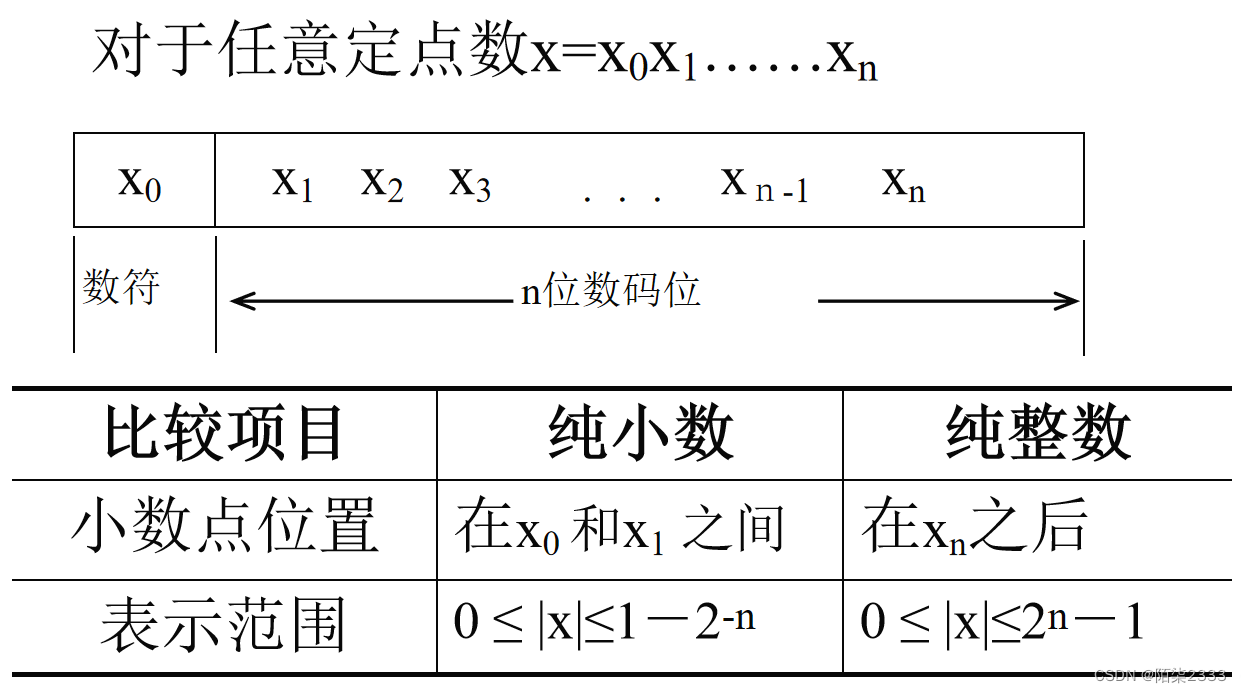
3、ReLU
3.1 公式
ReLU函数的公式:
f ( x ) = { x , x > = 0 0 , x < 0 f(x) = \begin{cases} x&,x>=0 \\ 0&,x<0 \end{cases} f(x)={x0,x>=0,x<0
ReLU函数的导函数:
f ′ ( x ) = { 1 , x > = 0 0 , x < 0 f'(x) = \begin{cases} 1&,x>=0 \\ 0&,x<0 \end{cases} f′(x)={10,x>=0,x<0
3.2 对应的图像

3.3 对应的图像的代码
import numpy as np
import matplotlib.pyplot as plt
# 定义 x 的范围
x = np.linspace(-10, 10, 1000)
# 计算 ReLU 值
relu_values = np.maximum(0, x)
# 计算 ReLU 的导数
relu_derivative_values = np.where(x > 0, 1, 0)
# 绘制 ReLU 函数
plt.plot(x, relu_values, label='ReLU(x)')
# 绘制 ReLU 的导数
plt.step(x, relu_derivative_values, where='post', label='Derivative of ReLU(x)')
# 设置图例
plt.legend()
# 设置标题和轴标签
plt.title('ReLU Function and Its Derivative')
plt.xlabel('x')
plt.ylabel('y')
# 显示网格
plt.grid(True)
# 显示图形
plt.show()
3.4 优点与不足
ReLU函数:
1、ReLU 函数在正输入时是线性的,收敛速度快,计算速度快,同时符合恒等性的特点。当输入为正时,由于导数是1,能够完整传递梯度,不存在梯度消失的问题(梯度饱和问题)。
2、计算速度快。ReLU 函数中只存在线性关系且无论是函数还是其导数都不包含复杂的数学运算,因此它的计算速度比 sigmoid 和 tanh 更快。
3、当输入大于0时,梯度为1,能够有效避免链式求导法则梯度相乘引起的梯度消失和梯度爆炸;计算成本低。
4、它保留了 step 函数的生物学启发(只有输入超出阈值时神经元才激活),不过当输入为正的时候,导数不为零,从而允许基于梯度的学习(尽管在 x=0 的时候,导数是未定义的)。当输入为负值的时候,ReLU 的学习速度可能会变得很慢,甚至使神经元直接无效,因为此时输入小于零而梯度为零,从而其权重无法得到更新,在剩下的训练过程中会一直保持静默。
ReLU不足:
1、ReLU的输入值为负的时候,输出始终为0,其一阶导数也始终为0,这样会导致神经元不能更新参数,也就是神经元不学习了,这种现象叫做“Dead Neuron”。为了解决ReLU函数这个缺点,在ReLU函数的负半区间引入一个泄露(Leaky)值,所以称为Leaky ReLU函数。
2、与Sigmoid一样,其输出不是以0为中心的(ReLU的输出为0或正数)。
3、ReLU在小于0的时候梯度为零,导致了某些神经元永远被抑制,最终造成特征的学习不充分;这是典型的 Dead ReLU 问题,所以需要改进随机初始化,避免将过多的负数特征送入ReLU。
3.5 torch.relu()函数
在PyTorch中,torch.relu 是一个常用的激活函数,它实现了ReLU (Rectified Linear Unit) 及其导数的计算。ReLU函数对于输入的每个元素都执行以下操作:
f(x) = max(0, x)
即,如果输入值 x 是负数,输出为0;如果 x 是非负数,输出就是 x 本身。
在PyTorch中,torch.relu 不仅可以用来计算ReLU激活函数的值,而且当反向传播时,它会自动计算并应用ReLU的导数。ReLU的导数很简单:
f'(x) = 1 if x > 0
= 0 if x <= 0
也就是说,当输入值大于0时,ReLU的导数是1;当输入值小于或等于0时,ReLU的导数是0。
以下是如何在PyTorch中使用 torch.relu 的示例:
import torch
# 创建一个张量
x = torch.tensor([-1.0, 0.0, 1.0, 2.0])
# 计算ReLU激活函数的值
y = torch.relu(x)
# 输出ReLU激活函数的值
print(y) # 输出: tensor([0., 0., 1., 2.])
# 假设我们有一个关于y的梯度,我们需要反向传播这个梯度到x
y.backward(torch.tensor([1.0, 1.0, 1.0, 1.0]))
# 输出x的梯度(即ReLU的导数)
print(x.grad) # 输出: tensor([0., 0., 1., 1.])
在这个例子中,你可以看到当 x 的值为负时(例如 -1.0 和 0.0),对应的 x.grad(即ReLU的导数)是 0;而当 x 的值为正时(例如 1.0 和 2.0),对应的 x.grad 是 1。这正好符合ReLU导数的定义。





























![[AutoSar]BSW_Com015 PDUR 模块配置](https://img-blog.csdnimg.cn/direct/84382a3c560e435da5ef2b99dfe01bc8.png)