本教程参考《RDeepLearningEssential》
这是本专栏的最后一篇文章,一路走来,大家应该都可以独立的建立一个自己的神经网络进行特征学习和预测了吧!
6.1 缺失值处理
在我们使用大量数据进行建模的时候,缺失值对模型表现的影响非常大:
(1)对模型训练的影响:在训练神经网络时,如果输入数据中存在缺失值,那么这些值可能不会被模型正确地学习或解释。因为神经网络通常要求输入数据是完整且一致的,缺失值可能导致模型无法学习到数据的完整分布,从而影响其预测能力。此外,一些优化算法(如梯度下降)在计算过程中可能会遇到不稳定的数值,进而影响到模型参数更新的准确性。
(2)对模型评估的影响:在模型评估阶段,缺失值同样会带来问题。例如,在评估模型性能时使用诸如准确率等指标时,若测试集存在缺失值,则可能导致评估结果的偏差,使得模型的实际性能被高估或低估。
(3)对模型泛化能力的影响:缺失值的存在还可能降低模型的泛化能力,即模型在新数据上的应用效果。这是因为在实际应用中,新数据也可能会出现缺失值,如果模型没有很好地处理这种情况,那么其在实际应用中的表现可能会受到影响。
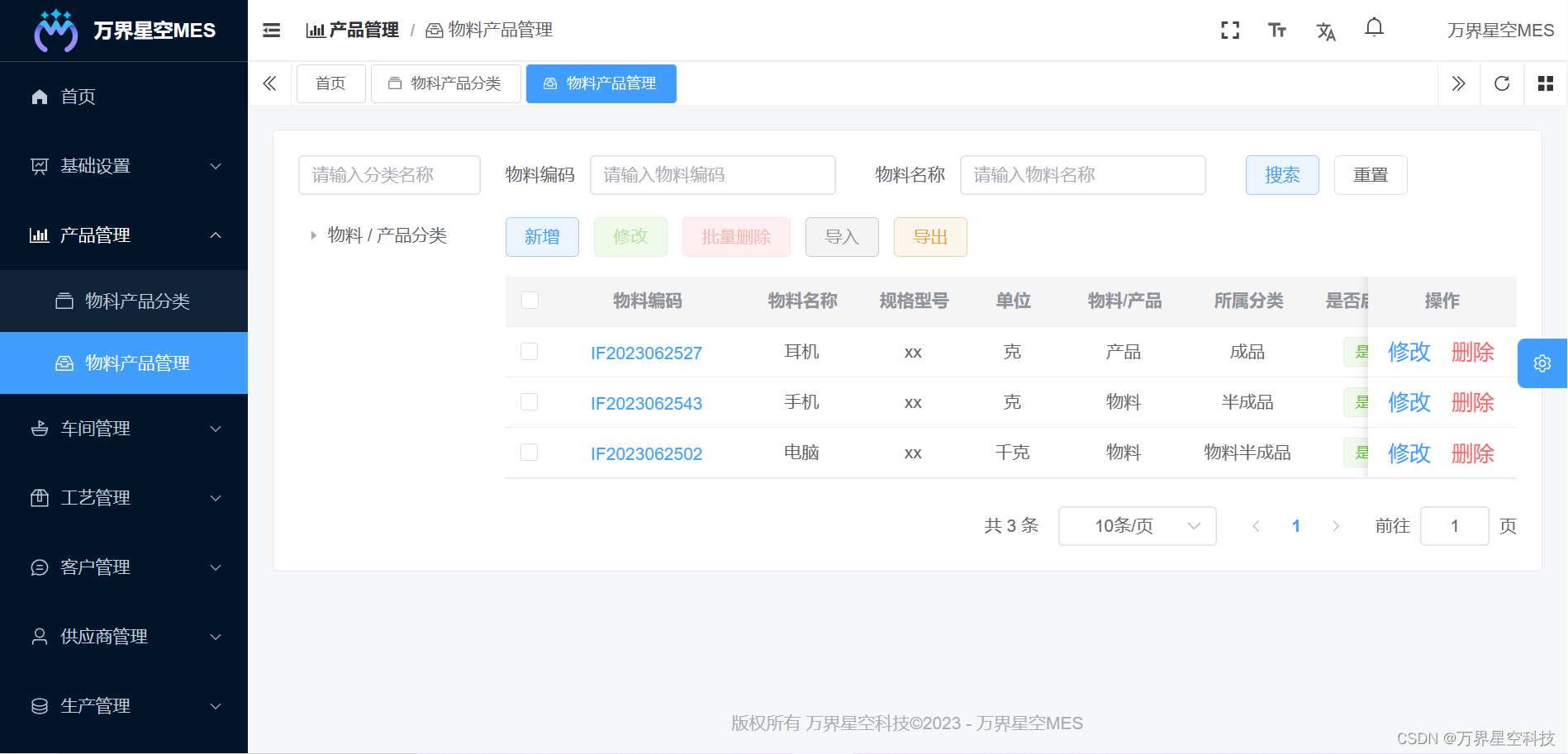
6.1.1 gridExtra和mgcv包的安装
install.packages('gridExtra')
install.packages('mgcv')`gridExtra`是一个用于扩展`grid`图形系统的包,这个包特别适用于创建复杂的布局和组合多个图形对象。`mgcv`是“混合模型广义可加模型”的缩写,它是专门设计用来拟合广义可加模型(GAMs)及其扩展形式的包。广义可加模型是一种统计模型,它允许响应变量与一个或多个预测变量之间存在非线性关系。通过使用平滑函数,`mgcv`能够灵活地建模这种非线性关系,并且可以处理分类变量和连续变量的交互作用。这使得`mgcv`非常适合于那些数据中存在复杂关系的情况,比如生态学、流行病学和经济学等领域的研究。
6.1.2 使用H2O处理缺失数据
library('h2o')
cl <- h2o.init(
max_mem_size = "20G",
nthreads = 10,
ip = "127.0.0.1", port = 54321)
options(width = 70, digits = 2)我们使用鸢尾花iris数据集进行演示,H2O包里有处理缺失值的函数,比如使用均值、中位数或者众数进行填补。 我们这里使用随机森林的机器学习方法来进行填补:
## random forest imputation
d.imputed <- d
## prediction model
for (v in missing.cols) {
tmp.m <- h2o.randomForest(
x = setdiff(colnames(h2o.dmiss), v),
y = v,
training_frame = h2o.dmiss)
yhat <- as.data.frame(h2o.predict(tmp.m, newdata = h2o.dmiss
))
d.imputed[[v]] <- ifelse(is.na(d.imputed[[v]]), yhat$predict, d.imputed[[v]])
}我们通过散点图看一下效果:
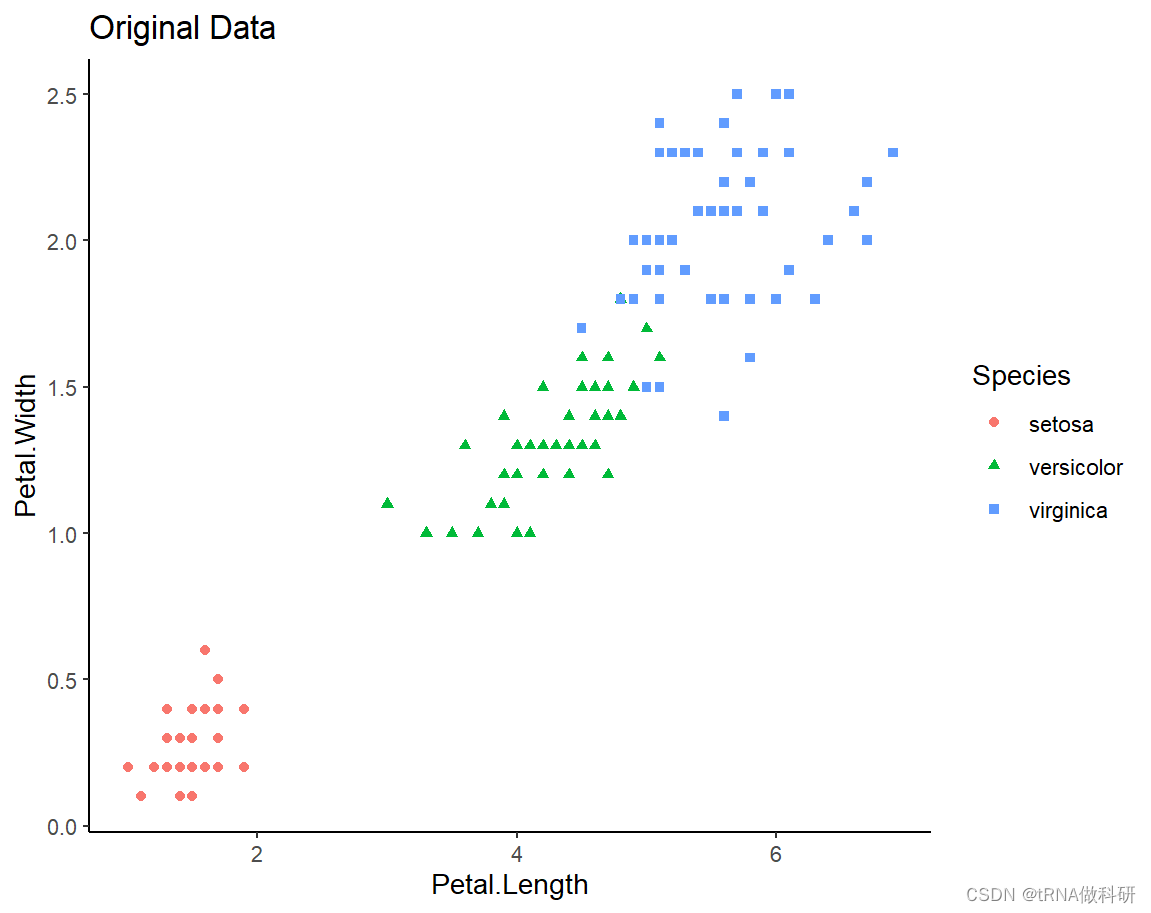
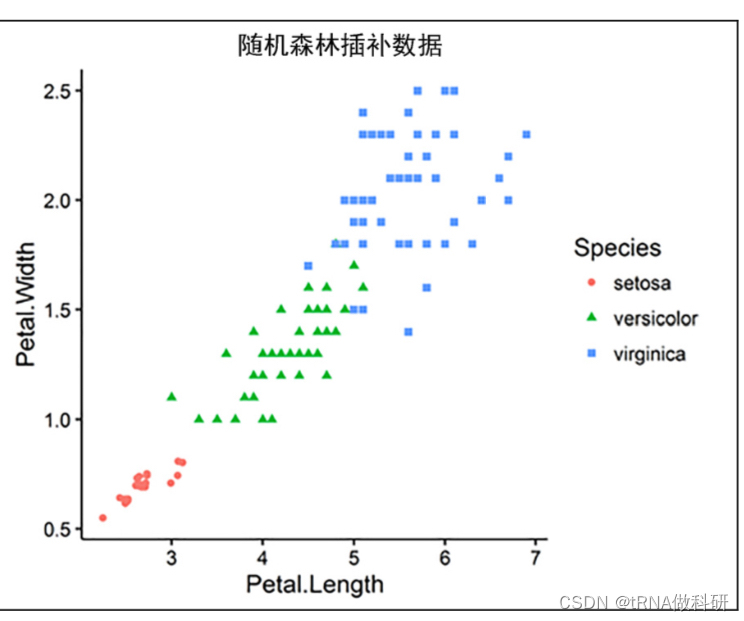
一般来说,我们会发现用均值作为补充,会对离群值或者整体数据的极值产生影响。
6.2 低准确度模型解决
我们在建模过程中,非常有挑战性,也是最重要的,是选取超参数,如上之前教程中提到的:R语言深度学习-4-识别异常数据(无监督学习/自动编码器)-CSDN博客
而在实际运用中,我们很少能获得一个全局最优,我们来看一些方法:
6.2.1 网格搜索
我们除了使用手动试错的方法外,我们还可以使用网格搜索或者随机搜索:我们使用expand.grid生成随机的组合。
expand.grid(
layers = c(1, 2, 4),
epochs = c(50, 100),
l1 = c(.001, .01, .05))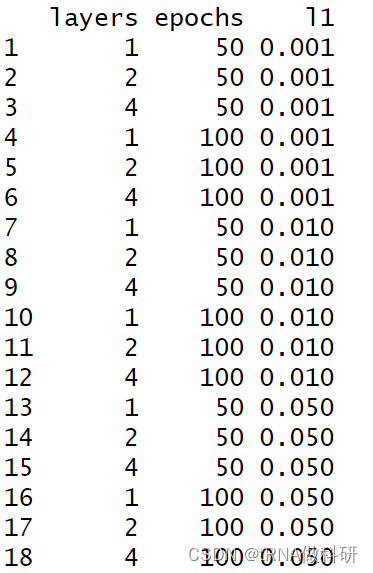
但是如果我们选取的超参数有十多个,那就是n的十多次方,如果分别训练的化,可能需要一两天才能完成。
