复习回顾:
01.浏览器
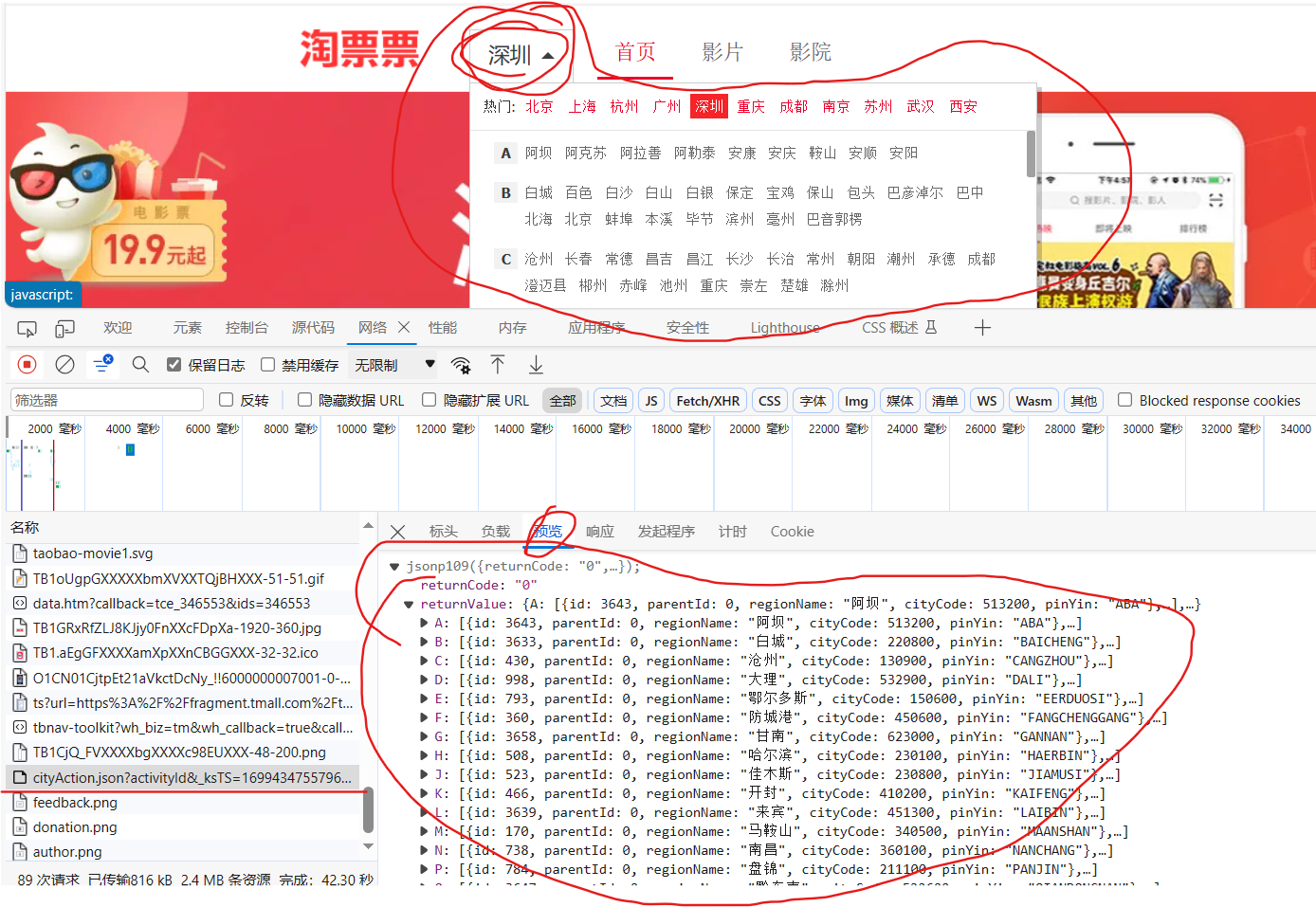
一个网页的加载全过程
1. 服务器端渲染
html的内容和数据在服务器进行融合.
在浏览器端看到的页面源代码中. 有你需要的数据
2. 客户端(浏览器)渲染
html的内容和数据进行融合是发生在你的浏览器上的.
这个过程一般通过脚本来完成(javascript)
我们通过浏览器可以看到上述加载过程
02.requests -> 模拟成浏览器的样子
requests模块是python的一个非常完善的一个第三方模块
专门用来模拟浏览器进行网络请求的发送
协议
http://www