PrefixEncoder
class PrefixEncoder(torch.nn.Module):
"""
The torch.nn model to encode the prefix
Input shape: (batch-size, prefix-length)
Output shape: (batch-size, prefix-length, 2*layers*hidden)
"""
def __init__(self, config: ChatGLMConfig):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
kv_size = config.num_layers * config.kv_channels * config.multi_query_group_num * 2
self.embedding = torch.nn.Embedding(config.pre_seq_len, kv_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(kv_size, config.hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.hidden_size, kv_size)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len,
config.num_layers * config.kv_channels * config.multi_query_group_num * 2)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
ChatGLMPreTrainedModel
class ChatGLMPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
is_parallelizable = False
supports_gradient_checkpointing = True
config_class = ChatGLMConfig
base_model_prefix = "transformer"
_no_split_modules = ["GLMBlock"]
def _init_weights(self, module: nn.Module):
"""Initialize the weights."""
return
def get_masks(self, input_ids, past_key_values, padding_mask=None):
batch_size, seq_length = input_ids.shape
full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
full_attention_mask.tril_()
past_length = 0
if past_key_values:
past_length = past_key_values[0][0].shape[0]
if past_length:
full_attention_mask = torch.cat((torch.ones(batch_size, seq_length, past_length,
device=input_ids.device), full_attention_mask), dim=-1)
if padding_mask is not None:
full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
if not past_length and padding_mask is not None:
full_attention_mask -= padding_mask.unsqueeze(-1) - 1
full_attention_mask = (full_attention_mask < 0.5).bool()
full_attention_mask.unsqueeze_(1)
return full_attention_mask
def get_position_ids(self, input_ids, device):
batch_size, seq_length = input_ids.shape
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
return position_ids
def _set_gradient_checkpointing(self, module, value=False):
if isinstance(module, GLMTransformer):
module.gradient_checkpointing = value
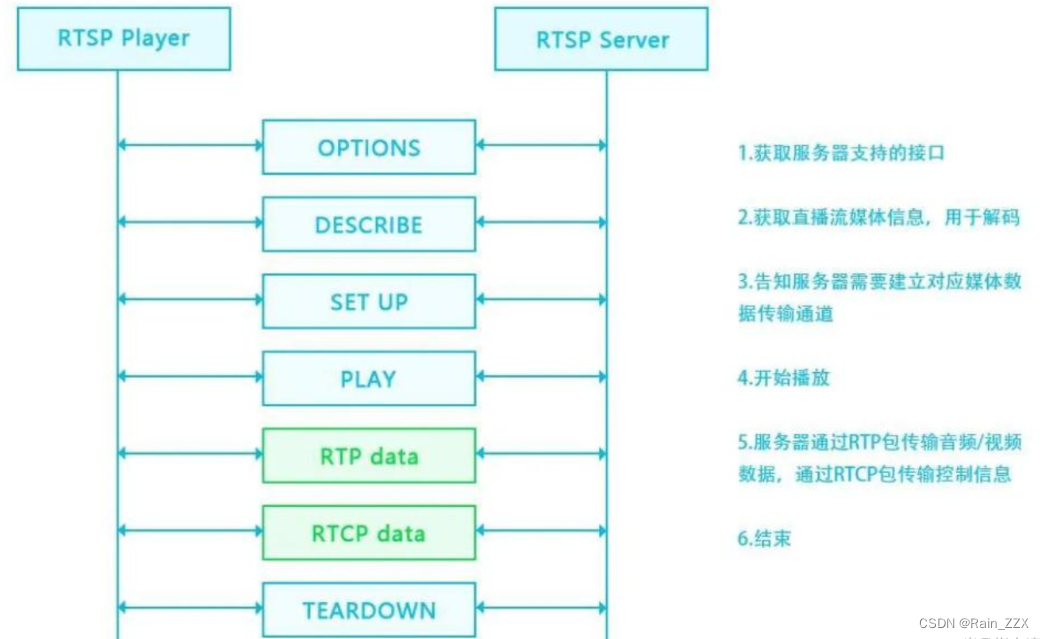
ChatGLMForConditionalGeneration.stream_generate()
@torch.inference_mode()
def stream_generate(
self,
input_ids,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
return_past_key_values=False,
**kwargs,
):
batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
model_kwargs["use_cache"] = generation_config.use_cache
bos_token_id, eos_token_id = generation_config.bos_token_id, generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
"This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
" recommend using `max_new_tokens` to control the maximum length of the generation.",
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
if not has_default_max_length:
logger.warn(
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
"Please refer to the documentation for more information. "
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
" increasing `max_new_tokens`."
)
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = self._get_stopping_criteria(
generation_config=generation_config, stopping_criteria=stopping_criteria
)
logits_warper = self._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
unfinished_sequences = unfinished_sequences.mul(
next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
)
if return_past_key_values:
yield input_ids, outputs.past_key_values
else:
yield input_ids
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
break