Spring Boot 中的 Sleuth 是一个用于分布式追踪的库,它可以帮助你追踪和理解分布式系统中的请求如何跨越多个服务和网络调用。通过使用 Sleuth,你可以收集关于请求路径、延迟、异常等的信息,从而更容易地诊断问题并进行性能优化。

一、下面是关于 Spring Boot 中 Sleuth 的详细解释
1. 基本概念
- Span:代表一个基本的工作单元,例如一个 HTTP 请求或一个数据库调用。每个 Span 都有一个唯一的 ID 和一个可选的父 Span ID。
- Trace:一系列相互关联的 Span,通常表示一个完整的请求或操作。每个 Trace 都有一个唯一的 ID。
2. 如何在 Spring Boot 中使用 Sleuth
2.1 添加依赖
在你的 pom.xml 或 build.gradle 文件中添加 Spring Cloud Sleuth 的依赖。
2.2 启用 Sleuth
在 Spring Boot 应用程序中,只需添加依赖即可启用 Sleuth。默认情况下,它会自动为你的应用程序添加跟踪和跨度信息。
2.3 自定义配置
你可以通过 application.properties 或 application.yml 文件来配置 Sleuth,例如设置采样率、日志级别等。
3. 集成其他系统
- Zipkin:Sleuth 可以与 Zipkin 集成,将跟踪数据发送到 Zipkin 服务器进行存储和查询。Zipkin 提供了一个用户界面,允许你查看和分析跟踪数据。
- 其他跟踪系统:除了 Zipkin,Sleuth 还可以与其他跟踪系统集成,如 Jaeger。
4. 注意事项
- 性能开销:由于 Sleuth 需要收集和处理跟踪数据,因此可能会引入一定的性能开销。在生产环境中,你可能需要仔细配置采样率以平衡性能和诊断需求。
- 安全性:确保跟踪数据的安全性和隐私性。不要记录敏感信息,如密码、令牌等。
5. 诊断和调优
通过查看和分析 Sleuth 收集的跟踪数据,你可以识别和解决分布式系统中的问题,例如延迟、瓶颈、错误等。你还可以使用这些数据来优化你的应用程序和服务。
Sleuth 的核心概念
在使用 Sleuth 之前,我们需要了解一些核心概念:
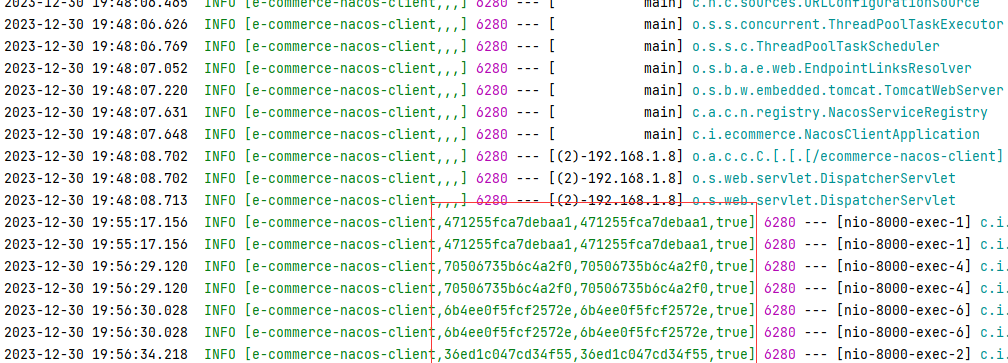
Trace(跟踪):一个 Trace 表示一个请求或操作的完整的调用链,从客户端发起请求开始,到服务端响应请求结束。
Span(跨度):一个 Span 表示一个请求或操作的一部分,它包含了一些有用的信息,如开始时间、结束时间、操作名称等。
Trace ID(跟踪 ID):一个 Trace ID 是一个唯一的标识符,它用于将一组 Span 关联在一起,形成一个完整的 Trace。
Span ID(跨度 ID):一个 Span ID 是一个唯一的标识符,它用于标识一个 Span。
在 Sleuth 中,每个请求或操作都会生成一个 Trace,并且每个 Trace 包含多个 Span。每个 Span 包含一个唯一的 Span ID,并与一个 Trace ID 相关联。通过 Trace ID 和 Span ID,我们可以将多个 Span 关联在一起,形成一个完整的 Trace。
二、Sleuth在springboot中的使用
pom文件
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>添加依赖后,Sleuth 就会自动启用,并开始跟踪应用程序中的请求和操作。Sleuth 会自动为每个请求或操作生成一个 Trace,并为每个 Trace 中的每个 Span 生成一个唯一的 Span ID。
Sleuth就想一个更完整的日志生成器。
自定义 Sleuth 配置
在使用 Sleuth 时,我们可以通过配置文件或编程方式进行自定义配置。以下是一些常用的自定义配置方式:
配置 Trace 和 Span 的名称
默认情况下,Sleuth 会为每个 Trace 和Span 分别使用应用程序的名称和随机生成的 ID。如果需要自定义 Trace 和 Span 的名称,可以在 application.properties(或 application.yaml)文件中添加以下配置:
spring.sleuth.enabled=true
创建服务:创建一个简单的 Spring Boot 应用程序,例如一个 REST 服务。在这个服务中,添加一些请求处理逻辑,并启动应用程序。Sleuth 将自动为这些请求添加跟踪信息。
集成 Zipkin:如果要使用 Zipkin 来收集和展示跟踪数据,还需要集成 Zipkin。首先,下载并启动 Zipkin 服务。然后,在 Sleuth 的配置中指定 Zipkin 的地址,以便 Sleuth 将跟踪数据发送到 Zipkin。
在 application.properties 文件中添加以下配置以集成 Zipkin:
spring.zipkin.base-url=http://localhost:9411/
spring.sleuth.sampler.probability=1.0 # 设置采样率为 1.0,即所有请求都被跟踪确保 Zipkin 服务正在运行,并且 URL 是正确的。
发送请求并查看跟踪:现在,当向你的 Spring Boot 应用程序发送请求时,Sleuth 将生成跟踪数据。如果启用了 Zipkin 集成,这些数据将被发送到 Zipkin 服务器。你可以通过访问 Zipkin 的 Web 界面(通常是
http://localhost:9411)来查看和分析跟踪数据。分析跟踪数据:在 Zipkin 的 Web 界面上,你可以看到每个请求的详细信息,包括请求的链路图、时间戳、延迟等。这些信息可以帮助你分析性能瓶颈、错误和延迟问题。