一、前言
上一篇文章中,介绍了通过shell脚本读取配置文件获取到IP地址组、服务端口组、规则清单这三个模块类别基础数据。基础数据中还需要进一步进行展开处理,生成三类扩展表。如IP地址组中,同一个地址组下存在多个IP地址,每组IP需要展开成每条记录;服务端口组中,同个服务组又存在多个端口情况,每组服务也需要展开每条记录;规则清单则需要跟服务组、端口组做相应的字段匹配,生成更详细的规则展开清单。由于上一步生成的3类基础数据,本质上还是以表格的形式记录,所以这里使用到python的pandas、numpy、csv等模块,可以完成excel表格数据的加工处理工作。
二、python处理说明
1、示例中用到的模块
import pandas as pd
import time, datetime
import os
import socket, struct
import csv
import numpy as np
2、处理端口组数据
首先对端口组中存在同一组多端口的,进行拆分多行;其次增加起始端口和结束端口字段,展开端口表信息。示例(展示部分):
def format_servgroup():
# 读取文件中所有数据
data = pd.read_csv("fwservgroup.csv")
# 按照;分割列
data_url = data['service'].str.split(';', expand=True)
# 行转列
data_url = data_url.stack()
# 重置索引,将新生成的index,重置到原来的索引上
data_url = data_url.reset_index(level=1, drop=True).rename('service')
# 和原始数据合并
data = data.drop(['service'], axis=1).join(data_url)
# 写入csv文件
data.to_csv(r'fwservgroupmore.csv', sep=",", index=False)
# 去除其中空值的数据
data = pd.read_csv("fwservgroupmore.csv")
data.dropna(how='any', inplace=True, axis=0, subset=['service'])
data.drop_duplicates(inplace=True)
data.to_csv(r'fwservgroupmore.csv', sep=",", index=False)
# 拆分起始端口信息
df=pd.read_csv("linshi3.csv")
df=pd.merge(df,pd.DataFrame(df["service"].str.split("-",expand=True)),how="inner",left_index=True,right_index=True)
df.to_csv('linshi3.csv',index=None)
df=pd.read_csv("linshi3.csv")
df.rename(columns={'0': 'protocol','1': 'portstart','2': 'portend'}, inplace=True)
df.to_csv('linshi3.csv',index=None)
df=pd.read_csv("linshi3.csv")
col_name=df.columns.tolist()
for portend in col_name:
try:
df1=df[df['portend'].notna()]
df2=df[df[['portend']].isnull().T.any()]
df2=df2.copy()
df2['portend']=df2['portstart']
df2.to_csv('linshi4.csv',index=None)
df2=pd.read_csv("linshi4.csv")
data=pd.concat([df1,df2],axis=0)
data.drop_duplicates(inplace=True)
data.to_csv('fwservgroupfull.csv',index=None)
except:
col_name.insert(5, 'portend')
df=df.reindex(columns=col_name)
df['portend'] = df['portstart']
df.to_csv('fwservgroupfull.csv',index=None)
3、处理地址组数据
首先地址组中也存在同一地址组多地址的,进行拆分多行;其次增加起始地址和结束地址字段,展开端口表信息;并且地址中存在掩码格式的,需要进行掩码转换匹配,示例(展示部分):
