🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972
个人介绍: 研一|统计学|干货分享
擅长Python、Matlab、R等主流编程软件
累计十余项国家级比赛奖项,参与研究经费10w、40w级横向
文章目录
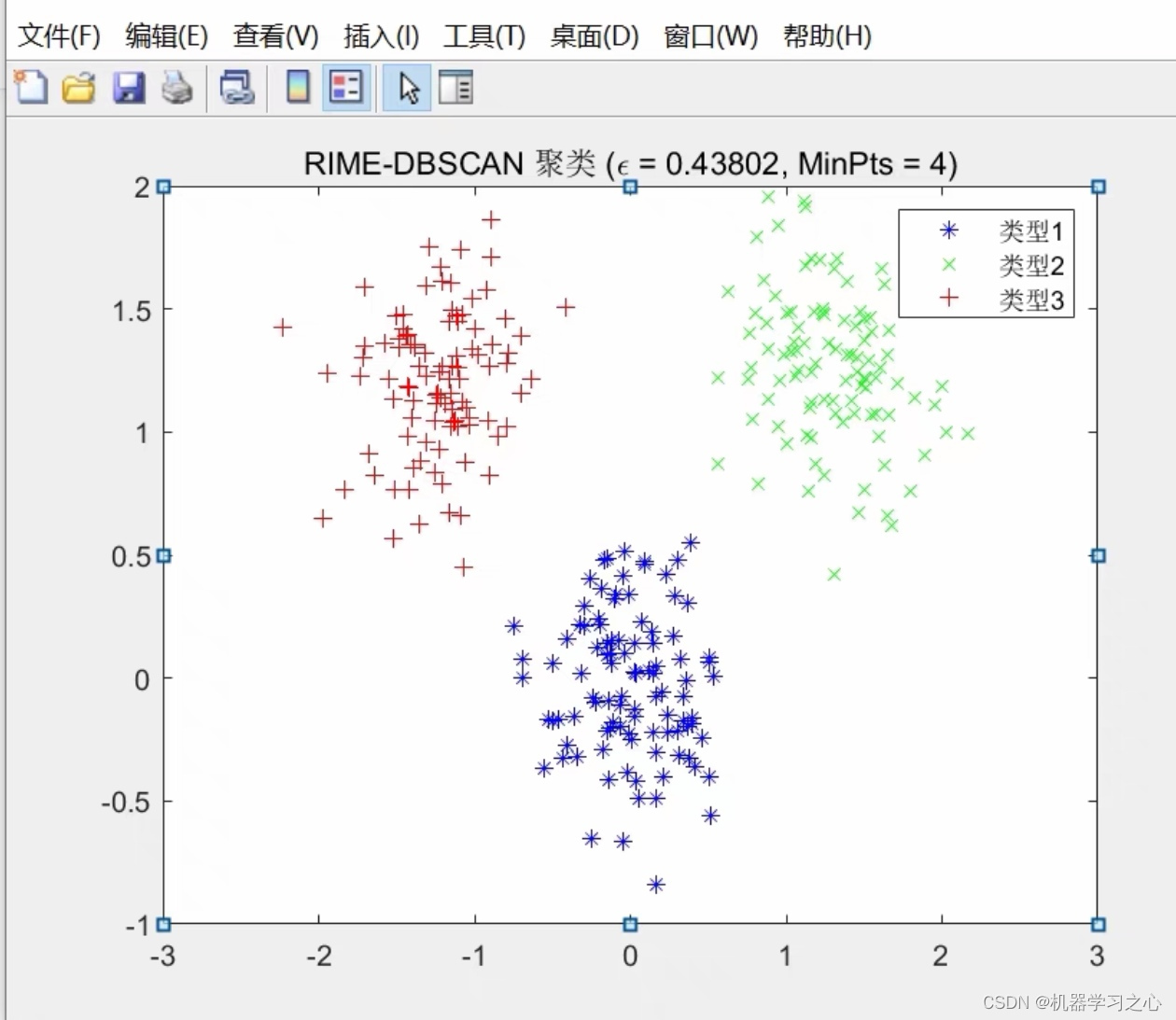
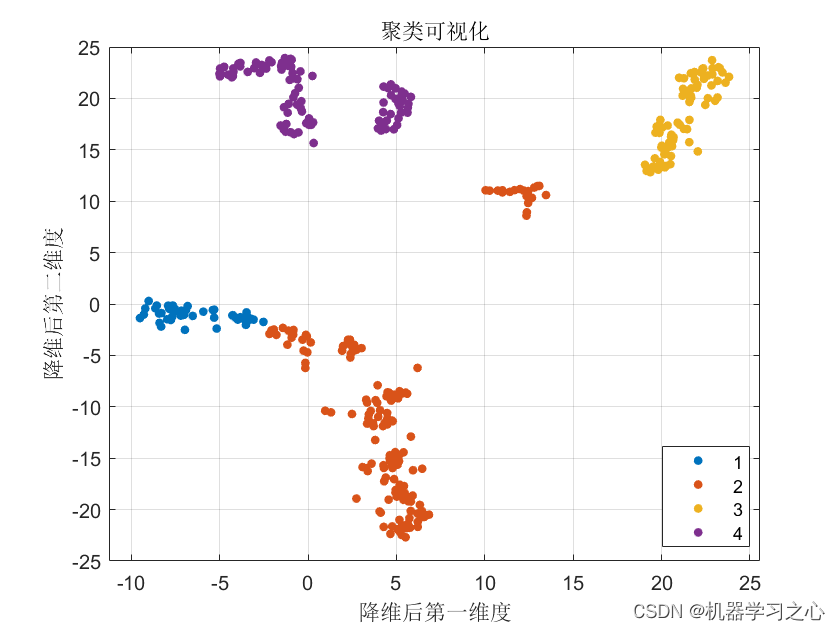
洛杉矶街区数据(LA.Neihborhoods.csv) 这是美国普查局2000年的数据。一共有110个街区,15个变量。变量情况见下表。表中API为涉及学生成绩的Academic Performance Index的缩写。增加单位面积下的人口数(变量名density),试对修改后的数据按照income,age,homes,white和density的数据进行系统聚类和Kmeans聚类分析(分成5类),并根据所分类别和每个街区的经纬度,把各个类用不同的符号画图进行可视化。
1 系统聚类及可视化
运行代码:
w=read.csv("E://mvstats5/data/LA.Neighborhoods.csv")#读入数据
