1,ollama项目
Ollama 是一个强大的框架,设计用于在 Docker 容器中部署 LLM。Ollama 的主要功能是在 Docker 容器内部署和管理 LLM 的促进者,它使该过程变得非常简单。它帮助用户快速在本地运行大模型,通过简单的安装指令,可以让用户执行一条命令就在本地运行开源大型语言模型,例如 Llama 2。
2 ,在autodl安装软件启动
OLLAMA_HOST The host:port to bind to (default "127.0.0.1:11434")
OLLAMA_ORIGINS A comma separated list of allowed origins.
OLLAMA_MODELS The path to the models directory (default is "~/.ollama/models")
export OLLAMA_HOST="0.0.0.0:6006"
export OLLAMA_MODELS=/root/autodl-tmp/models
curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local/bin...
>>> Creating ollama user...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
WARNING: Unable to detect NVIDIA GPU. Install lspci or lshw to automatically detect and install NVIDIA CUDA drivers.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
3,启动 服务和启动coder大模型
# ollama serve
Couldn't find '/root/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIWgZacFNqeDhs/gSHBfe8QCuerrrMMHxQ4cp0PZVlf4
time=2024-03-12T22:35:53.523+08:00 level=INFO source=images.go:710 msg="total blobs: 0"
time=2024-03-12T22:35:53.523+08:00 level=INFO source=images.go:717 msg="total unused blobs removed: 0"
time=2024-03-12T22:35:53.523+08:00 level=INFO source=routes.go:1021 msg="Listening on [::]:6006 (version 0.1.28)"
