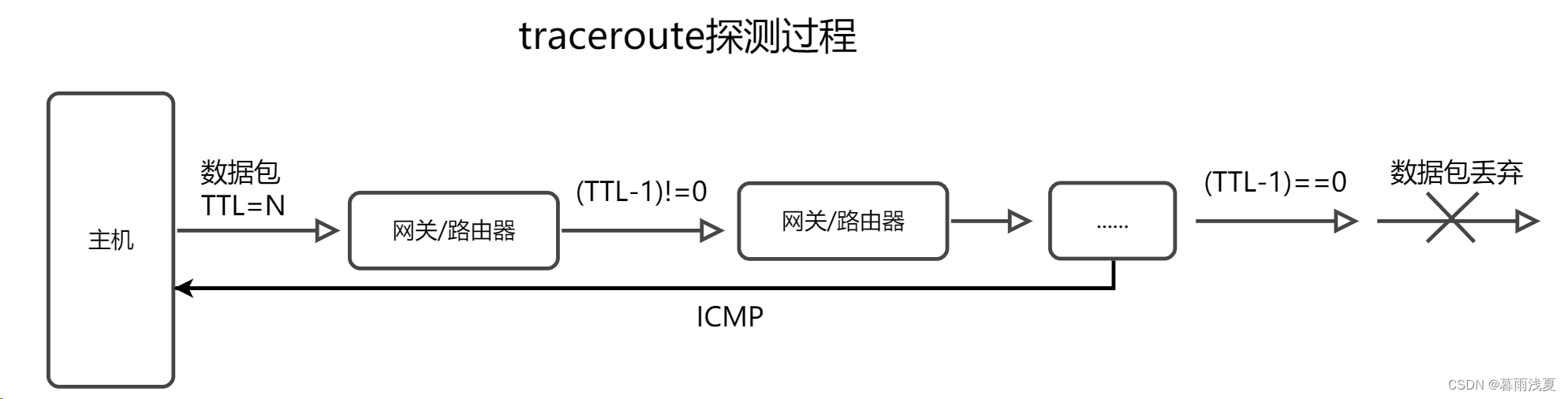
Linux grep (global regular expression) 命令用于查找文件里符合条件的字符串或正则表达式。
grep指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为-,则grep指令会从标准输入设备读取数据。
语法
grep [options] pattern [files]
或
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
pattern: 表示要查找的字符串或正则表达式。files: 表示要查找的文件名,可以同时查找多个文件,如果省略files参数,则默认从标准输入中读取数据。
用法示例
- 参数
F和f。
F表示确切匹配,对模式串不做任何转义。grep -F "*.a" filename
表示只找*.a这个字符串。
f表示从文件中读取模式串。文件中的每一个模式串独占一行。`grep -f keywords.txt filename
- 参数
C和c。
C表示上线文,后边跟数字,表示显示目标位置的前后多少行。grep -C 5 "hello" fileNamec表示统计匹配到了多少行。grep -c "hello" fileName
- 参数
A和a。
A表示匹配行之前需要显示多少行`。grep -A 3 "hello" fileNamea表示将所有的内容当作纯文本处理,例如二进制的字符也会被当作文本来匹配。与--text等效。grep -a "10101" binaryText
- 参数
B和b。
B表示匹配行之后显示多少行。grep -B 3 hello fileNameb表示匹配行行首位置的偏移量,即匹配行到开始位置的字节量。grep -b "hell0" filename
- 参数
d。
用于控制如何处理目录。
-d skip:不对目录进行搜索。-d recurse:递归搜索目录。
- 参数
E和e。
grep -E与egrep等效。e使用正则进行匹配。主要使用多个正则。grep -e ^hello -e hello$ filename
- 参数
H和h。
H显示匹配的文件。h不显示匹配的文件。
- 参数
L和l。
L列出未匹配的文件名称。l列出匹配的文件名称`。
- 参数
V和v。
V显示版本信息。v反向匹配。
- 参数
y和i。
都是忽略大小写。 - 参数
x和w。
x把模式串当作一整行,检查是否能匹配。w匹配单词。
- 参数
o、n、q、r和s。
o只显示匹配的部分。n显示匹配的行号。q不显示任何信息,可以检查是否匹配了。r递归搜索。s不显示错误信息。