内存消耗
缺点:线程需要等待,性能受影响
- 热点数据不设置过期时间,由后台异步更新缓存,或者在热点数据要过期前,提前通知后台线程更新缓存以及重新设置过期时间
优点:不设置过期时间可以确保热点数据不会因为过期而被清除,从而降低了缓存失效的频率,减少了缓存击穿的可能性,同时使用异步更新保证数据的一致性
缺点:实现复杂度增加、内存消耗增加
总结
缓存击穿:大量的请求访问不存在的数据,导致数据库的压力上升
缓存雪崩:大量的缓存数据同一时间失效,导致数据库的压力上升
缓存击穿:高并发下,一个热点的数据缓存过期了,所有的并发请求同时打到数据库,导致数据库的压力上升