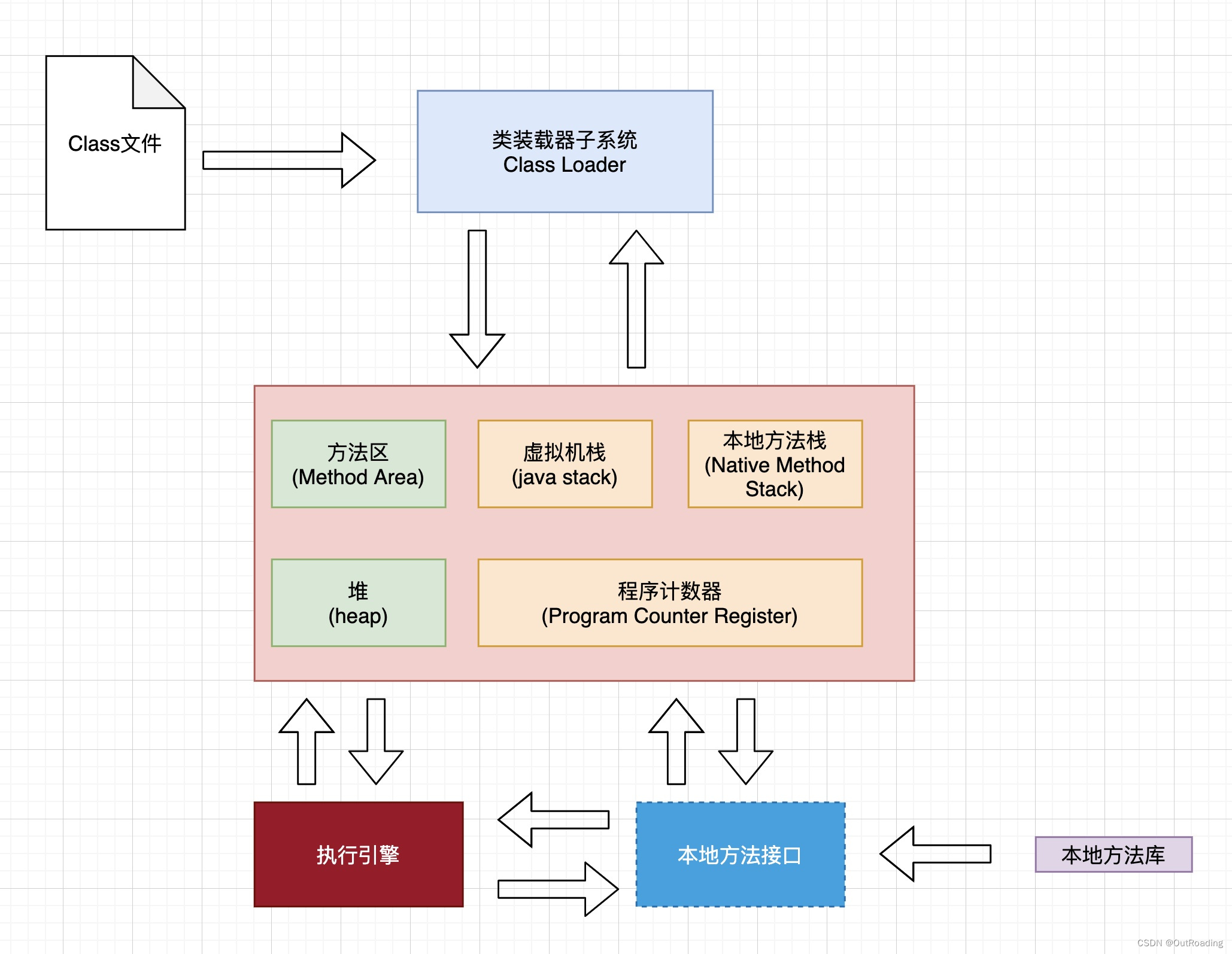
一、认识NOSQL
1.1关系型数据库
关系型数据库(Relational Database),基于关系模式创建的二维表格模型。缺点:
- ·结构化的数据模型不利于扩展与变更
- ·关系/范式降低了查询效率(过度并表查询)
- ·处理海量数据
- ·分布式主备模式
1.2非关系型数据库
非关系型数据库(NoSQL, Not Only SQL),用于存储非结构化数据的数据库系统。增强了数据结构的可扩展性,内存数据库增强了操作效率与速度。类型:
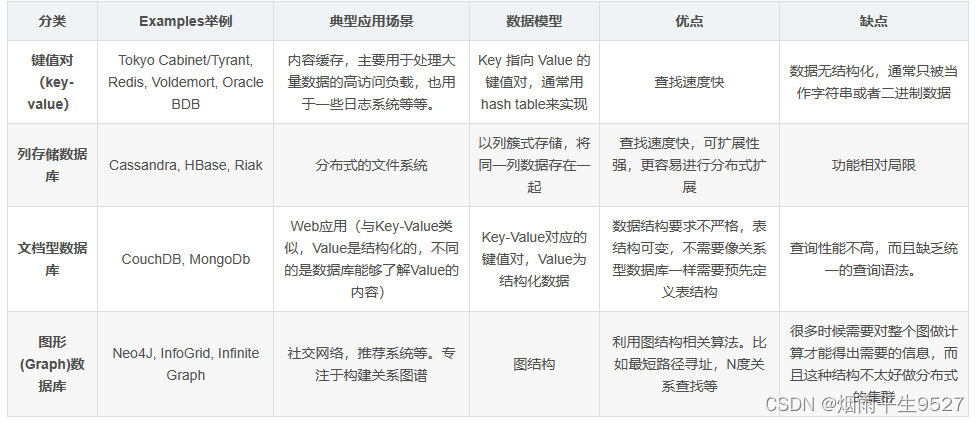
- 键值型数据库(Redis)
- 文档型数据库(MongoDB/Redis7+)
- 列族型数据库(BHBase)
- Graph:类型(Neo4j)
# 商品信息
- 一般存放在关系型数据库:Mysql,阿里巴巴使用的Mysql都是经过内部改动的。
# 商品描述、评论(文字居多)
- 文档型数据库:MongoDB
# 图片
- 分布式文件系统 FastDFS
- 淘宝:TFS
- Google: GFS
- Hadoop: HDFS
- 阿里云: oss
# 商品关键字 用于搜索
- 搜索引擎:solr,elasticsearch
- 阿里:Isearch 多隆
# 商品热门的波段信息
- 内存数据库:Redis,Memcache
# 商品交易,外部支付接口
- 第三方应用
Nosql的四大分类
KV键值对
- 新浪:Redis
- 美团:Redis + Tair
- 阿里、百度:Redis + Memcache
文档型数据库(bson数据格式):
MongoDB(掌握)
- 基于分布式文件存储的数据库。C++编写,用于处理大量文档。
