摘要
https://arxiv.org/pdf/2203.11926.pdf
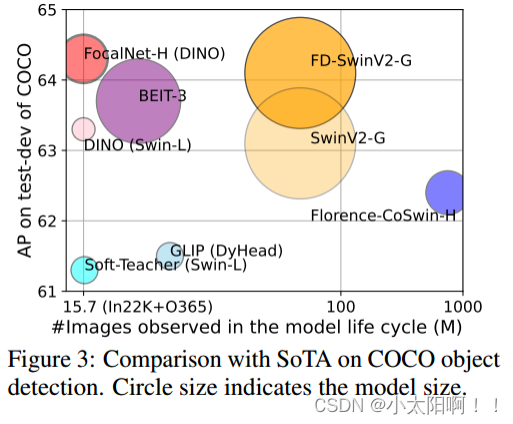
我们提出了焦点调制网络(简称FocalNets),其中自注意力(SA)被焦点调制模块完全取代,用于在视觉中建模令牌交互。焦点调制包含三个组件:(i)焦点上下文化,通过堆叠深度卷积层实现,以从短到长范围编码视觉上下文;(ii)门控聚合,用于选择性地收集上下文信息到每个查询令牌的调制器中;(iii)元素级仿射变换,将调制器注入查询中。大量实验表明,FocalNets表现出非凡的可解释性(如图1所示),并在图像分类、目标检测和分割等任务上,以类似的计算成本超越了SoTA SA对应项(例如Swin和Focal Transformers)。具体来说,具有tiny和base大小的FocalNets在ImageNet-1K上可以达到 82.3 % 82.3\% 82.3%和






























![[媒体宣传]上海有哪些可以邀约的新闻媒体资源汇总](https://img-blog.csdnimg.cn/direct/b60365536b9a421ebeecf14e0a197e59.jpeg)