w=data.frame(w,density=w$Population/w$Area)#增加人口密度变量
u=w[,c(1,2,5,6,11,16)]#选择变量
hw=hclust(dist(scale(u[,-1])), "ward.D2") #对标准化的数据做分层聚类, 聚类方法选的"ward.D2"
plot(hw,labels=u[,1],cex=0.6)#画树状图
id=identify(hw)#手工分成5份
rect.hclust(hw,5)
运行结果:

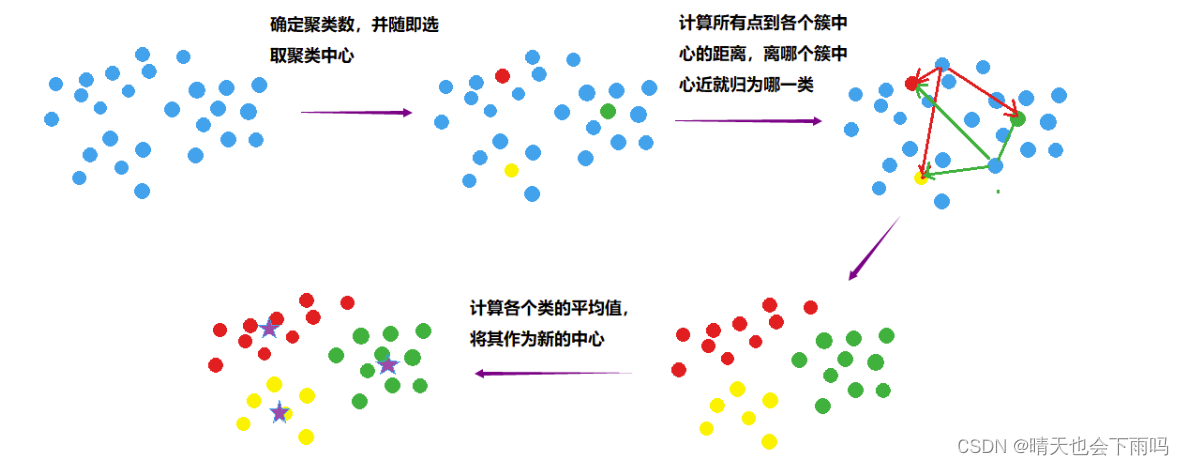
2 KMeans聚类及可视化
运行代码:
a=kmeans(scale(u[,-1]),5);ppp=c(7,17,19,21)
plot(w[a$cluster==1,14:15],pch=1,col=1,xlim=c(-118.7,-118.2),ylim=c(33.73,34.32),main="Los Angeles")
for(i in 2:5){
points(w[a$cluster==i,14:15],pch=ppp[i-1],col=2:5)
legend("bottomleft",pch=c(1,ppp),paste("Cluster",1:4))
}
运行结果: