前言:
继续上一篇爬虫工作量由小到大的思维转变---<第四十四章 Scrapyd 用gerapy管理多台机器爬虫>-CSDN博客
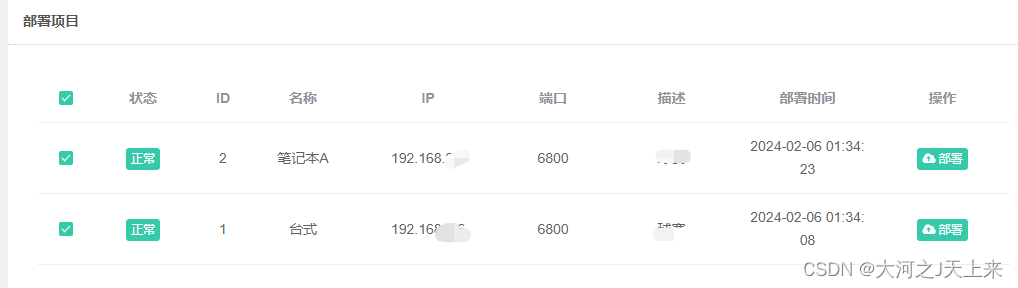
要想在电脑B上,部署爬虫应该做哪些?
正文:
前期准备:
1.已经成功在电脑A上启动了gerapy.并能够成功连接电脑A的ip;
原理:
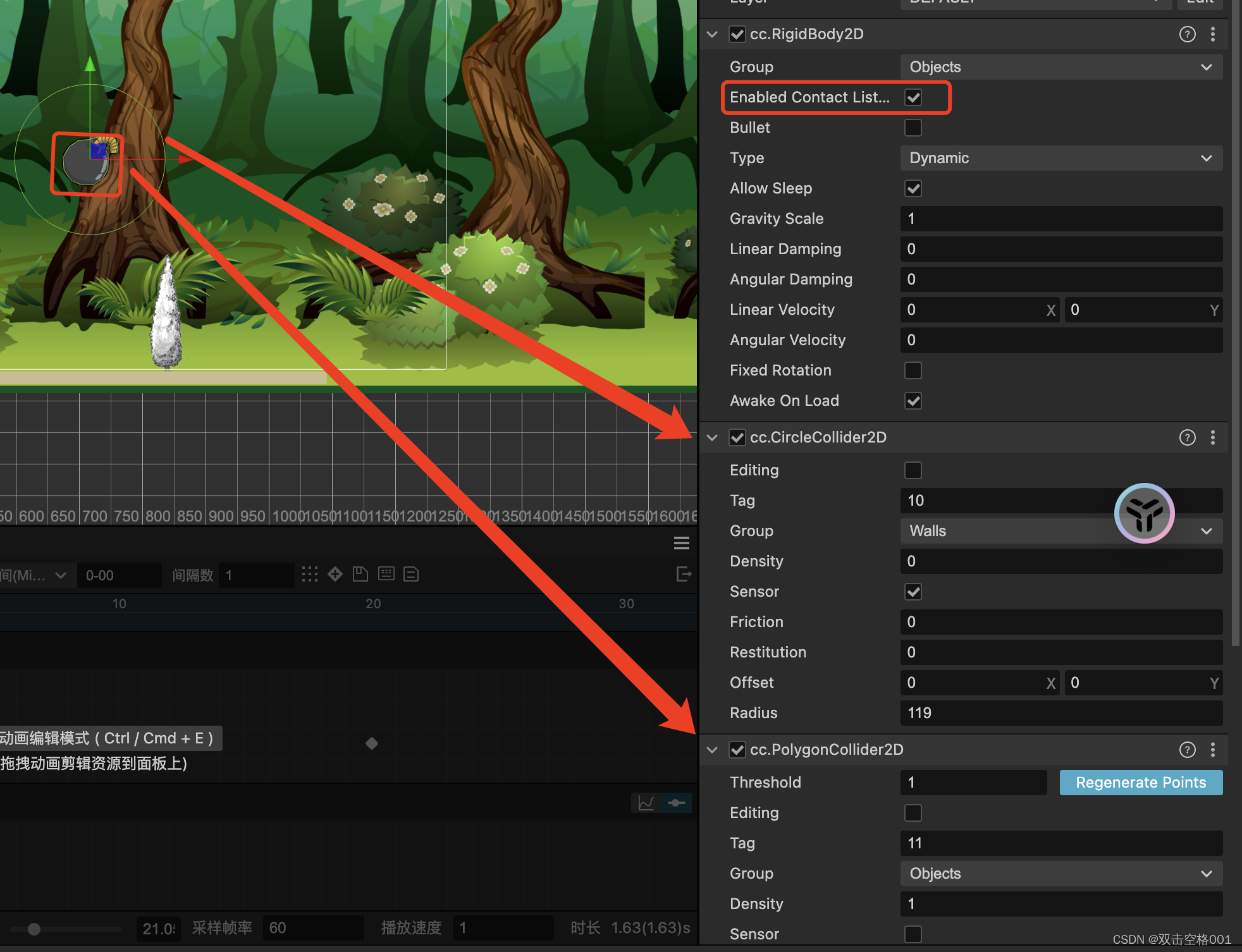
首先,我需要理解,电脑B上理论是不需要再放爬虫代码了,因为已经在gerapy的服务上部署了爬虫项目;而爬虫项目也已经被打包好成了egg!
因此,我们只需要做的就是,让电脑B,启动scrapyd,然后再用电脑A上的gerapy启动电脑B的scrapyd!
电脑B的工作:
1.安装scrapyd:
是安装全局scrapyd还是虚拟环境下的scrapyd,都随你!
在电脑B上安装Scrapyd通常是指全局安装Scrapyd,这样Scrapyd服务就可以在系统级别运行,无论使用哪个用户账户登录。全局安装确保了Scrapyd作为一个独立的服务运行,可以更方便地进行管理和配置。
使用pip全局安装Scrapyd
打开命令行界面(在Windows上,您可以搜索
cmd或命令提示符;在macOS或Linux上,您可以使用Terminal)。使用以下命令安装Scrapyd:
pip install scrapyd
如果没有将Python添加到环境变量,或者上面的命令没有作用,可能需要使用完整路径,例如:
c:\python39\python.exe -m pip install scrapyd
(根据Python安装路径和版本调整命令)
使用虚拟环境安装Scrapyd
虽然推荐全局安装Scrapyd以方便服务运行,但也可以在虚拟环境中安装Scrapyd。这通常用于开发环境,或当需要在同一台计算机上管理不同项目的依赖时。如果选择在虚拟环境中安装:
首先,创建一个新的虚拟环境:
python -m venv scrapyd-venv激活虚拟环境:
在Windows上:
scrapyd-venv\Scripts\activate.bat在macOS或Linux上:
source scrapyd-venv/bin/activate
在虚拟环境中安装Scrapyd:
pip install scrapyd
使用虚拟环境安装Scrapyd时,需要确保在运行Scrapyd服务之前总是先激活对应的虚拟环境。
配置Scrapyd
无论是全局安装还是在虚拟环境中安装Scrapyd,都可通过修改Scrapyd的配置文件(默认为scrapyd.conf)来配置Scrapyd服务。这包括设置监听端口、日志文件位置等。具体配置项取决于您的实际需求。
小总结
通常推荐在电脑B上全局安装Scrapyd,使其作为系统服务运行。这样可以更便捷地管理Scrapyd服务,特别是在生产环境中。如果出于特定原因需要在虚拟环境中安装Scrapyd,也是可行的,只是在使用时需要注意激活相应的虚拟环境。
2.修改scrapyd的配置(scrapyd.conf)
现在的scrapyd(我当是已经是全局进行安装了),安装完的scrapyd是没有配置文件的,需要自己手动配置!
scrapyd.conf配置文档(翻译版):
# Scrapyd 配置文件
[scrapyd]
# 用于存放 egg 包的目录路径
eggs_dir = eggs
# 日志文件的目录路径
logs_dir = logs
# Item 导出文件存放的目录路径
items_dir = items
# 在日志目录中保存的最大任务(Job)数量
jobs_to_keep = 5
# 数据库文件存放目录,用于保存爬虫状态等信息
dbs_dir = dbs
# 同时运行的最大进程数,0 表示不限制
max_proc = 0
# 每个 CPU 核心允许的最大进程数
max_proc_per_cpu = 10
# 完成的作业(Job)保留的最大数量
finished_to_keep = 100
# 调度器轮询间隔时间(秒)
poll_interval = 5.0
# Scrapyd 服务绑定的地址
bind_address = 0.0.0.0
# 监听的 HTTP 端口号
http_port = 6800
# 是否开启调试模式,开启为 on,关闭为 off
debug = off
# 任务运行器,用于执行爬虫任务
runner = scrapyd.runner
# Scrapyd 应用
application = scrapyd.app.application
# 任务启动器,用于管理爬虫进程
launcher = scrapyd.launcher.Launcher
# Web 服务的根目录
webroot = scrapyd.website.Root
[services]
# 计划任务接口,用于提交爬虫运行任务
schedule.json = scrapyd.webservice.Schedule
# 取消任务接口,用于取消正在运行的爬虫任务
cancel.json = scrapyd.webservice.Cancel
# 添加版本接口,用于上传新版本的爬虫项目
addversion.json = scrapyd.webservice.AddVersion
# 列出项目接口,返回当前所有的爬虫项目
listprojects.json = scrapyd.webservice.ListProjects
# 列出版本接口,返回指定项目的所有版本
listversions.json = scrapyd.webservice.ListVersions
# 列出爬虫接口,返回指定项目中的所有爬虫
listspiders.json = scrapyd.webservice.ListSpiders
# 删除项目接口,用于删除整个项目
delproject.json = scrapyd.webservice.DeleteProject
# 删除版本接口,用于删除项目的特定版本
delversion.json = scrapyd.webservice.DeleteVersion
# 列出作业接口,展示作业的运行状态等信息
listjobs.json = scrapyd.webservice.ListJobs
# 守护进程状态接口,返回 Scrapyd 服务的状态信息
daemonstatus.json = scrapyd.webservice.DaemonStatus
3.启动 scrapyd 时指定配置文件
cmd之后,进入到这个scrapyd.conf的文件夹内;然后直接启动这个scrapyd就行(他会默认指认当前的配置文件为启动scrapyd的配置文件)
4.安装爬虫项目所需的依赖包
(如果缺少爬虫所需的依赖包,大概率会部署不上去)
这一步视你的爬虫而定,一般来说,你需要装好你爬虫所需的依赖包! 所以,具体如何把你爬虫的依赖转到另一台电脑上----参考关于python依赖包的问题(番外)-CSDN博客; 或者你用Docker部署
5.完成