time=2024-03-12T22:35:53.524+08:00 level=INFO source=payload_common.go:107 msg="Extracting dynamic libraries..."
time=2024-03-12T22:35:57.030+08:00 level=INFO source=payload_common.go:146 msg="Dynamic LLM libraries [cpu rocm_v6 cuda_v11 cpu_avx cpu_avx2 rocm_v5]"
time=2024-03-12T22:35:57.030+08:00 level=INFO source=gpu.go:94 msg="Detecting GPU type"
time=2024-03-12T22:35:57.030+08:00 level=INFO source=gpu.go:265 msg="Searching for GPU management library libnvidia-ml.so"
time=2024-03-12T22:35:57.033+08:00 level=INFO source=gpu.go:311 msg="Discovered GPU libraries: [/usr/lib/x86_64-linux-gnu/libnvidia-ml.so.535.104.05 /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.535.98]"
time=2024-03-12T22:35:57.068+08:00 level=INFO source=gpu.go:99 msg="Nvidia GPU detected"
time=2024-03-12T22:35:57.068+08:00 level=INFO source=cpu_common.go:11 msg="CPU has AVX2"
time=2024-03-12T22:35:57.074+08:00 level=INFO source=gpu.go:146 msg="CUDA Compute Capability detected: 8.6"
代码生成coder 服务:
export OLLAMA_HOST="0.0.0.0:6006"
root@autodl-container-95a74bb18b-f8b73845:~# ollama run deepseek-coder:6.7b
pulling manifest
pulling 59bb50d8116b... 7% ▕█████ ▏ 256 MB/3.8 GB 25 MB/s 2m20s
速度哦还是挺快的,经过一段时间的等待就可以服务启动成功了。
4 ,测试接口
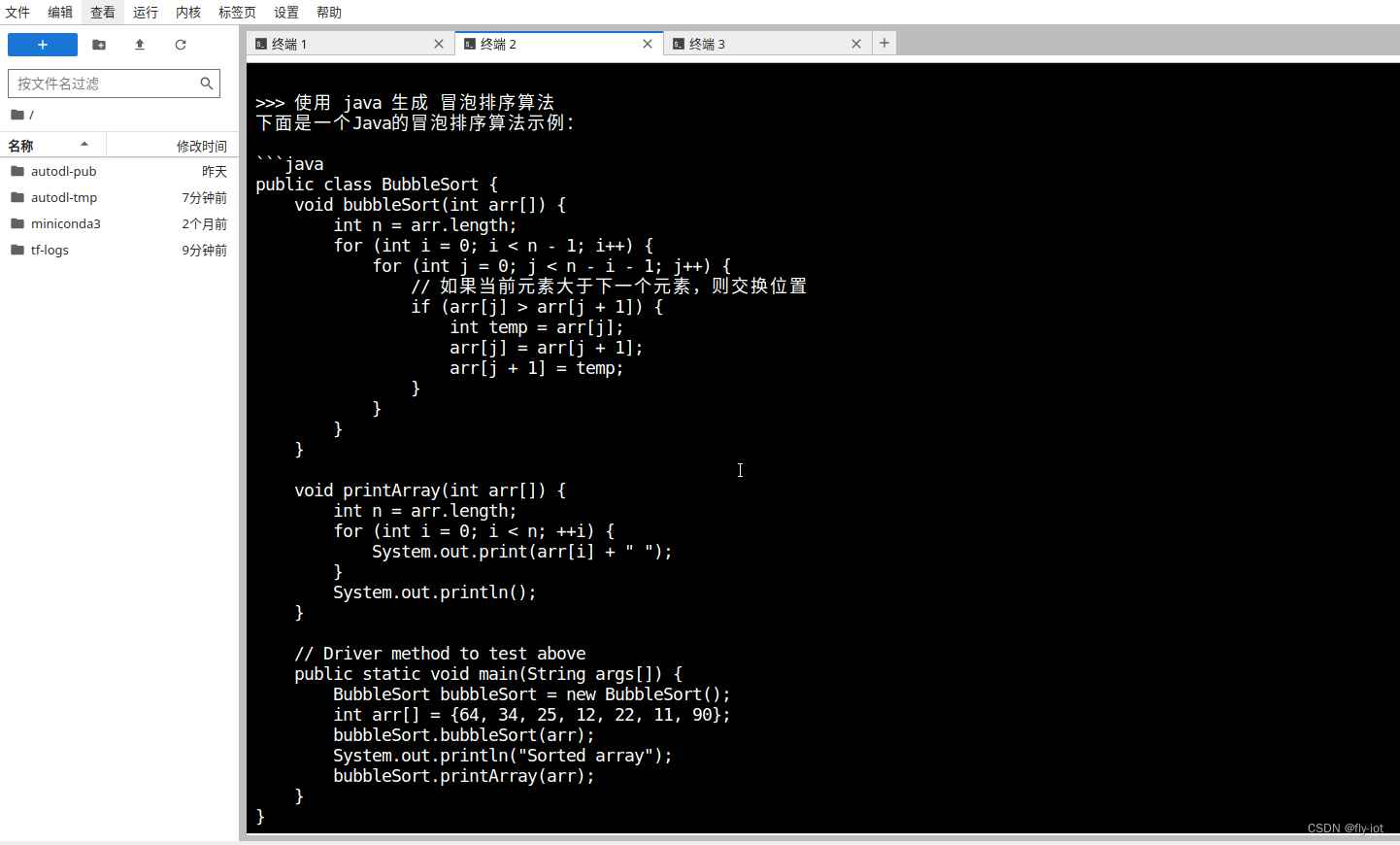
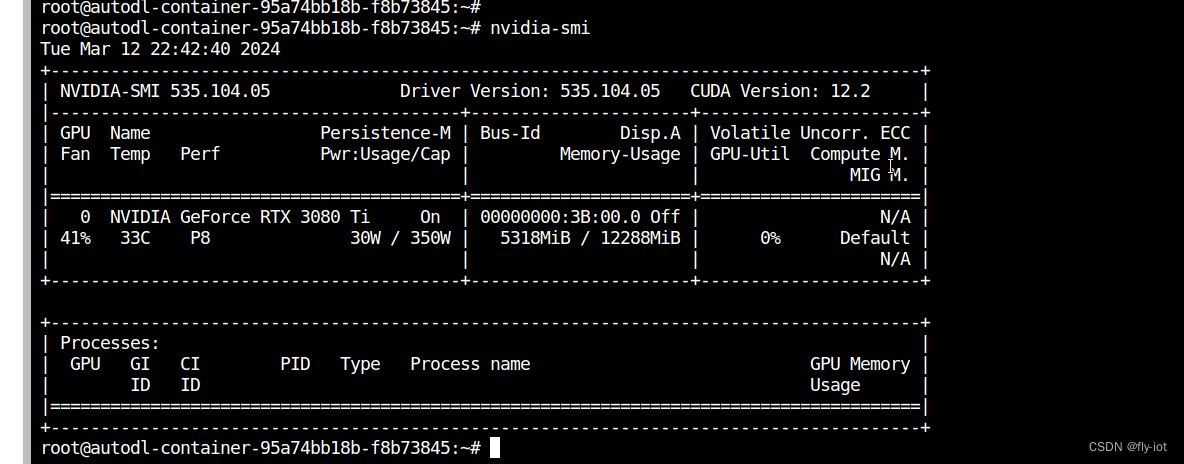
显卡使用资源: