Apache Kafka能够实现高吞吐量的原因归结于其独特的设计和架构选择。以下是几个关键因素:
1. 批处理
Kafka将消息以批的形式处理和存储。这意味着生产者将多个消息打包成一个批次,然后一次性发送。同样,消费者也可以批量地拉取和处理消息。批处理减少了网络调用的次数,提高了I/O效率。
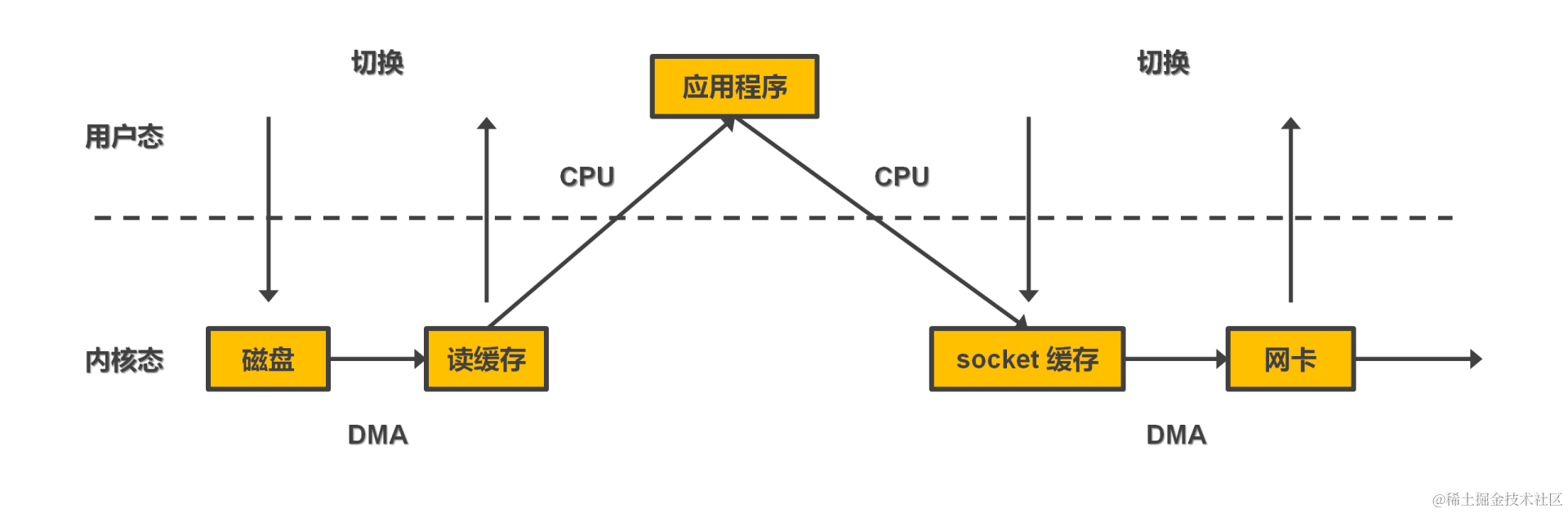
2. 零拷贝技术(Zero-Copy)
Kafka利用了操作系统的零拷贝(Zero-Copy)特性来传输数据。这意味着在从磁盘读取数据并发送给消费者时,可以避免在用户空间和内核空间之间多次拷贝数据,减少了CPU的消耗以及数据传输的延迟。
3. 顺序写入磁盘
消息在Kafka的存储文件(CommitLog)中是顺序写入的。顺序写入比随机写入更高效,因为它最小化了磁盘寻道时间,使得磁盘I/O操作更快。
4. 数据持久化和复制
Kafka通过将数据持久化到磁盘并且在集群中的多个节点之间复制数据来确保消息的可靠性。尽管数据复制可能听起来会降低性能,但Kafka通过高效的算法和策略(如异步复制)确保了这一过程对吞吐量的影响最小。
5. 分区和负载均衡
Kafka的Topic可以被划分为多个分区,这些分区可以分布在集群中的不同服务器上。这样不仅可以在物理上并行处理数据,还可以在多个消费者之间平衡负载,进一步提高了吞吐量。
6. 水平扩展
Kafka集群可以通过增加更多的服务器来轻松扩展。这意味着当需要处理更多数据时,可以通过增加Broker节点来增加系统的整体吞吐量,而无需对现有的应用架构进行重大修改。
7. 消费者组和消息偏移量
Kafka通过消费者组来管理消费者实例,每个消费者组内的消费者可以订阅一个或多个Topic,并且Kafka会跟踪每个消费者对每个分区的消息偏移量。这样,即使在高负载的情况下,也可以保证消息被有效处理,而不会造成消息的丢失或重复。
8. 高效的文件存储格式
Kafka直接在文件系统上存储消息数据,采用一种高效的存储格式,这不仅保证了快速的数据访问速度,还优化了存储空间的使用。
通过上述设计和技术,Kafka能够实现高吞吐量的数据处理,满足大规模、高性能应用的需求。































![[媒体宣传]上海有哪些可以邀约的新闻媒体资源汇总](https://img-blog.csdnimg.cn/direct/b60365536b9a421ebeecf14e0a197e59.jpeg)