6.2.2 随机搜索
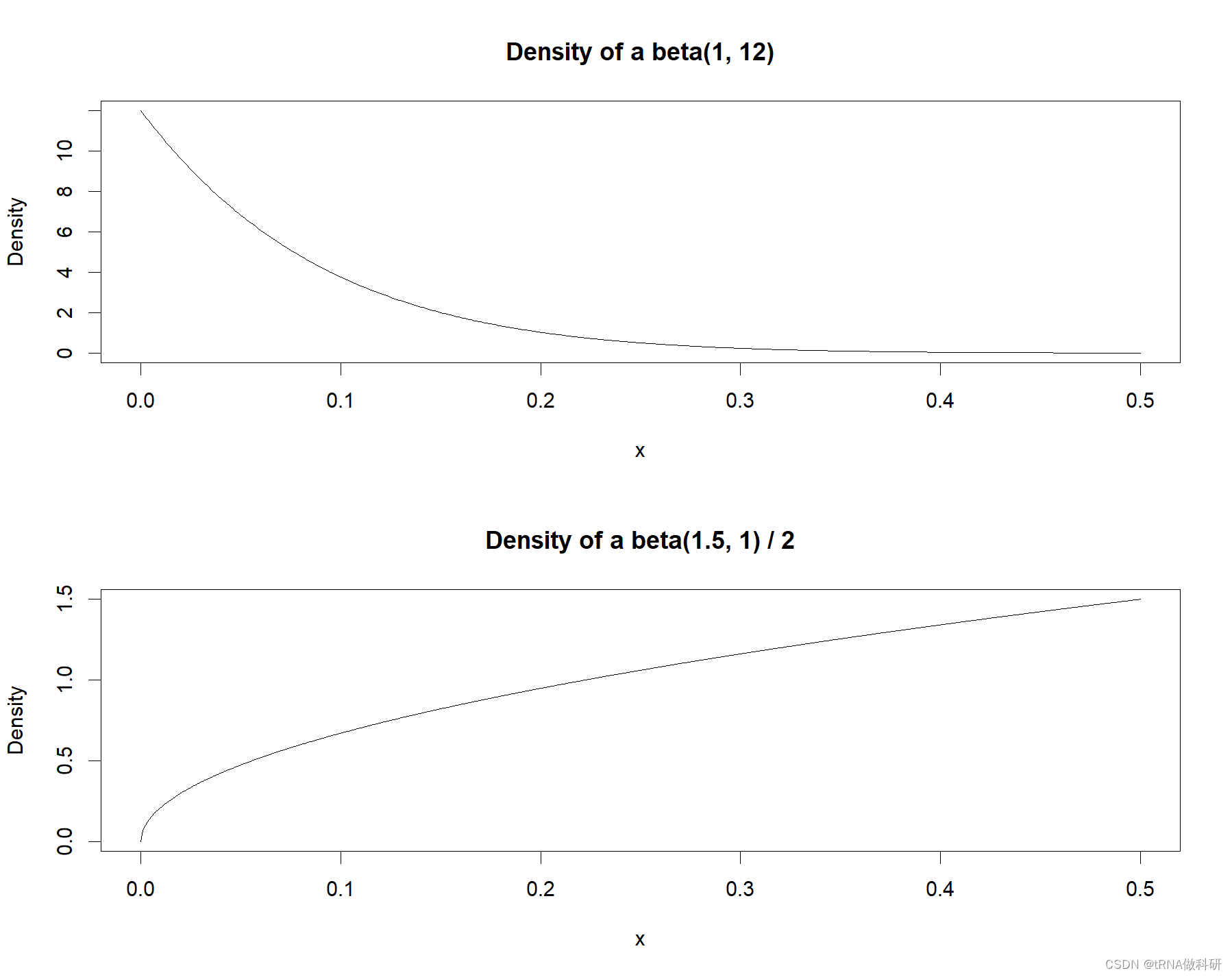
我们也可以使用随机搜索的方式进行超参数选择,下列代码画出了两个 beta 分布密度。通过在这些分布中抽样,我们能确保搜索,尽管是随机的,重点在于输入变量小比例的丢弃,而且在 0~0.50 的范围内对隐藏神经元来说,有一种趋势是从更接近 0.50 的值当中过抽样(oversample)
par(mfrow = c(2, 1))
plot(
seq(0, .5, by = .001),
dbeta(seq(0, .5, by = .001), 1, 12),
type = "l", xlab = "x", ylab = "Density",
main = "Density of a beta(1, 12)")
plot(
seq(0, 1, by = .001)/2,
dbeta(seq(0, 1, by = .001), 1.5, 1),
type = "l", xlab = "x", ylab = "Density",
main = "Density of a beta(1.5, 1) / 2")。
6.3 小结
原书中有更深入的讲解与例子,但是我觉得确实非常的难,不如在自己运用的过程中去体会运用。六篇教程学习完,应该是能轻松建立一个神经网络进行预测训练,如果还有其他问题,欢迎大家一起交流讨论,