原理分析
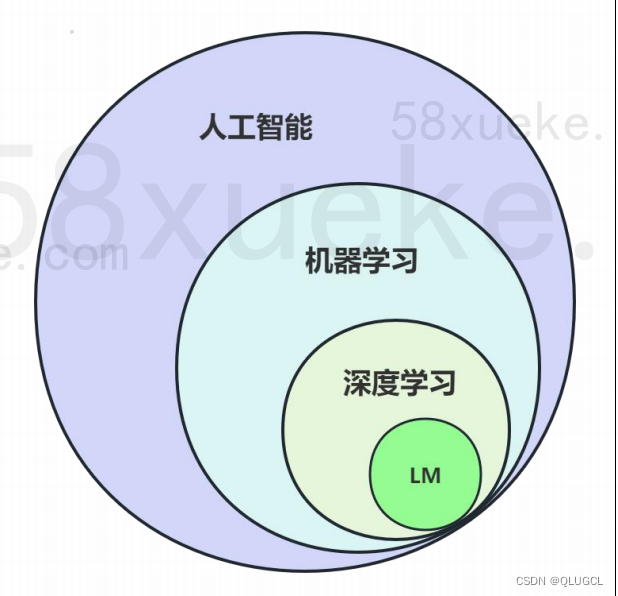
马克思主义哲学-规律篇
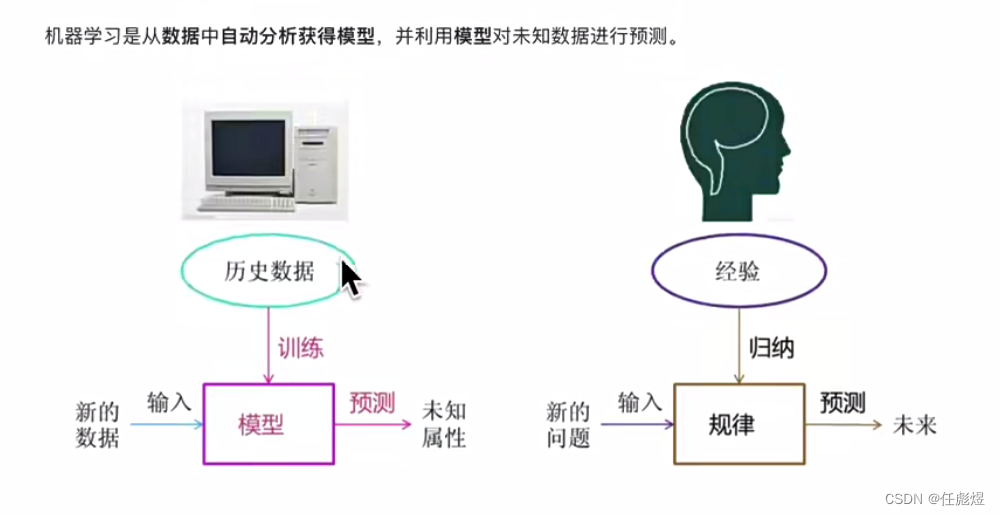
规律客观存在,万事万物皆有规律。
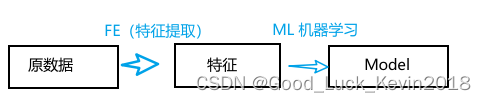
机器学习则是多维角度拆解分析复杂事实数据,发现复杂事实背后的规律,然后将规律用多参数公式表达出来,从而可以套用解决问题。
例如-分类任务:
将西瓜拆分为(x,y,z)三个维度,x=瓜秧卷曲程度,y=瓜皮纹理,z=瓜蒂大小。
ax+by+cz=是|否甜
大量(x1,y1,z1)=>甜,(x2,y2,z2)=>酸,(x3,y3,z3)=>甜等数据来求解a,b,c值。
后续便可以直接带入(Xn,Yn,Zn)到该公式中便可获取结果。
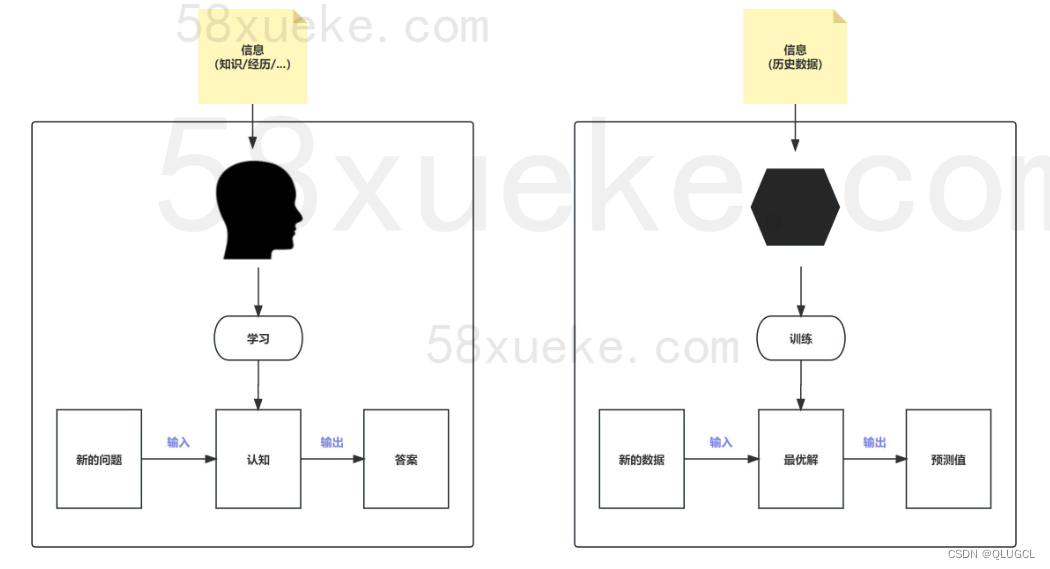
结论:
不论是机器学习还是深度学习,都是对大量数据的学习,掌握数据背后的分布规律,进而对符合该分布的其他数据进行准确预测。
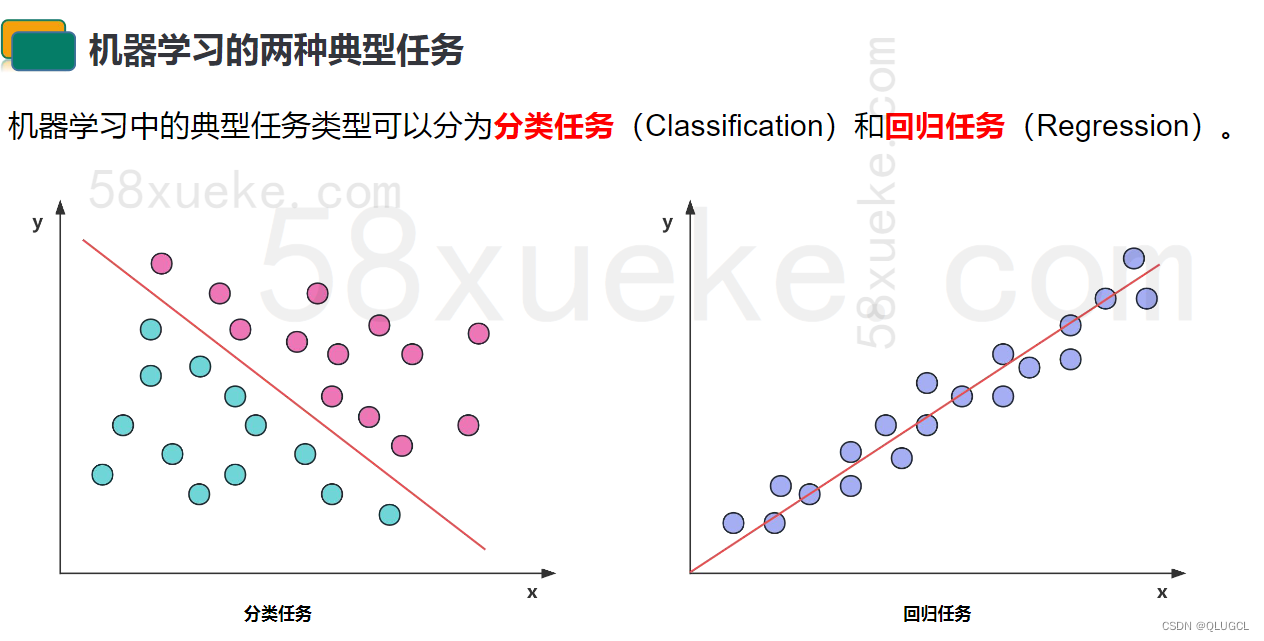
机器学习的两种典型任务
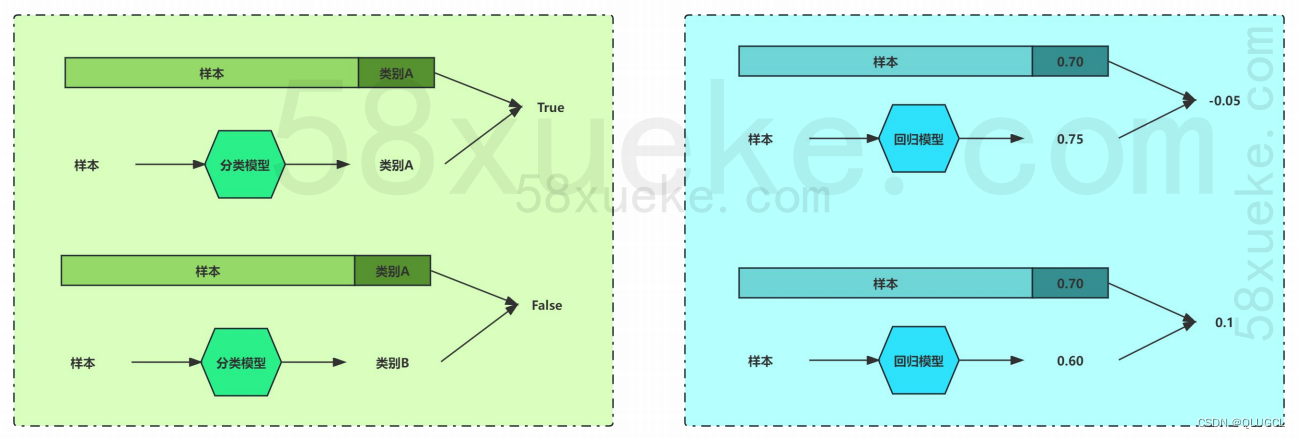
简单的理解,分类任务是对离散值进行预测,根据每个样本的值/特征预测该样本属于类型A、类型B还是类型C,例如情感分类、内容审核,相当于学习了一个分类边界(决策边界),用分类边界把不同类别的数据区分开来。
回归任务是对连续值进行预测,根据每个样本的值/特征预测该样本的具体数值,例如房价预测,股票预测等,相当于学习到了这一组数据背后的分布,能够根据数据的输入预测该数据的取值。
实际上,分类与回归的根本区别在于输出空间是否为一个度量空间。
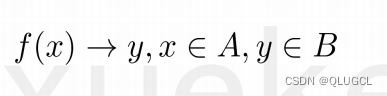
对于分类问题,目的是寻找决策边界,其输出空间B不是度量空间,即“定性”。也就是说,在分类问题中,只有分类“正确”与“错误”之分,至于分类到了类别A还是类别B,没有分别,都是错误数量+1。