- MongoDB是RDBMS和NoSQL的中间产品。MongoDB是非关系型数据库中功能最丰富的,NoSQL中最像关系型数据库的数据库。
ConthDB
列存储数据库
- HBase(大数据必学)
- 分布式文件系统
图关系数据库
用于广告推荐,社交网络
- Neo4j、InfoGrid
1.3发展历史
为什么使用Nosql
1、单机Mysql时代

90年代,一个网站的访问量一般不会太大,单个数据库完全够用。随着用户增多,网站出现以下问题
- 数据量增加到一定程度,单机数据库就放不下了
- 数据的索引(B+ Tree),一个机器内存也存放不下
- 访问量变大后(读写混合),一台服务器承受不住。
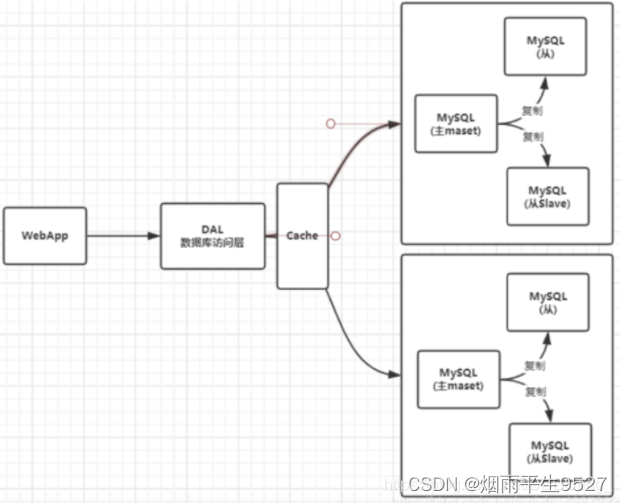
2、Memcached(缓存) + Mysql + 垂直拆分(读写分离)
网站80%的情况都是在读,每次都要去查询数据库的话就十分的麻烦!所以说我们希望减轻数据库的压力,我们可以使用缓存来保证效率!

优化过程经历了以下几个过程:
优化数据库的数据结构和索引(难度大)
文件缓存,通过IO流获取比每次都访问数据库效率略高,但是流量爆炸式增长时候,IO流也承受不了
MemCache,当时最热门的技术,通过在数据库和数据库访问层之间加上一层缓存,第一次访问时查询数据库,将结果保存到缓存,后续的查询先检查缓存,若有直接拿去使用,效率显著提升。
3、分库分表 + 水平拆分 + Mysql集群
4、如今最近的年代
如今信息量井喷式增长,各种各样的数据出现(用户定位数据,图片数据等),大数据的背景下关系型数据库(RDBMS)无法满足大量数据要求。Nosql数据库就能轻松解决这些问题。
目前一个基本的互联网项目

用户的个人信息,社交网络,地理位置。用户自己产生的数据,用户日志等等爆发式增长!
这时候我们就需要使用NoSQL数据库的,Nosql可以很好的处理以上的情况!

目前主流关系型数据库(MySQL/PostgreSQL/Oracle)均已支持JSON数据类型字段。因此,SQL/NoSQL混合设计开发模式可极大突出/强化各自优点
- 通过冗余数据换取查询效率
- 灵活可扩展的数据结构
- 事务的最终一致性
1.4相关概念与区别
结构化与非结构化

传统关系型数据库是结构化数据,每张表在创建的时候都有严格的约束信息,如字段名、字段数据类型、字段约束等,插入的数据必须遵循这些约束
而NoSQL则对数据库格式没有约束,可以是键值型,也可以是文档型,甚至是图格式
关联与非关联
传统数据库的表与表之间往往存在关联,例如外键约束
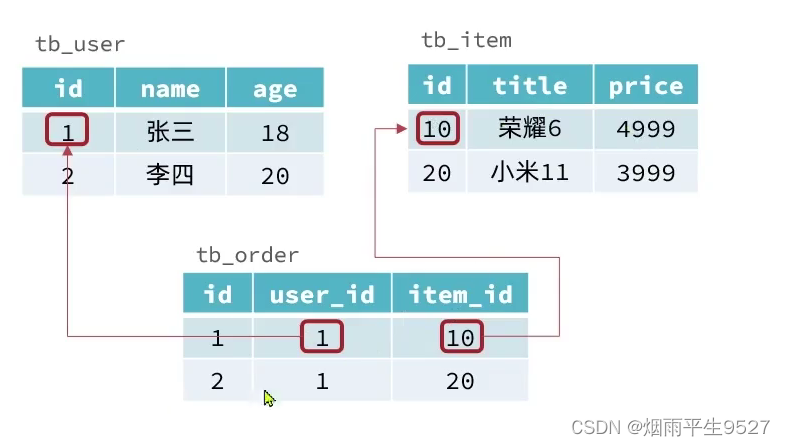
而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合
{
id: 1,
name: "张三",
orders: [
{
id: 1,
item: {
id: 10, title: "荣耀6", price: 4999
}
},
{
id: 2,
item: {
id: 20, title: "小米11", price: 3999
}
}
]
}SQL查询
传统关系型数据库会基于Sql语句做查询,语法有统一的标准
SELECT id, age FROM tb_user WHERE id = 1而不同的非关系型数据库查询语法差异极大
Redis: get user:1
MongoDB: db.user.find({_id: 1})
elasticsearch: GET http://localhost:9200/users/1事务
传统关系型数据库能满足事务的ACID原则(原子性、一致性、独立性及持久性)
而非关系型数据库汪汪不支持事务,或者不能要个保证ACID的特性,只能实现计本的一致性
总结

- 存储方式
- 关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
- 非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
- 扩展性
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
二、redis概述
2.1redis介绍
Redis诞生于2009年,全称是Remote Dictionary Server远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特征:
- 键值(Key-Value)型,Value支持多种不同的数据结构,功能丰富
- 单线程,每个命令具有原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
安装Redis
关于Redis的安装,请参考
常见启动命令
docker exec -it redis bash
redis-cli -h 118.89.20.46 -p 6379 -a 2046
Redis命令行客户端
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下:
其中常见的options有:
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1-p 6379:指定要连接的redis节点的端口,默认是6379-a 123321:指定redis的访问密码
图形化桌面客户端
安装包:Releases · lework/RedisDesktopManager-Windows · GitHub
Redis默认有16个仓库,编号从0至15. 通过配置文件可以设置仓库数量,但是不超过16,并且不能自定义仓库名称。
如果是基于redis-cli连接Redis服务,可以通过select命令来选择数据库:
## 选择0号数据库
select 0Redis应用
- 内存存储、持久化,内存是断电即失的,所以需要持久化(RDB、AOF)
- 高效率、用于高速缓冲
- 发布订阅系统
- 地图信息分析
- 计时器、计数器(eg:浏览量)
- 。。。
基础知识
数据库
redis默认有16个数据库
默认使用的第0个;
16个数据库为:DB 0~DB 15
默认使用DB 0 ,可以使用select n切换到DB n,dbsize可以查看当前数据库的大小,与key数量相关。
127.0.0.1:6379> config get databases # 命令行查看数据库数量databases
1) "databases"
2) "16"
127.0.0.1:6379> select 8 # 切换数据库 DB 8
OK
127.0.0.1:6379[8]> dbsize # 查看数据库大小
(integer) 0
# 不同数据库之间 数据是不能互通的,并且dbsize 是根据库中key的个数。
127.0.0.1:6379> set name sakura
OK
127.0.0.1:6379> SELECT 8
OK
127.0.0.1:6379[8]> get name # db8中并不能获取db0中的键值对。
(nil)
127.0.0.1:6379[8]> DBSIZE
(integer) 0
127.0.0.1:6379[8]> SELECT 0
OK
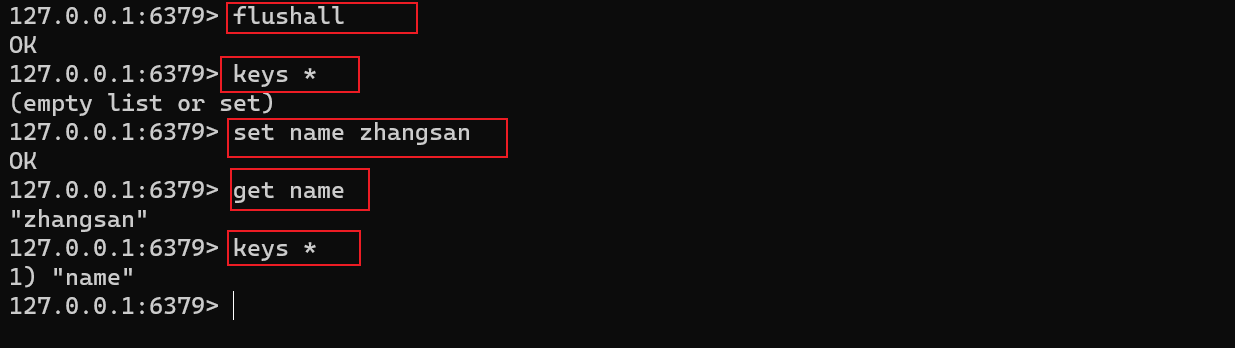
127.0.0.1:6379> keys *
1) "counter:__rand_int__"
2) "mylist"
3) "name"
4) "key:__rand_int__"
5) "myset:__rand_int__"
127.0.0.1:6379> DBSIZE # size和key个数相关
(integer) 5
keys *:查看当前数据库中所有的key。flushdb:清空当前数据库中的键值对。flushall:清空所有数据库的键值对。
单线程
Redis是单线程的,Redis是基于内存操作的。
所以Redis的性能瓶颈不是CPU,而是机器内存和网络带宽。
那么为什么Redis的速度如此快呢,性能这么高呢?QPS达到10W+
Redis为什么单线程还这么快?
