部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索。
这节课程内容来自文章: FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
来自斯坦福的文章。
背景
减少大模型的调用成本,提高性能是很有意义的。一方面可以节约能源,为双碳战略提供支撑,另一方面可以开源节流。
这里算了一下使用GPT的成本:
输入:0.03$/1000 tokens
输出:0.06$/1000 tokens
假设每次使用输入1000 tokens、输出1000 tokens,那么每次使用需要 0.03$+0.06$=0.09$(2.78 新台币)
对于打访问量的需求,则可能会耗费巨资。例如:
具体做法有三种,文章主要讨论的是第三种方法。
法一:Prompt Adaptation 缩短输入
这个方法想办法在减少输入上下功夫。例如在做In-context learning的时候,为模型提供了两个实例:

那么可以考虑减少实例的个数,也就是Prompt Selection方法,但是文章中没有给出如何选择实例的方法:

通常还有一种情况,我们使用相同的Context,要生成不同的答案:
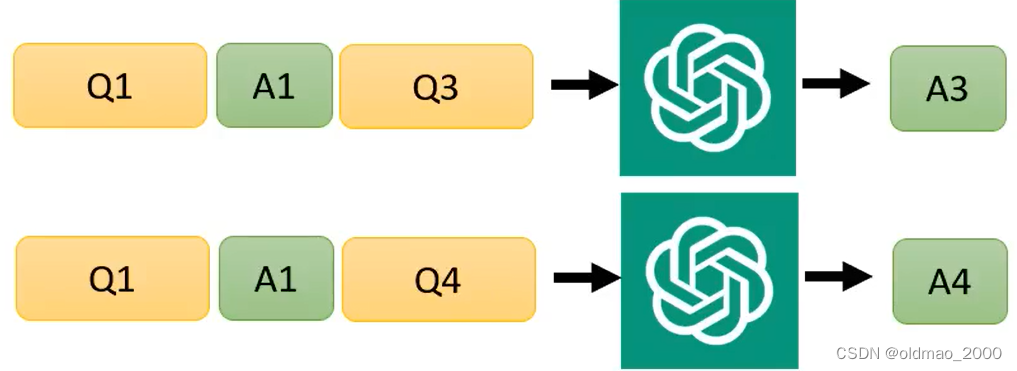
这个时候可以考虑使用Query Concatenation,把上面相同的部分结合起来:

这样就减少了Context的使用次数。
方法二:LLM Approximation 自建模型
自建模型的方法前面有提到过。但是自己训练模型还是要耗费一定的算力。这里提出一种更便宜,更没有技术含量的方法:Completion Cache