对于回归问题,目的是寻找最优拟合,其输出空间B是一个度量空间,即“定量”,通过度量空间衡量预测值与真实值之间的“误差大小”。当真实值为10,预测值为5时,误差为5,预测值为8时,误差为2。
机器学习分类
有监督学习:监督学习利用大量的标注数据来训练模型,对模型的预测值和数据的真实标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。
每条数据都有正确答案,通过模型预测结果与正确答案的误差不断优化模型参数。
无监督学习:无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。
只有数据没有答案,常见的是聚类算法,通过衡量样本之间的距离来划分类别。
半监督学习:利用有标签数据和无标签数据来训练模型。一般假设无标签数据远多于有标签数据。例如先使用有标签数据训练出初始模型,然后用初始模型对无标签数据进行分类,再使用正确分类的无标签数据训练初始模型,不断迭代,优化模型;
利用大量的无标注数据和少量有标注数据进行模型训练
自监督学习:机器学习的标注数据源于数据本身,而不是由人工标注。目前主流大模型的预训练过程都是采用自监督学习,将数据构建成完型填空形式,让模型预测对应内容,实现自监督学习。
通过对数据进行处理,让数据的一部分成为标签,由此构成大规模数据进行模型训练。
正确答案就是数据本身,训练的数据就是挖空数据,大模型填完空,对比完整数据,再次训练。
例如:
原始数据:我去玩剧本杀
挖空数据:我去玩()
大模型:我去玩(走路)----对比正确答案---->再次填空。。。。。。
优势:
可供训练的数据极多且获取容易预处理简单,暴力出奇迹。
远程监督学习:主要用于关系抽取任务,采用bootstrap的思想(自力更生)通过已知三元组在文本中寻找共现句,自动构成有标签数据,进行有监督学习。
基于现有的三元组收集训练数据,进行有监督学习
强化学习:强化学习是智能体根据已有的经验,采取系统或随机的方式,去尝试各种可能答案的方式进行学习,并且智能体会通过环境反馈的奖赏来决定下一步的行为,并为了获得更好的奖赏来进一步强化学习。
以获取更高的环境奖励为目标优化模型
总结
数据
实际上算法工程师大部分时间都是在处理数据,调参,训练,模型效果不好,再调参,再训练。
数据标注是有监督学习最繁杂,重要且难的工作,有了成熟大模型之后就可以代替人工标注,直接用大模型标注好数据然后再训练自己的模型,牵一发动全身,师夷长技以制夷。
----注意确定非敏感数据让GPT标注,防止泄露。
中大厂之间最大的壁垒是数据壁垒,数据很重要。
数据标注(Data Annotation)是人工智能和机器学习领域中的一个重要过程,它涉及将原始数据(如文本、图片、语音、视频等)加上标签或注释,使得机器能够识别和理解这些数据。简而言之,数据标注就是将非结构化的数据转换为结构化的数据,以便机器可以对其进行处理和分析。
例如,在自动驾驶技术的发展过程中,需要大量的图像数据来训练车辆识别道路、行人和各种交通标志。数据标注师会处理这些图像数据,为每张图片添加标签,如“行人”、“自行车”、“红绿灯”等。这些标签帮助机器学习模型识别和分类图像中的不同对象。
具体到自动驾驶的例子,数据标注师可能需要对一张捕捉到的道路场景图片进行标注,标出图片中的车辆、行人、车道线、交通标志等。通过对大量此类图片进行标注,机器学习模型能够学习如何识别和反应这些不同的元素,从而实现在道路上的自主驾驶。
数据标注的过程不仅包括简单的分类,还可以包括更复杂的注释任务,如边界框的绘制(如在图像中标识对象的位置)、属性注释(如描述对象的属性,如颜色、形状等)、关系注释(如描述不同对象之间的关系)以及自由文本注释等。随着人工智能技术的发展,数据标注的要求也越来越高,需要标注的数据从简单的客观信息延伸到更加复杂的主观判断和理解。
机器学习分类解读
当我们谈论机器学习时,有监督学习、无监督学习、半监督学习、自监督学习、远程监督学习和强化学习是常见的学习方式。以下是对每种学习方式的例子,用日常用品来解释。
简单
有监督学习(Supervised Learning):
- 例子:图书分类器
假设你有一堆已经标记好的书籍,每本书都标明了它属于哪个类别(小说、科幻、历史等)。有监督学习就像是让机器学会根据这些标记来预测未标记书籍的类别,使其能够正确地分类新书。
- 例子:图书分类器
无监督学习(Unsupervised Learning):
- 例子:果篮分拣机
想象你有一个摄像头监视着传送带上的水果。无监督学习就是让机器自己学会识别并分拣水果,而不需要提前告诉机器每种水果是什么。机器会自动找到数据中的模式,将相似的水果分组。
- 例子:果篮分拣机
半监督学习(Semi-Supervised Learning):
- 例子:邮件过滤器
假设你有大量已经标记好的垃圾邮件和一些正常邮件,但未标记的邮件较多。半监督学习是让机器根据已知标记的数据进行学习,然后尽可能准确地过滤未标记的邮件,以提高整体过滤效果。
- 例子:邮件过滤器
自监督学习(Self-Supervised Learning):
- 例子:拼图游戏
想象一个拼图游戏,其中一些拼图块已经缺失。自监督学习是让机器学会通过已知的拼图块来预测缺失的拼图块,而不需要额外的标签信息。通过这个过程,机器可以自我生成标签信息。
- 例子:拼图游戏
远程监督学习(Distant Supervision):
- 例子:语音识别
在语音识别中,远程监督学习可能涉及到使用一组正确标记的音频数据,但并非所有都需要人工标注。通过部分标记的数据,机器可以学会识别新的音频数据。
- 例子:语音识别
强化学习(Reinforcement Learning):
- 例子:智能驾驶汽车
将智能驾驶汽车看作一个强化学习代理。汽车通过感知环境(摄像头、雷达等),执行动作(转向、加速、刹车),并根据执行的动作获得奖励或惩罚(遵守交规奖励,违反交规惩罚)。通过不断尝试,汽车学会在不同情境下做出最优的驾驶决策。
- 例子:智能驾驶汽车
复杂
当我们谈论机器学习时,有监督学习、无监督学习、半监督学习、自监督学习、远程监督和强化学习是常见的学习方式。为了更好地理解这些概念,我们可以用日常用品的例子来解释:
有监督学习(Supervised Learning):
- 例子: 想象你是一名水果识别专家,你有一个标有水果名称的图像数据集。每张图片都有相应的标签,比如苹果、橙子或香蕉。
- 核心原理: 算法通过学习已标记的数据(带有标签)来建立模型,然后用这个模型对新的未标记数据进行分类。
无监督学习(Unsupervised Learning):
- 例子: 现在,你只有一堆水果图片,但是没有标签。你的任务是发现这些数据中的模式,例如,将相似的水果归为一组,而无需事先知道水果的名称。
- 核心原理: 算法通过发现数据中的模式和结构,而不依赖于事先的标签来进行学习。
半监督学习(Semi-Supervised Learning):
- 例子: 你有一些带有标签的水果图片,但是大多数数据是没有标签的。半监督学习的任务是在有限的标签数据下,尽可能提高对未标签数据的准确分类。
- 核心原理: 结合有标签和无标签的数据进行学习,以更好地泛化到新数据。
自监督学习(Self-Supervised Learning):
- 例子: 假设你有一组水果图片,但是标签被随机删除了。自监督学习的目标是模型能够自行预测图像中水果的位置,而不是依赖外部标签。
- 核心原理: 模型通过利用数据本身的结构和信息来进行学习,无需外部标签。
远程监督(Distant Supervision):
- 例子: 假设你想创建一个自动评估水果熟度的系统。虽然无法直接获取水果熟度的标签,但你可以使用远程传感器监测水果的颜色,声音等信息作为替代标签。
- 核心原理: 利用间接的、可能不太精确但可获得的监督信号来进行学习。
强化学习(Reinforcement Learning):
- 例子: 想象你是一名机器人控制工程师,你的机器人学会通过尝试和错误来掌握在房间中导航的技能。每次成功导航或失败都会有相应的奖励或惩罚。
- 核心原理: 通过与环境的交互,系统学习在特定环境中采取哪些动作以最大化累积奖励。