- 误区1:高性能的服务器一定是多线程的?
- 误区2:多线程(CPU上下文会切换!)一定比单线程效率高!
核心:Redis是将所有的数据放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文会切换:耗时的操作!),对于内存系统来说,如果没有上下文切换效率就是最高的,多次读写都是在一个CPU上的,在内存存储数据情况下,单线程就是最佳的方案。
2.2Redis数据类型
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5中常用的数据类型
- 字符串:String
- 哈希:Hash
- 列表:List
- 集合:Set
- 有序集合:Sorted Set

Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
例如,需要存储用户、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1

2.3常用命令
help
在Redis的客户端中,你可以通过输入
help命令来获取帮助信息。这个命令会列出所有可用的Redis命令以及简短的描述。具体来说,当你在Redis客户端中输入help后,它会显示一个命令列表,你可以进一步输入特定命令的名称加上help来获取关于那个命令的详细信息。例如,如果你想要了解SET命令的用法,你可以输入help SET。
Redis-key
在redis中无论什么数据类型,在数据库中都是以key-value形式保存,通过进行对Redis-key的操作,来完成对数据库中数据的操作。
| 命令 | 描述 |
|---|---|
| KEYs pattern | 查找所有符合给定模式(pattern)的key |
| EXISTs key | 检查给定key是否存在 |
| TYPE key | 返回key所储存的值的类型 |
| TTL key | 返回给定key的剩余生存时间(TTL, time to live),以秒为单位 |
| DEL key | 该命令用于在key存在是删除key |
更多详细的命令可以查看官方文档:redis命令手册
127.0.0.1:6379> keys * # 查看当前数据库所有key
(empty list or set)
127.0.0.1:6379> set name qinjiang # set key
OK
127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> move age 1 # 将键值对移动到指定数据库
(integer) 1
127.0.0.1:6379> EXISTS age # 判断键是否存在
(integer) 0 # 不存在
127.0.0.1:6379> EXISTS name
(integer) 1 # 存在
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> keys *
1) "age"
127.0.0.1:6379[1]> del age # 删除键值对
(integer) 1 # 删除个数
127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> EXPIRE age 15 # 设置键值对的过期时间
(integer) 1 # 设置成功 开始计数
127.0.0.1:6379> ttl age # 查看key的过期剩余时间
(integer) 13
127.0.0.1:6379> ttl age
(integer) 11
127.0.0.1:6379> ttl age
(integer) 9
127.0.0.1:6379> ttl age
(integer) -2 # -2 表示key过期,-1表示key未设置过期时间
127.0.0.1:6379> get age # 过期的key 会被自动delete
(nil)
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> type name # 查看value的数据类型
string
字符串(String)常用命令
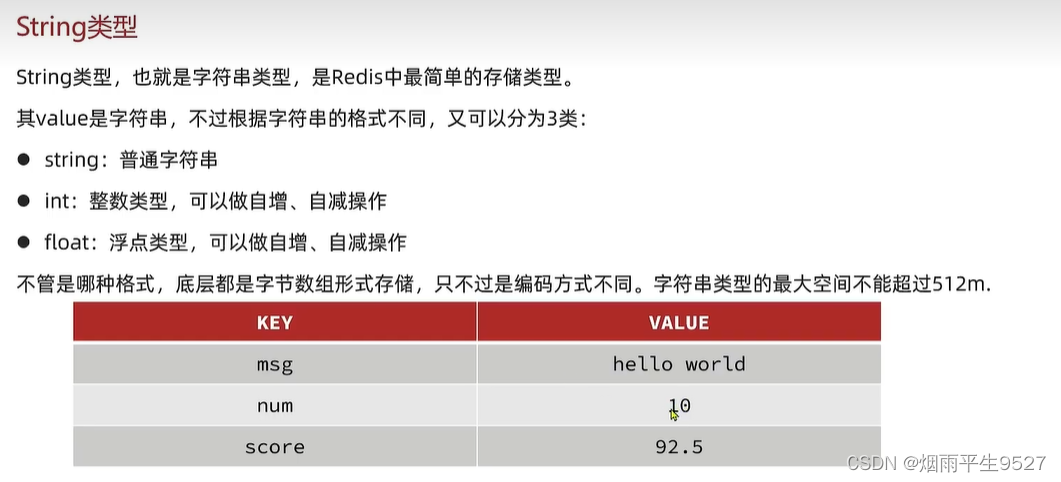
| 命令 | 描述 |
|---|---|
| SET key value | 设置指定key的值 |
| GET key | 获取指定key的值 |
| SETEX key seconds value | 设置指定key的值,并将key的过期时间设为seconds秒 |
| SETNX key value | 只有在key不存在时设置key的值 |

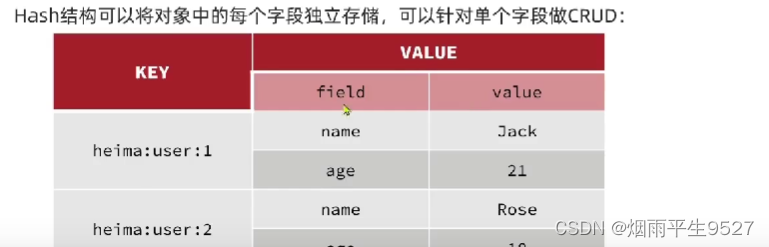
哈希(Hash)常用命令
Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象。
Set就是一种简化的Hash,只变动key,而value使用默认值填充。可以将一个Hash表作为一个对象进行存储,表中存放对象的信息。
Hash变更的数据user name age,尤其是用户信息之类的,经常变动的信息!Hash更适合于对象的存储,Sring更加适合字符串存储!