def format_ipgroup():
# 读取文件中所有数据
data = pd.read_csv("policy-ipgroup",encoding='utf-8')
# 按照;分割列
data_url = data['ipaddress'].str.split(';', expand=True)
# 行转列
data_url = data_url.stack()
# 重置索引,将新生成的index,重置到原来的索引上
data_url = data_url.reset_index(level=1, drop=True).rename('ipaddress')
# 和原始数据合并
data = data.drop(['ipaddress'], axis=1).join(data_url)
# 写入csv文件
data.to_csv(r'fwipgroupmore.csv', sep=",", index=False)
# 去除其中空值的数据
data = pd.read_csv("fwipgroupmore.csv")
data.dropna(how='any', inplace=True, axis=0, subset=['ipaddress'])
data.drop_duplicates(inplace=True)
data.to_csv(r'fwipgroupmore.csv', sep=",", index=False)
#按照mask帅选
df=pd.read_csv("linshi4.csv")
df= df.loc[df["1"].str.contains("mask",na=False)]
df.rename(columns={'0': 'ipstart','1': 'type','2': 'mask'}, inplace=True)
df=df[['fwname','ipgroupname','securityzone','ipaddress','type','mask','ipstart']]
df.to_csv('linshi-mask.csv',index=None)
#按照range帅选
df=pd.read_csv("linshi4.csv")
df= df.loc[df["0"].str.contains("range")]
df.rename(columns={'0': 'type','1': 'ipstart','2': 'ipend'}, inplace=True)
df=df[['fwname','ipgroupname','securityzone','ipaddress','type','ipstart','ipend']]
df.to_csv('linshi-range.csv',index=None)
#帅选剩余
df=pd.read_csv("linshi4.csv")
df=df[df[['2']].isnull().T.any()]
df.rename(columns={'0': 'ipstart','1': 'mask','2': 'type'}, inplace=True)
df['type'] ="mask"
df=df[['fwname','ipgroupname','securityzone','ipaddress','type','mask','ipstart']]
df.to_csv('linshi-other.csv',index=None)
4、处理规则数据
首先规则表中存在多源地址、多目的地址、多端口的情况,都需要进行拆分多行;其次拆分完后需要跟前面端口展示表,地址展开表进行关联匹配,最后对IP地址进行数值转换, 方便后续的查询操作,示例(展示部分):
def format_rule_split():
# 读取文件中所有数据
data = pd.read_csv("policy-rule")
data=data[['fwname','rulename','sourceip']]
# 按照sourceip分割列
data_url = data['sourceip'].str.split(';', expand=True)
# 行转列
data_url = data_url.stack()
# 重置索引,将新生成的index,重置到原来的索引上
data_url = data_url.reset_index(level=1, drop=True).rename('sourceip')
# 和原始数据合并
data = data.drop(['sourceip'], axis=1).join(data_url)
data.to_csv(r'linshi1.csv', sep=",", index=False)
def format_rule_sourceip():
#扩展原地址