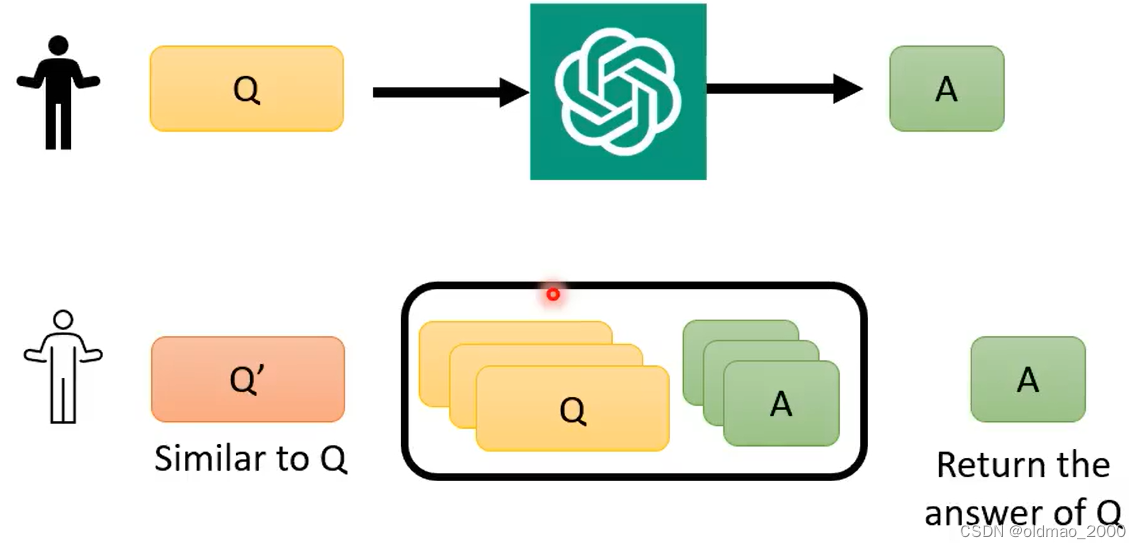
原理很简单,就是把问过GPT的问题和答案保存到数据库中,然后再有新的问题过来,先在数据库中进行查找即可。这个方法在某些大量重复提问的场景是比较有用的。
方法三:LLM cascade 大模型级联
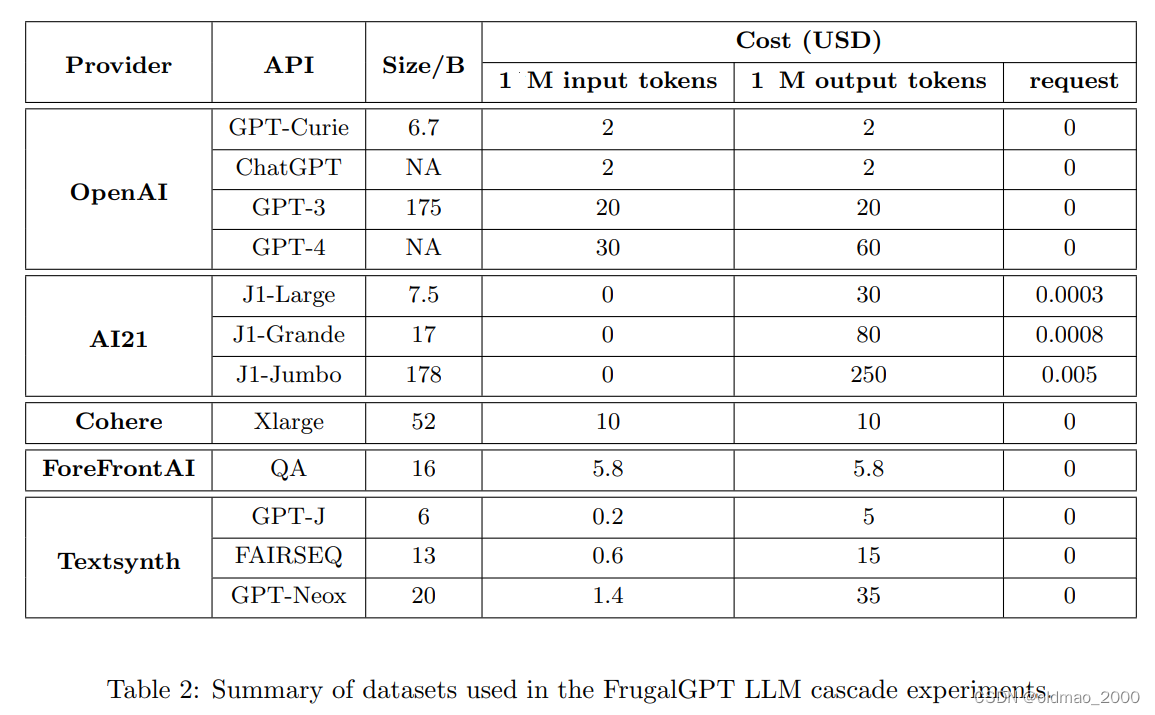
下表是当前各种大模型收费表,各种模型大小不一,收费标准当然也不同,输入和输出的收费标准也不一样。
这里的原则是:
简单的问题交给弱鸡模型(比较便宜)
复杂的问题交给强的模型(比较贵)
期望这样可以使得不同能力的模型可以互补。
原文给出了一个实验结果:

这个实验有三组,我们只看第一组,这个实验的数据集是HEADLINES,就是让模型读新闻的标题,然后根据标题判断黄金的走势。图中纵轴和横轴都是模型名称,交叉的数字表示纵轴模型判断失误但是横轴模型回答正确的几率,这个数字越小表示模型越强,但是还是有缺陷。因此,原文提出级联的模型:

这里的三个模型强弱关系为:GPT-J<J1-L<GPT-4,当输入经过GPT-J,得到一个answer,这里额外训练了一个很小的模型(验证模块)来计算answer的得分:
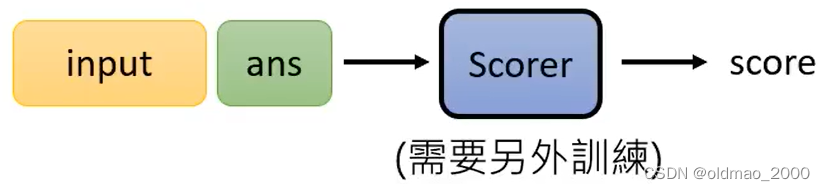
当结果得分大于某个域值,说明GPT-J回答正确,直接将ans of GPT-J作为结果进行输出,如果结果得分小于某个域值,则将问题带入下一个模型J1-L,以此类推,最后进入GPT-4。最后的结果表明,级联后在HEADLINES运行能有效降低成本且准确度有所提升:
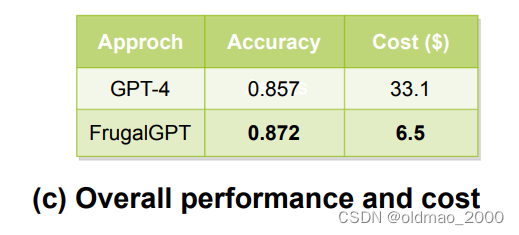