| 命令 | 描述 |
|---|---|
| HSET key field value | 将哈希表key 中的字段field的值设为value |
| HGET key field | 获取存储在哈希表中指定字段的值 |
| HDEL key field | 删除存储在哈希表中的指定字段 |
| HKEYS key | 获取哈希表中所有字段 |
| HVALS key | 获取哈希表中所有值 |
| HGETALL key | 获取在哈希表中指定key的所有字段和值 |

------------------------HSET--HMSET--HSETNX----------------
127.0.0.1:6379> HSET studentx name sakura # 将studentx哈希表作为一个对象,设置name为sakura
(integer) 1
127.0.0.1:6379> HSET studentx name gyc # 重复设置field进行覆盖,并返回0
(integer) 0
127.0.0.1:6379> HSET studentx age 20 # 设置studentx的age为20
(integer) 1
127.0.0.1:6379> HMSET studentx sex 1 tel 15623667886 # 设置sex为1,tel为15623667886
OK
127.0.0.1:6379> HSETNX studentx name gyc # HSETNX 设置已存在的field
(integer) 0 # 失败
127.0.0.1:6379> HSETNX studentx email 12345@qq.com
(integer) 1 # 成功
----------------------HEXISTS--------------------------------
127.0.0.1:6379> HEXISTS studentx name # name字段在studentx中是否存在
(integer) 1 # 存在
127.0.0.1:6379> HEXISTS studentx addr
(integer) 0 # 不存在
-------------------HGET--HMGET--HGETALL-----------
127.0.0.1:6379> HGET studentx name # 获取studentx中name字段的value
"gyc"
127.0.0.1:6379> HMGET studentx name age tel # 获取studentx中name、age、tel字段的value
1) "gyc"
2) "20"
3) "15623667886"
127.0.0.1:6379> HGETALL studentx # 获取studentx中所有的field及其value
1) "name"
2) "gyc"
3) "age"
4) "20"
5) "sex"
6) "1"
7) "tel"
8) "15623667886"
9) "email"
10) "12345@qq.com"
--------------------HKEYS--HLEN--HVALS--------------
127.0.0.1:6379> HKEYS studentx # 查看studentx中所有的field
1) "name"
2) "age"
3) "sex"
4) "tel"
5) "email"
127.0.0.1:6379> HLEN studentx # 查看studentx中的字段数量
(integer) 5
127.0.0.1:6379> HVALS studentx # 查看studentx中所有的value
1) "gyc"
2) "20"
3) "1"
4) "15623667886"
5) "12345@qq.com"
-------------------------HDEL--------------------------
127.0.0.1:6379> HDEL studentx sex tel # 删除studentx 中的sex、tel字段
(integer) 2
127.0.0.1:6379> HKEYS studentx
1) "name"
2) "age"
3) "email"
-------------HINCRBY--HINCRBYFLOAT------------------------
127.0.0.1:6379> HINCRBY studentx age 1 # studentx的age字段数值+1
(integer) 21
127.0.0.1:6379> HINCRBY studentx name 1 # 非整数字型字段不可用
(error) ERR hash value is not an integer
127.0.0.1:6379> HINCRBYFLOAT studentx weight 0.6 # weight字段增加0.6
"90.8"
列表(List)常用命令
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
首先我们列表,可以经过规则定义将其变为队列、栈、双端队列等
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VPvbIltc-1597890996518)(狂神说 Redis.assets/image-20200813114255459.png)]](https://img-blog.csdnimg.cn/20200820104440398.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0RERERlbmdf,size_16,color_FFFFFF,t_70#pic_center)
正如图Redis中List是可以进行双端操作的,所以命令也就分为了LXXX和RLLL两类,有时候L也表示List例如LLEN
Redis List是简单的字符串列表,按照插入顺序排序
| 命令 | 描述 |
|---|---|
LPUSH key value1 [value2] |
将一个或多个值插入到列表头部 |
LRANGE key start stop |
获取列表指定范围内的元素 |
RPOP key |
移除并获取列表最后一个元素 |
LLEN key |
获取列表长度 |
BRPOP key1 [key2] timeout |
移出并获取列表的最后一个元素 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
127.0.0.1:6379> LRANGE mylist 0 4 # LRANGE 获取起止位置范围内的元素
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> LRANGE mylist 0 -1 # 获取全部元素
1) "k2"
2) "k1"
3) "k3"
127.0.0.1:6379> LPUSHX list v1 # list不存在 LPUSHX失败
(integer) 0
127.0.0.1:6379> LPUSHX list v1 v2
(integer) 0
127.0.0.1:6379> LPUSHX mylist k4 k5 # 向mylist中 左边 PUSH k4 k5
(integer) 5
---------------------------LINSERT--LLEN--LINDEX--LSET----------------------------