df=pd.read_csv("netfirewallsmore.csv")
df=df[['fwname','sourceip']]
df.rename(columns={'sourceip': 'ipgroupname'}, inplace=True)
df1= pd.read_csv("fwipgroupfull.csv")
df1=df1[['ipgroupname','ipstart','ipstartnum','ipend','ipendnum']]
df2=pd.merge(df1,df,on=['ipgroupname'],how='right')
df2.to_csv('b1.csv',index=None)
df= pd.read_csv("b1.csv")
#df1=df[df['ipstart'].notna()]
df=df[df[['ipstart']].isnull().T.any()]
#分割数据
df=pd.merge(df,pd.DataFrame(df["ipgroupname"].str.split("-",expand=True)),how="inner",left_index=True,right_index=True)
df.to_csv('b2.csv',index=None)
#IP地址转数字
df=pd.read_csv("b2.csv")
df['ipstart']=df['0']
df['ipend']=df['1']
ipstart=df['ipstart'].tolist()
ipend=df['ipend'].tolist()
data=[]
for ip in ipstart:
try:
ch3 = lambda x:sum([256**j*int(i) for j,i in enumerate(x.split('.')[::-1])])
num=ch3(ip)
list1=[ip,num]
data.append(list1)
except:
pass
data = pd.DataFrame(data)
data.drop_duplicates(inplace=True)
data.to_csv('ruleipstartnum.csv',index=None)
def format_rule_destip():
#扩展目的地址
df=pd.read_csv("linshi-sourceip.csv")
df=df[['fwname','destip']]
df.rename(columns={'destip': 'ipgroupname'}, inplace=True)
df1= pd.read_csv("fwipgroupfull.csv")
df1=df1[['ipgroupname','ipstart','ipstartnum','ipend','ipendnum']]
df2=pd.merge(df1,df,on=['ipgroupname'],how='right')
df2.to_csv('c1.csv',index=None)
df= pd.read_csv("c1.csv")
#df1=df[df['ipstart'].notna()]
df=df[df[['ipstart']].isnull().T.any()]
df=pd.merge(df,pd.DataFrame(df["ipgroupname"].str.split("-",expand=True)),how="inner",left_index=True,right_index=True)
df.to_csv('c2.csv',index=None)
def format_rule_service():
#扩展服务端口
df=pd.read_csv("linshi-destip.csv",low_memory=False)
df=df[['fwname','service']]
df.rename(columns={'service': 'servicegroupname'}, inplace=True)
df1= pd.read_csv("fwservgroupfull.csv")
df2=pd.merge(df1,df,on=['fwname','servicegroupname'],how='right')
df2.drop_duplicates(inplace=True)
df2.to_csv('d1.csv',index=None)
三、结果展示
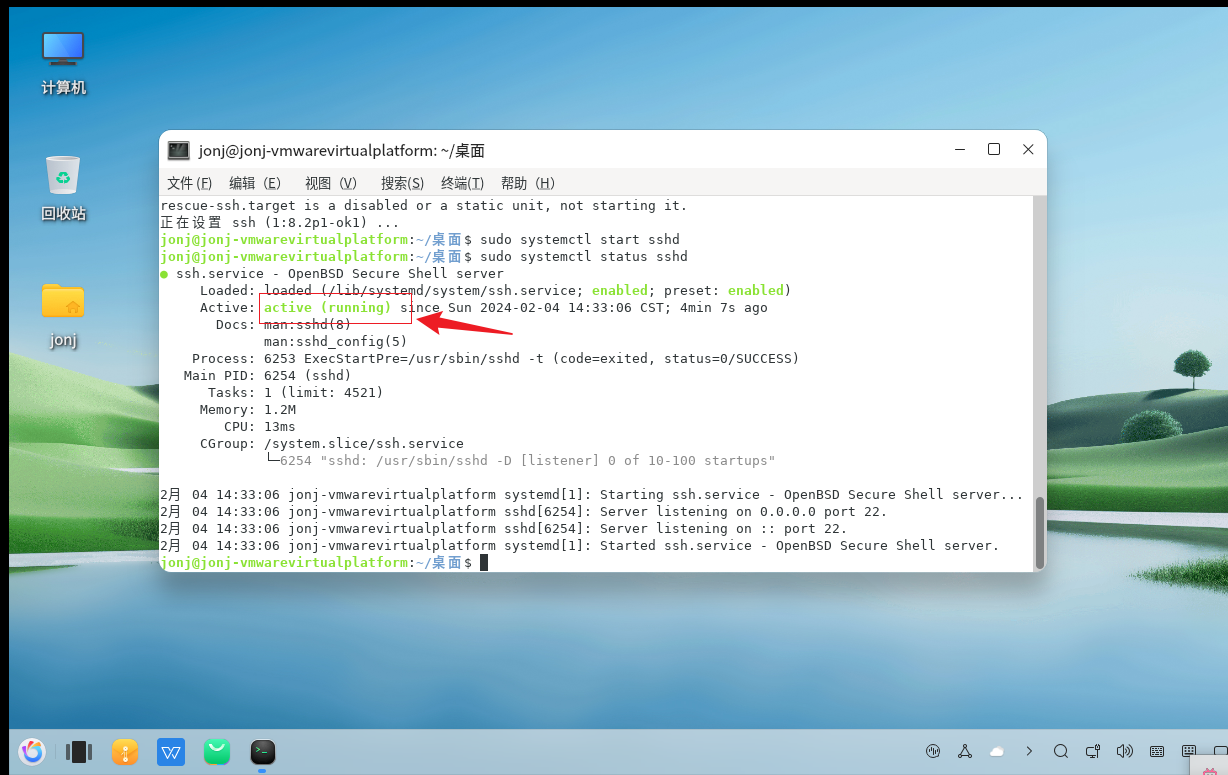
三个基础表数据处理脚本合并执行,完成后得到3类表的扩展数据,后续再导入到数据库,用于页面查询。
执行过程,记录输出每一步操作时间和结果,如有异常可调试检查出来。

端口组展开表

地址组展开表

策略展开表