准确度提升是因为有6%的问题GPT-4会答错,但是GPT-J回答正确,这部分问题会被前置的GPT-J搞定。
那么我们应该选择哪些模型来级联效果才会更好?域值应该如何定才更合理?
接下来用数学表达来说明。
数学定义
假设模型为 L i L_i Li,输入为 q q q,模型输出为 L i ( q ) L_i(q) Li(q)
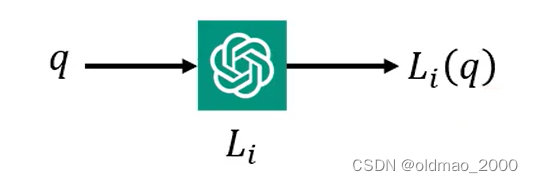
若正确答案表示为 a a a,则输入在模型 L i L_i Li的正确率可以表示为:
r ( a , L i ( q ) ) r(a,L_i(q)) r(a,Li(q))
验证模块的评分可表示为:
s ( q , L i ( q ) ) s(q,L_i(q)) s(q,Li(q))
模型的运行代价根据上面的调研表格可知:输入要钱、输出要钱、固定按次要钱。
c L i , 1 ∣ ∣ q ∣ ∣ + c L i , 2 ∣ ∣ L i ( q ) ∣ ∣ + c L i , 3 c_{L_i,1}||q||+c_{L_i,2}||L_i(q)||+c_{L_i,3} cLi,1∣∣q∣∣+cLi,2∣∣Li(q)∣∣+cLi,3
c L i , 1 − 3 c_{L_i,1-3} cLi,1−3表示不同模型不同输入输出以及固定次数的收费系数。
假设我们有 k k k个语言模型: L = { L 1 , L 2 , ⋯ , L k } \mathcal{L}=\{L_1,L_2,\cdots,L_k\} L={L1,L2,⋯,Lk}
前 k − 1 k-1 k−1个语言模型(最后一个模型不需要阈值)对应的阈值为: T = { λ 1 , λ 2 , ⋯ , λ k − 1 } \mathcal{T}=\{\lambda_1,\lambda_2,\cdots,\lambda_{k-1}\} T={λ1,λ2,⋯,λk−1}
则模型优化目标是要使得级联之后的模型最终的准确率越大越好:
max L , T ∑ q , a r ( a , L z ( q ) ) \max_{\mathcal{L},\mathcal{T}}\sum_{q,a}r(a,L_z(q)) L,Tmaxq,a∑r(a,Lz(q))
其中 z z z是穷举所有模型能够达到模型输出 s ( q , L i ( q ) ) s(q,L_i(q)) s(q,Li(q))对应分数大于 λ i \lambda_i λi,在其中选出最小的下标 i i i作为 z z z
另外一个目标是总体cost越小越好:
∑ q ∑ i = 1 z [ c L i , 1 ∣ ∣ q ∣ ∣ + c L i , 2 ∣ ∣ L i ( q ) ∣ ∣ + c L i , 3 ] < B \sum_q\sum_{i=1}^z[c_{L_i,1}||q||+c_{L_i,2}||L_i(q)||+c_{L_i,3}]<B q∑i=1∑z[cLi,1∣∣q∣∣+cLi,2∣∣Li(q)∣∣+cLi,3]<B
B B B是我们的预算, z z z是模型的个数
结果
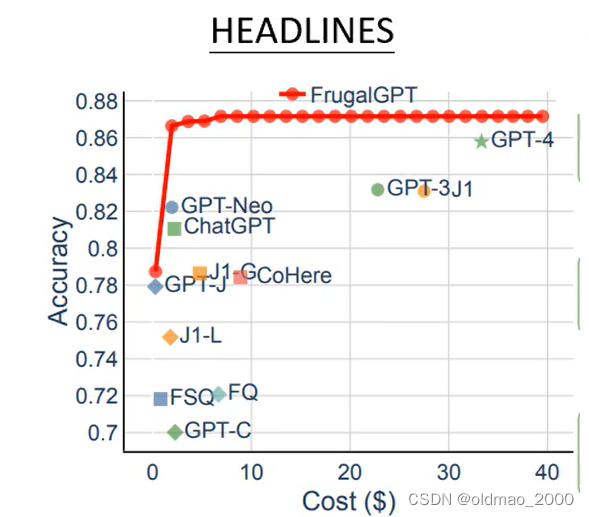
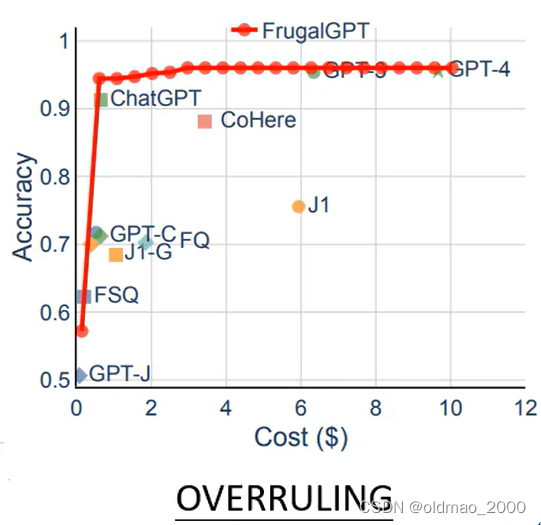
overruling是判断当前法律条文是否包含或覆盖其他法律条文。
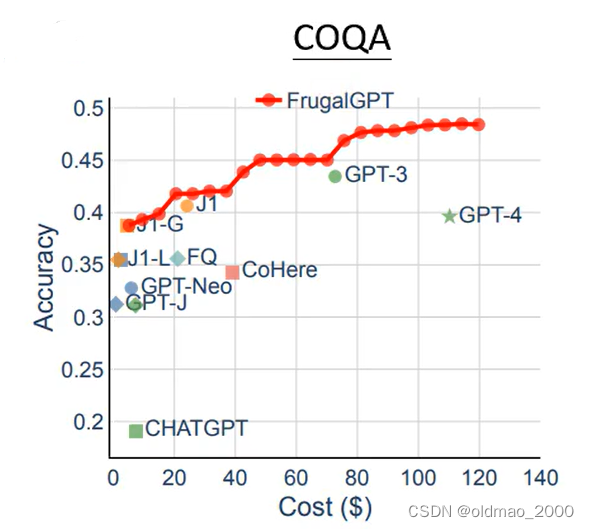
COQA是问答任务。
三个数据集中横轴都是花费,纵轴是正确率。
三个任务都是GPT-4花费最高,但是其在第三个任务上居然比GPT-3差