目录
PySpark系列文章:
(四)PySpark3:Mlib机器学习实战-信用卡交易数据异常检测
一、Spark Mlib
本节内容根据我的另一篇文章:信用卡交易数据异常检测,将pandas+sklearn换成pyspark分布式场景。当训练数据量较大时,通过多台机器分布式计算可以极大程度上减少程序的运行时间。
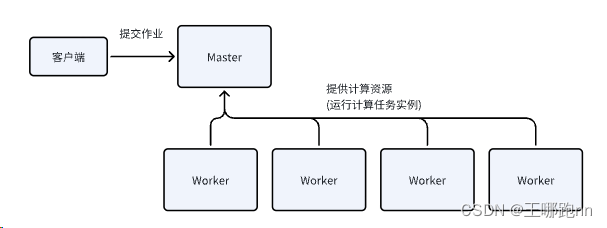
Spark Mlib,即Spark的机器学习库,是Apache Spark的一个核心组件,专为大规模数据处理和机器学习算法而设计。它提供了丰富的机器学习算法和工具,使数据科学家和开发人员能够轻松地在分布式环境中构建和训练机器学习模型。
PySpark Mlib提供了丰富的机器学习算法:
1、分类算法:包括逻辑回归、支持向量机(SVM)、决策树、随机森林等,用于对数据进行分类预测。
2、回归算法:如线性回归、岭回归、套索回归等,用于预测数值型目标变量的值。
3、聚类算法:如K-均值、谱聚类等,用于将数据集中的对象按照相似性进行分组。
4、协同过滤算法:用于推荐系统中,根据用户的历史行为和偏好进行个性化推荐。
二、案例背景以及数据集
信用卡欺诈是指以非法占有为目的,故意使用伪造、作废的信用卡,冒用他人的信用卡骗取财物,或用本人信用卡进行恶意透支的行为。
数据集“creditcard.csv”中的数据来自2013年9月由欧洲持卡人通过信用卡进行的交易。共284807行交易记录,其中数据文件中Class==1表示该条记录是欺诈行为,总共有 492 笔。输入数据中存在 28 个特征 V1,V2,……V28(通过PCA变换得到,不用知道其具体含义),以及交易时间 Time 和交易金额 Amount。
百度云链接:https://pan.baidu.com/s/1_GLiEEqIZqXVG7M1lcnewg
提取码:abcd
目标:构建一个信用卡欺诈分析的分类器。通过以往的交易数据分析出每笔交易是否正常,是否存在盗刷风险。
三、代码
1、初始化SparkSession
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import LogisticRegression, DecisionTreeClassifier, RandomForestClassifier
from pyspark.ml.evaluation import BinaryClassificationEvaluator
#初始化SparkSession
spark = SparkSession.builder.appName("CreditCardFraudDetection").getOrCreate() 2、读取数据
# 读取数据
data = spark.read.csv("creditcard.csv", header=True, inferSchema=True)
data = data.drop('Time', 'Amount').withColumnRenamed("Class","label")3、分离特征与标签
# 组装特征向量
vectorAssembler = VectorAssembler(inputCols=data.columns[:-1], outputCol="features")
data_with_vector = vectorAssembler.transform(data)
# 分离标签和特征
label_column = "label"
features_column = "features"
data_with_vector = data_with_vector.select(features_column, label_column) 4、下采样
# 划分训练集和测试集
(train_data, test_data) = data_with_vector.randomSplit([0.7, 0.3], seed=0)
# 计算少数类和多数类的数量
fraud_count = train_data.filter(train_data[label_column] == 1).count()
normal_count = train_data.filter(train_data[label_column] == 0).count()
# 下采样多数类以匹配少数类数量
downsampled_normal = train_data.filter(train_data[label_column] == 0).sample(False, fraud_count / normal_count)
# 合并下采样后的多数类样本和原始的少数类样本
balanced_train_data = downsampled_normal.union(train_data.filter(train_data[label_column] == 1)) 5、使用逻辑回归模型预测
# 训练逻辑回归模型
lr = LogisticRegression(labelCol=label_column)
lr_model = lr.fit(balanced_train_data)
lr_predictions = lr_model.transform(test_data)
evaluator = BinaryClassificationEvaluator(rawPredictionCol="rawPrediction")
print('逻辑回归AUC分数:', evaluator.evaluate(lr_predictions))6、使用决策树模型预测
# 训练决策树模型
dt = DecisionTreeClassifier(labelCol=label_column)
dt_model = dt.fit(balanced_train_data)
dt_predictions = dt_model.transform(test_data)
print('决策树AUC分数:', evaluator.evaluate(dt_predictions))7、使用随机森林模型预测
# 训练随机森林模型
rf = RandomForestClassifier(labelCol=label_column)
rf_model = rf.fit(balanced_train_data)
rf_predictions = rf_model.transform(test_data)
print('随机森林AUC分数:', evaluator.evaluate(rf_predictions))8、停止SparkSession
spark.stop()9、预测结果对比
逻辑回归AUC分数: 0.9646182832801895
决策树AUC分数: 0.938546748747307
随机森林AUC分数: 0.9858752161973708四、总结
Spark Mlib实现了在分布式大数据环境下的机器学习训练,并且可以通过Spark SQL对数据集进行数据预处理以及特征工程,可以高效处理大规模数据集。但是Spark Mlib目前支持的算法还比较少,支持的机器学习算法有限,而且并不直接支持深度学习算法。所以,选择Spark进行机器学习训练与预测,可能更多考量的是成本与时间优势,但是对于复杂建模场景或者对模型精度要求较高的场景,Spark将难以胜任。