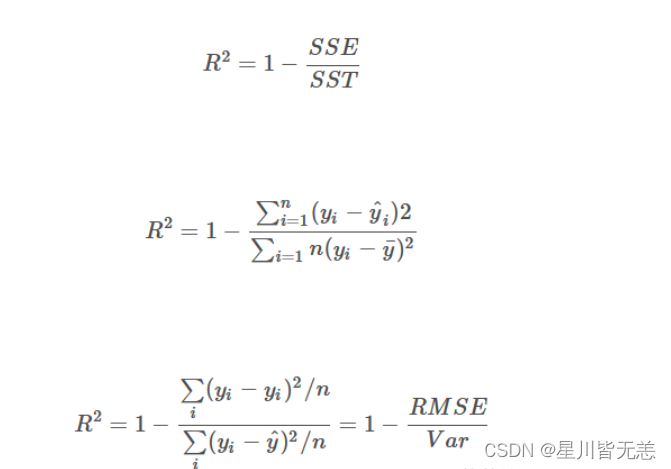机器学习中的数学原理——模型评估与交叉验证
1. 背景介绍
在机器学习中,模型评估和交叉验证是两个非常重要的概念。模型评估用于评估模型的性能,而交叉验证用于评估模型的泛化能力。这两个概念在机器学习领域中具有广泛的应用,对于提高模型的准确性和可靠性具有重要意义。
2. 核心概念与联系
2.1 模型评估
模型评估是指使用已知的数据集来评估模型的性能。通常,我们会使用一些指标来衡量模型的性能,如准确率、召回率、F1分数等。这些指标可以帮助我们了解模型的优缺点,从而对模型进行优化。
2.2 交叉验证
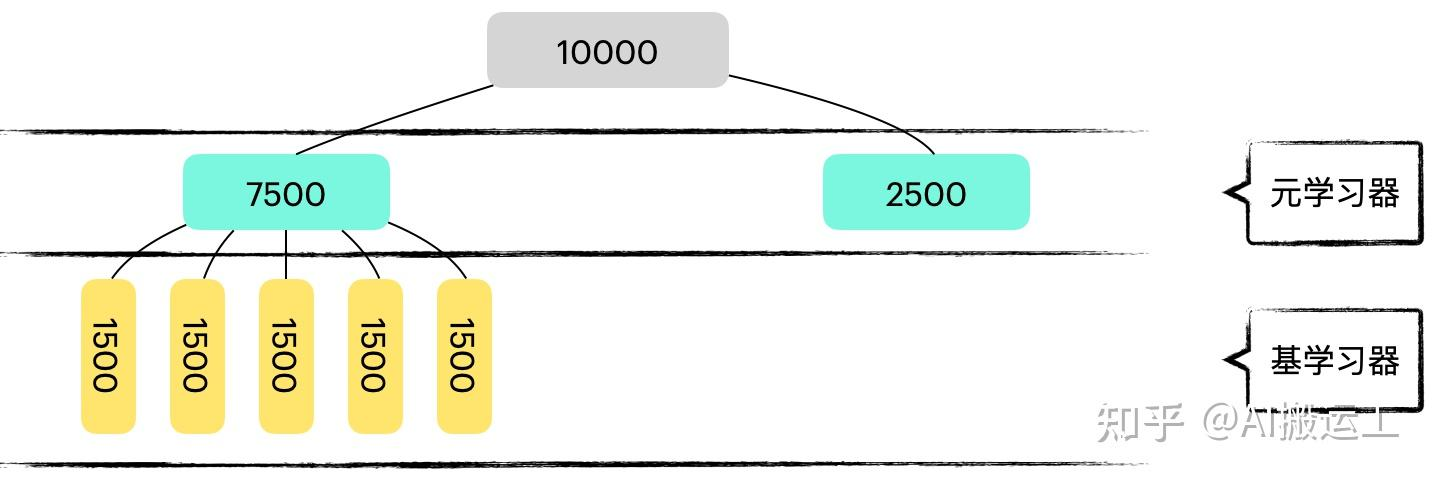
交叉验证是一种评估模型泛化能力的方法。它将数据集分为多个子集,然后使用其中一个子集作为训练集,其余子集作为测试集。通过多次重复这个过程,我们可以得到多个模型评估结果,从而得到一个更可靠的评估结果。
2.3 核心概念联系
模型评估和交叉验证是相辅相成的。模型评估用于评估模型的性能,而交叉验证用于评估模型的泛化能力。通过交叉验证,我们可以得到一个更可靠的模型评估结果,从而对模型进行优化。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 核心算法原理
交叉验证的核心算法原理是将数据集分为多个子集,然后使用其中一个子集作为训练集,其余子集作为测试集。通过多次重复这个过程,我们可以得到多个模型评估结果,从而得到一个更可靠的评估结果。
3.2 具体操作步骤
- 将数据集分为多个子集。
- 选择一个子集作为训练集,其余子集作为测试集。
- 使用训练集训练模型。
- 使用测试集评估模型性能。
- 重复步骤2-4,直到所有子集都作为测试集使用过。
- 汇总所有模型评估结果,得到最终评估结果。
3.3 数学模型公式详细讲解
在交叉验证中,我们通常使用准确率作为评估指标。准确率的计算公式为:
准确率 = T P + T N T P + F P + F N + T N 准确率 = \frac{TP + TN}{TP + FP + FN + TN} 准确率=TP+FP+FN+TNTP+TN
其中,TP表示真正例,TN表示真负例,FP表示假正例,FN表示假负例。
4. 具体最佳实践:代码实例和详细解释说明
4.1 代码实例
以下是一个使用Python和scikit-learn库进行交叉验证的代码实例:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 创建SVM模型
svm = SVC(kernel='linear')
# 进行交叉验证
scores = cross_val_score(svm, X, y, cv=5)
# 输出交叉验证结果
print("交叉验证结果:", scores)
4.2 详细解释说明
在这个代码实例中,我们首先加载了iris数据集,然后创建了一个SVM模型。接着,我们使用cross_val_score函数进行了交叉验证,并输出了交叉验证结果。
5. 实际应用场景
交叉验证和模型评估在许多实际应用场景中都有广泛的应用。例如,在金融风控、医疗诊断、推荐系统等领域,都需要使用交叉验证和模型评估来提高模型的准确性和可靠性。
6. 工具和资源推荐
在机器学习中,有许多工具和资源可以帮助我们进行模型评估和交叉验证。以下是一些推荐的工具和资源:
- scikit-learn:一个强大的机器学习库,提供了许多模型评估和交叉验证的功能。
- Kaggle:一个数据科学竞赛平台,提供了许多实际的数据集和竞赛,可以帮助我们练习模型评估和交叉验证。
- TensorFlow和PyTorch:两个流行的深度学习框架,也提供了模型评估和交叉验证的功能。
7. 总结:未来发展趋势与挑战
模型评估和交叉验证在机器学习领域中具有重要的地位。随着技术的不断发展,未来模型评估和交叉验证可能会出现以下趋势和挑战:
- 自动化:随着自动化技术的不断发展,模型评估和交叉验证可能会变得更加自动化,从而提高效率和准确性。
- 集成学习:集成学习是一种将多个模型组合在一起的方法,未来模型评估和交叉验证可能会更加关注集成学习的方法。
- 数据隐私和安全:随着数据隐私和安全问题的日益突出,模型评估和交叉验证可能会更加关注数据隐私和安全的问题。
8. 附录:常见问题与解答
8.1 问题1:交叉验证和模型评估有什么区别?
答:交叉验证是一种评估模型泛化能力的方法,而模型评估是一种评估模型性能的方法。交叉验证通过将数据集分为多个子集,使用其中一个子集作为训练集,其余子集作为测试集,来评估模型的泛化能力。而模型评估则直接使用整个数据集来评估模型的性能。
8.2 问题2:交叉验证和K折交叉验证有什么区别?
答:交叉验证和K折交叉验证都是评估模型泛化能力的方法。交叉验证是将数据集分为多个子集,然后使用其中一个子集作为训练集,其余子集作为测试集。而K折交叉验证是将数据集分为K个等大的子集,然后使用其中一个子集作为训练集,其余子集作为测试集,重复这个过程K次。
8.3 问题3:如何选择合适的交叉验证方法?
答:选择合适的交叉验证方法需要根据具体的问题和数据集来决定。一般来说,如果数据集较小,可以使用较少的交叉验证方法,如K折交叉验证。如果数据集较大,可以使用更多的交叉验证方法,如留出法或自助法。此外,还可以根据具体的问题和数据集的特点来选择合适的交叉验证方法。