127.0.0.1:6379> LINSERT mylist after k2 ins_key1 # 在k2元素后 插入ins_key1
(integer) 6
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k5"
2) "k4"
3) "k2"
4) "ins_key1"
5) "k1"
6) "k3"
127.0.0.1:6379> LLEN mylist # 查看mylist的长度
(integer) 6
127.0.0.1:6379> LINDEX mylist 3 # 获取下标为3的元素
"ins_key1"
127.0.0.1:6379> LINDEX mylist 0
"k5"
127.0.0.1:6379> LSET mylist 3 k6 # 将下标3的元素 set值为k6
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "k5"
2) "k4"
3) "k2"
4) "k6"
5) "k1"
6) "k3"
LPUSHX/RPUSHX key value |
向已存在的列名中push值(一个或者多个) |
LLEN key |
查看列表长度 |
LINDEX key index |
通过索引获取列表元素 |
LSET key index value |
通过索引为元素设值 |
集合(Set)常用命令
Redis的Set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。

| 命令 | 描述 |
|---|---|
| SADD key member1 [member2] | 向集合添加一个或多个成员 |
| SMEMBERS key | 返回集合中的所有成员 |
| SCARD key | 获取集合的成员数 |
| SINTER key1 [key2] | 返回给定所有集合的交集 |
| SUNION key1 [key2] | 返回所有给定集合的并集 |
| SDIFF key1 [key2] | 返回给定所有集合的差集 |
| SREM key member1 [member2] | 移除集合中一个或多个成 |
127.0.0.1:6379> smembers myset # 获取集合中所有成员
1) "m4"
2) "m3"
3) "m2"
4) "m1"
127.0.0.1:6379> SISMEMBER myset m5 # 查询m5是否是myset的成员
(integer) 0 # 不是,返回0
---------------------SRANDMEMBER--SPOP----------------------------------
127.0.0.1:6379> SRANDMEMBER myset 3 # 随机返回3个成员
1) "m2"
2) "m3"
3) "m4"
127.0.0.1:6379> SRANDMEMBER myset # 随机返回1个成员
"m3"
127.0.0.1:6379> SPOP myset 2 # 随机移除并返回2个成员
1) "m1"
2) "m4"
# 将set还原到{m1,m2,m3,m4}
---------------------SMOVE--SREM----------------------------------------
127.0.0.1:6379> SMOVE myset newset m3 # 将myset中m3成员移动到newset集合
(integer) 1
SMEMBERS key |
返回集合中所有的成员 |
SISMEMBER key member |
查询member元素是否是集合的成员,结果是无序的 |
SRANDMEMBER key [count] |
随机返回集合中count个成员,count缺省值为1 |
SPOP key [count] |
随机移除并返回集合中count个成员,count缺省值为1 |
SMOVE source destination member |
将source集合的成员member移动到destination集合 |
有序集合(Sorted Set)常用命令
Redis Sorted Set有序集合是String类型元素的集合,且不允许重复的成员。每个元素都会关联一个double类型的分数(score) 。Redis正是通过分数来为集合中的成员进行从小到大排序。有序集合的成员是唯一的,但分数却可以重复。

| 命令 | 描述 |
|---|---|
| ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合中指定区间内的成员 |
| ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量increment |
| ZREM key member [member …] | 移除有序集合中的一个或多个成员 |
-------------------ZADD--ZCARD--ZCOUNT--------------
127.0.0.1:6379> ZADD myzset 1 m1 2 m2 3 m3 # 向有序集合myzset中添加成员m1 score=1 以及成员m2 score=2..
(integer) 2
127.0.0.1:6379> ZCARD myzset # 获取有序集合的成员数
(integer) 2
127.0.0.1:6379> ZCOUNT myzset 0 1 # 获取score在 [0,1]区间的成员数量
(integer) 1
127.0.0.1:6379> ZCOUNT myzset 0 2
(integer) 2
----------------ZINCRBY--ZSCORE--------------------------
127.0.0.1:6379> ZINCRBY myzset 5 m2 # 将成员m2的score +5
"7"
127.0.0.1:6379> ZSCORE myzset m1 # 获取成员m1的score
"1"
127.0.0.1:6379> ZSCORE myzset m2
"7"
--------------ZRANK--ZRANGE-----------------------------------
127.0.0.1:6379> ZRANK myzset m1 # 获取成员m1的索引,索引按照score排序,score相同索引值按字典顺序顺序增加
(integer) 0
127.0.0.1:6379> ZRANK myzset m2
(integer) 2
127.0.0.1:6379> ZRANGE myzset 0 1 # 获取索引在 0~1的成员
1) "m1"
2) "m3"
127.0.0.1:6379> ZRANGE myzset 0 -1 # 获取全部成员
1) "m1"
2) "m3"
3) "m2"
ZCARD key |
获取有序集合的成员数 |
ZCOUNT key min max |
计算在有序集合中指定区间score的成员数 |
ZSCORE key member |
返回有序集中,成员的分数值 |
ZRANK key member |
返回有序集合中指定成员的索引 |
ZRANGE key start end |
通过索引区间返回有序集合成指定区间内的成员 |
ZRANGEBYSCORE key min max |
通过分数返回有序集合指定区间内的成员==-inf 和 +inf分别表示最小最大值,只支持开区间()== |

注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可
应用案例:
- set排序 存储班级成绩表 工资表排序!
