运动想象迁移学习系列:MSFT
论文地址:https://www.sciencedirect.com/science/article/abs/pii/S1746809422005249#aep-article-footnote-id1
论文题目:Excellent fine-tuning: From specific-subject classification to cross-task classification for motor imagery
论文代码:暂未找到
0. 引言
随着深度学习的普及,基于特征提取器和分类器的运动意象脑电图(MI-EEG)识别表现良好。然而,大多数模型提取的特征没有足够的区分性,仅限于特定主题分类。我们提出了一种新的模型,基于度量的空间滤波变压器(MSFT),该模型利用加性角裕量损失来强制实施深度模型,以提高类间可分离性,同时增强类内的紧凑性。此外,在模型中应用了一种称为脑电图金字塔的数据增强方法。
1. 主要贡献
- 基于
微调的算法具有加性角裕度损失,可以解耦特征提取器和分类器的训练,以提取更具通用性和辨别性的特征。 - 提出了一种新的
数据增强方法,即脑电图金字塔,它可以从脑电图中的多个时间窗口探索局部信息。 - 该方法不仅在
特定主题分类方面优于近年来许多流行的算法,而且无缝地适应了跨主题甚至跨任务的分类。
2. 数据增强方法
本文提出了一种数据增强方法:脑电图金字塔。脑电图金字塔结构的主要操作流程如下图所示:

主要包含以下操作步骤:
- 记原始脑电信号为 ( S , T ) (S, T) (S,T)。 其中, S S S 表示
脑电通道数, T T T 表示脑电信号采集时间(数据点个数)。 - 将原始信号记为第0层,依次对下一层信号进行
上采样。上采样率为: 1 + l ( m − 1 ) c − 1 1+\frac{l(m-1)}{c-1} 1+c−1l(m−1)。其中, m m m表示上采样率, c c c表示金字塔层数。使用SciPy库signal.resample来实现上采样。 - 用连续的 T T T数据点
随机截取每层的脑电样本。 - 将截获的所有层的脑电图堆叠在
新的第三维空间(空间维度为c)中,作为脑电图金字塔样本。 - 由于
截取的随机性,试验脑电图数据可以生成多个不同的脑电图金字塔样本。我们将此样本增强参数标记为 M。
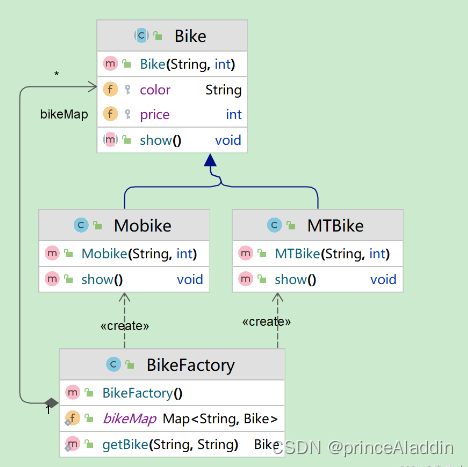
3. 基于度量的空间滤波转换器
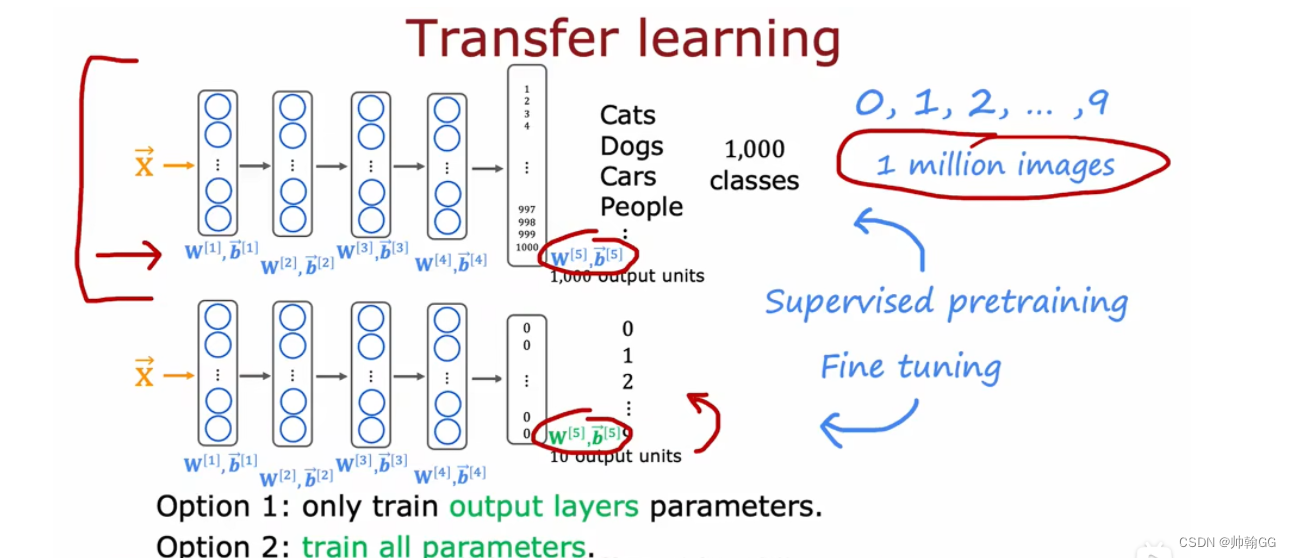
通过空间滤波将脑电图原始数据转化为中间时空表示,然后通过脑电图金字塔作为ViT的输入,转化为时空金字塔样本。作为特征提取器,ViT 输出一组高级判别特征,这些特征通过加性角裕量损失进行优化。训练特征提取器后,继续训练多层感知器 (MLP) 作为分类器。完整的 MSFT 过程图 2 所示。

(a) 空间滤波将脑电图原始数据转换为时空金字塔样本。
(b) 基于度量的脑电图ViT包括特征提取器和分类器。
(c)ArcFace损失提高了类间的可分离性,有利于提高分类精度。
3.1 空间过滤
按照论文内容的意思:这里的空间滤波就是一个OVR-CSP结构,就不再展开说了。
3.2 脑电图ViT
深度模型EEG ViT由三部分组成:段嵌入层、变压器编码器层和分类头层。输入通过线段嵌入层转换为具有特定形状的嵌入(存在困惑,不知道为啥非要这样做?)。然后,通过变压器编码器层提取隐藏特征,通过平均得到e区分特征;同时,存在基于指标的损失,以增强类内紧密性和类间差异。训练完两层后,我们冻结两层的参数,继续训练分类头层。
3.2.1 变压器编码器层
变压器编码器层结构如下所示:

3.2.2 基于度量的损失函数
基于指标的损失函数 ArcFace 损失派生自 Softmax loss。Softmax loss表示如下:

传统的 Softmax loss 在应用于分类时,并没有明确优化深度特征,以加强类内相似性和类间差异。而ArcFace损失的计算公示如下所示:

softmax 损失在嵌入决策边界的可分离特征上产生明显的模糊性,而 ArcFace 损失显然可以在最接近的类之间强制执行更明显的间隙,如图 4 所示。

4. 实验结果
4.1 消融实验
消融实验结果如下表所示:

无空间滤波:我们直接将脑电图原始数据发送到脑电图金字塔后给脑电图ViT,后续过程保持不变。ResNet18 特征提取器:如果直接省略 EEG ViT 的处理,则无法提取深层特征。因此,我们使用另一个高效的主干网 ResNet 来提取特征。基于 ResNet 庞大的参数和较长的训练时间,最轻量级的 ResNet18 有足够的深度信息挖掘能力。变压器编码器编号(r = 1 和 r = 5):变压器编码器的数量表示网络深度。我们探讨了变压器编码器模块的深度对结果的影响。无 ArcFace 损失:我们移除了 ArcFace 损失模块,这样提取的特征就不需要等待训练完成才发送到分类器。换句话说,特征提取器和分类器处于同一训练阶段。
结果表明,空间滤波对解码确实有很大的正向作用,其空间增强有助于特征更具判别性。此外,在我们的方法中,EEG ViT作为特征提取器是比ResNet更好的骨干。 变压器中的注意力机制更适合解码脑电图等时间序列数据。变压器的深度对解码性能有轻微影响。但是,这并不意味着网络越深,分类精度就越高。ArcFace损失对结果的明显影响表明,它促进了深层特征的类内聚类和类间差异。
4.2 基线任务对比
为了突出我们方法的有效性,在IV-2a和IV-2b数据集上与一些特定受试者的基准方法进行了比较,如表2所示。

4.3 跨主体
跨主体训练需要使用一个主体的数据训练 ArcFace 损失中的段嵌入层、transformer 编码器层和参数,然后修复这些参数,然后使用另一个主体的数据微调分类头层。
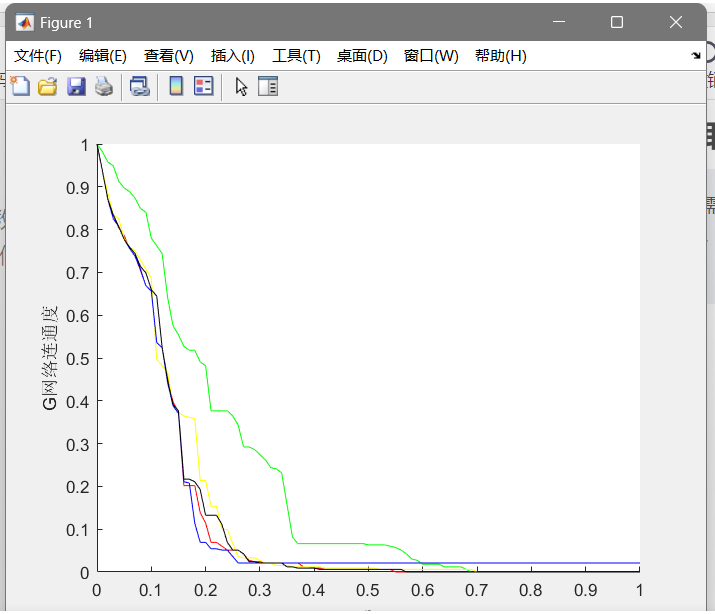
跨主体训练包含两个训练步骤:训练特征提取器是第一个训练阶段,微调分类头是第二个训练阶段。我们使用一个受试者的数据进行第一阶段的训练,然后分别使用其他受试者的数据完成第二阶段的训练。在IV-2a数据集上获得的结果如图6所示。

从结果可以看出,除了平均准确率为56.88%的跨受试者4外,其他跨受试者结果均超过60%。
5. 总结
到此,使用 MSFT已经介绍完毕了!!! 如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。
如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。
欢迎来稿
欢迎投稿合作,投稿请遵循科学严谨、内容清晰明了的原则!!!! 有意者可以后台私信!!