- 普通消息,1.重要消息 2.带权重进行判断
- 排行榜应用实现,取Top N测试
2.4三种特殊数据类型
Geospatial(地理位置)
使用经纬度定位地理坐标并用一个有序集合zset保存,所以zset命令也可以使用
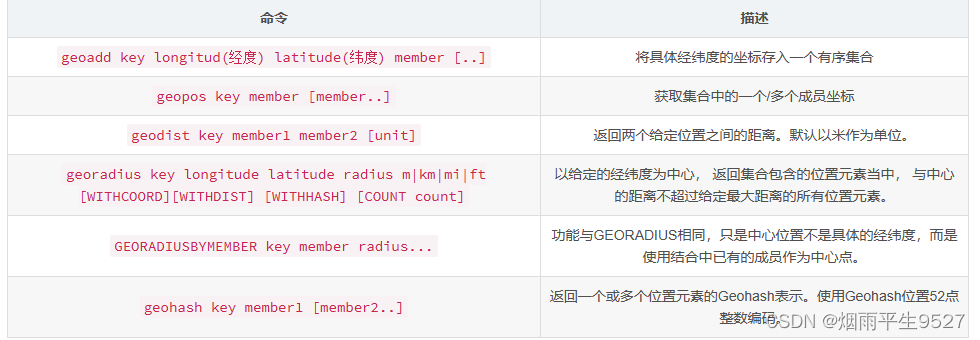
geoadd
# getadd 添加地理位置
# 规则:两级无法直接添加,我们一般会下载城市数据,直接通过java程序一次性导入!
# 有效经度为 -180 到 180 度。
# 有效纬度为 -85.05112878 到 85.05112878 度。
# 当用户尝试索引指定范围之外的坐标时,该命令将报告错误。
127.0.0.1:6379> geoadd china:city 39.90 116.40 beijing
(error) ERR invalid longitude,latitude pair 39.900000,116.400000
# 参数 key 值()
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai
(integer) 1
127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqin 114.05 22.52 shenzhen
(integer) 2
127.0.0.1:6379> geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian
(integer) 2
geopos
获得当前定位:一定是一个坐标值!
127.0.0.1:6379> geopos china:city beijing # 获取指定的城市的经度和纬度!
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
127.0.0.1:6379> geopos china:city beijing chongqin
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
geodist
两人之间的距离!
单位必须是以下之一,默认为米:
- m为米。
- 公里换公里。
- 英里数英里。
- 英尺换英尺。
127.0.0.1:6379> geodist china:city beijing shanghai km # 查看北京到上海的直线距离
"1067.3788"
127.0.0.1:6379> geodist china:city beijing chongqin km # 查看北京到重庆的直线距离
"1464.0708"
georadius 以给定的经纬度为中心,找出某一半径内的元素
我附近的人?(获得所有附近的人的地址,定位!)通过半径来查询!
获得指定数量的人,200
所有数据应该都录入:china:city,才会让结果更加准确!
127.0.0.1:6379> georadius china:city 110 30 1000 km # 以100,30 这个经纬度为中心,寻找方圆为1000km内的城市
1) "chongqin"
2) "xian"
3) "shenzhen"
4) "hangzhou"
127.0.0.1:6379> georadius china:city 110 30 500 km
1) "chongqin"
2) "xian"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist # 显示到中心距离的位置
1) 1) "chongqin"
2) "341.9374"
2) 1) "xian"
2) "483.8340"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord # 显示他人的定位信息
1) 1) "chongqin"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) 1) "108.96000176668167114"
2) "34.25999964418929977"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist withcoord count 1 #筛选出指定的结果!
1) 1) "chongqin"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist withcoord count 2
1) 1) "chongqin"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
2) 1) "xian"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
关于GEORADIUS的参数
通过
georadius就可以完成 附近的人功能withcoord:带上坐标
withdist:带上距离,单位与半径单位相同
COUNT n : 只显示前n个(按距离递增排序)
georadiusbymember
# 找出位于指定元素周围的其他元素!
127.0.0.1:6379> georadiusbymember china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> georadiusbymember china:city shanghai 400 km
1) "hangzhou"
2) "shanghai"
#GEOHASH 命令-返回一个或多个位置元素的Geohash表示GEOHASH 命令-返回一个或多个位置元素的Geohash表示
该命令返回11个字符Geohash字符串!
# 将二维的经纬度转换成一维的字符串,如果两个字符串越接近,那么距离越近!
127.0.0.1:6379> geohash china:city beijing chongqin
1) "wx4fbxxfke0"
2) "wm5xzrybty0"
GEO 底层的实现原理其实就是 Zset !我们可以使用Zset命令来操作geo!
Hyperloglog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
其底层使用string数据类型
什么是基数?
数据集中不重复的元素的个数。
A {1,3,5,7,8,7}
B {1,3,5,7,8}
基数(不重复的元素) = 5,可以接受误差!
应用场景:
网页的访问量(UV):一个用户多次访问,也只能算作一个人。
传统实现,存储用户的id,然后每次进行比较。当用户变多之后这种方式及其浪费空间,而我们的目的只是计数,Hyperloglog就能帮助我们利用最小的空间完成。

127.0.0.1:6379> pfadd mykey a b c d e f g h i j # 创建第一组元素 mykey
(integer) 1
127.0.0.1:6379> pfcount mykey # 统计 key 元素的基数数量
(integer) 10
127.0.0.1:6379> pfadd mykey2 i j z x c v b n m # 创建第二组元素 mykey2
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 9
127.0.0.1:6379> pfmerge mykey3 mykey mykey2 # 合并两组mykey + mykey2 => mykey3 (并集)
OK
127.0.0.1:6379> pfcount mykey3 # 看并集的数量!
(integer) 15
如果允许容错,那么一定可以使用Hyperloglog !
如果不允许容错,就使用set或者自己的数据类型即可 !
BitMaps(位图)
使用位存储,信息状态只有 0 和 1
Bitmap是一串连续的2进制数字(0或1),每一位所在的位置为偏移(offset),在bitmap上可执行AND,OR,XOR,NOT以及其它位操作。
应用场景
统计用户信息,活跃,不活跃!登录,未登录!打卡,365打卡!两个状态的,都可以使用Bitmaps!
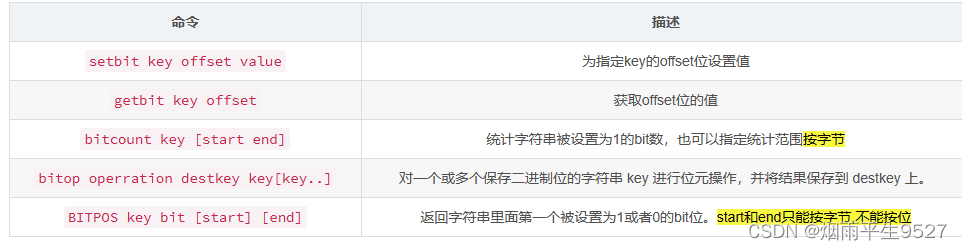
------------setbit--getbit--------------
127.0.0.1:6379> setbit sign 0 1 # 设置sign的第0位为 1
(integer) 0
127.0.0.1:6379> setbit sign 2 1 # 设置sign的第2位为 1 不设置默认 是0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> type sign
string
127.0.0.1:6379> getbit sign 2 # 获取第2位的数值
(integer) 1
127.0.0.1:6379> getbit sign 3
(integer) 1
127.0.0.1:6379> getbit sign 4 # 未设置默认是0
(integer) 0
-----------bitcount----------------------------
127.0.0.1:6379> BITCOUNT sign # 统计sign中为1的位数
(integer) 4
三、redis事务
3.1概述
Redis的单条命令是保证原子性的,但是redis事务不能保证原子性
Redis 事务本质:一组命令的集合!一个事务中的所有命令都会被序列化,在事务执行的过程中,会按照顺序执行!一次性、顺序新、排他性!执行一些列的命令!
Redis事务没有隔离级别的概念!
所有的命令在事务中,并没有直接被执行!只有发起执行命令的时候才会执行!exec
----------------- 队列 set set set 执行 -------------------
事务中每条命令都会被序列化,执行过程中按顺序执行,不允许其他命令进行干扰。
- 一次性
- 顺序性
- 排他性
3.2Redis事务操作过程
- 开启事务(
multi) - 命令入队
- 执行事务(
exec)
所以事务中的命令在加入时都没有被执行,直到提交时才会开始执行(Exec)一次性完成。
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> set k1 v1 # 命令入队
QUEUED
127.0.0.1:6379> set k2 v2 # ..
QUEUED
127.0.0.1:6379> get k1
QUEUED
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> exec # 事务执行
1) OK
2) OK
3) "v1"
4) OK
5) 1) "k3"
2) "k2"
3) "k1"
取消事务(discurd)
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> DISCARD # 放弃事务
OK
127.0.0.1:6379> EXEC
(error) ERR EXEC without MULTI # 当前未开启事务
127.0.0.1:6379> get k1 # 被放弃事务中命令并未执行
(nil)
事务错误
代码语法错误(编译时异常)所有的命令都不执行
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> error k1 # 这是一条语法错误命令
(error) ERR unknown command `error`, with args beginning with: `k1`, # 会报错但是不影响后续命令入队
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> EXEC
(error) EXECABORT Transaction discarded because of previous errors. # 执行报错
127.0.0.1:6379> get k1
(nil) # 其他命令并没有被执行
代码逻辑错误 (运行时异常) **其他命令可以正常执行 ** >>> 所以不保证事务原子性
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> INCR k1 # 这条命令逻辑错误(对字符串进行增量)
QUEUED
127.0.0.1:6379> get k2
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) (error) ERR value is not an integer or out of range # 运行时报错
4) "v2" # 其他命令正常执行
# 虽然中间有一条命令报错了,但是后面的指令依旧正常执行成功了。
# 所以说Redis单条指令保证原子性,但是Redis事务不能保证原子性。
监控
悲观锁:
- 很悲观,认为什么时候都会出现问题,无论做什么都会加锁
乐观锁:
- 很乐观,认为什么时候都不会出现问题,所以不会上锁!更新数据的时候去判断一下,在此期间是否有人修改过这个数据
- 获取version
- 更新的时候比较version
使用watch key监控指定数据,相当于乐观锁加锁。
正常执行
127.0.0.1:6379> set money 100 # 设置余额:100
OK
127.0.0.1:6379> set use 0 # 支出使用:0
OK
127.0.0.1:6379> watch money # 监视money (上锁)
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY use 20
QUEUED
127.0.0.1:6379> exec # 监视值没有被中途修改,事务正常执行
1) (integer) 80
2) (integer) 20
测试多线程修改值,使用watch可以当做redis的乐观锁操作(相当于getversion)
我们启动另外一个客户端模拟插队线程。
线程1:
127.0.0.1:6379> watch money # money上锁
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY use 20
QUEUED
127.0.0.1:6379> # 此时事务并没有执行
模拟线程插队,线程2:
127.0.0.1:6379> INCRBY money 500 # 修改了线程一中监视的money
(integer) 600
回到线程1,执行事务:
127.0.0.1:6379> EXEC # 执行之前,另一个线程修改了我们的值,这个时候就会导致事务执行失败
(nil) # 没有结果,说明事务执行失败
127.0.0.1:6379> get money # 线程2 修改生效
"600"
127.0.0.1:6379> get use # 线程1事务执行失败,数值没有被修改
"0"
解锁获取最新值,然后再加锁进行事务。
unwatch进行解锁