为什么要机器学习?
现实世界的问题都比较complex,很难通过手工实现。
机器学习的定义
从数据中获得决策(预测)函数使得机器可以根据数据进行自动学习通过算法能够使机器从大量历史数据中学习规律从而对新样本作出决策。
机器学习本质:机器学习==构建一个映射函数
机器学习的应用:
- 语音识别 :将一段音频映射成文字语言
- 图像识别 :将图片的内容映射成物品文字
- 围棋 :将棋局分布映射成下一步落子的位置
- 对话系统:将问题文字映射成回答文字
机器学习的基本概念
- 样本 (sample):feature+lable,划分为训练集与测试集 == Dataset(芒果)
- 特征 (feature)=》特征向量(feature vector),每一维度都为一个特征,X = [ x0 , x1 ,……xd ] (颜色,气味等)
- 标签 (lable)(好|坏)
- 模型 (mode):结构,f(x)
- 算法 (algorithm):找到 θ \theta θ的方法
每次都要独立同分布地从Dataset中取出样本。即概率相同
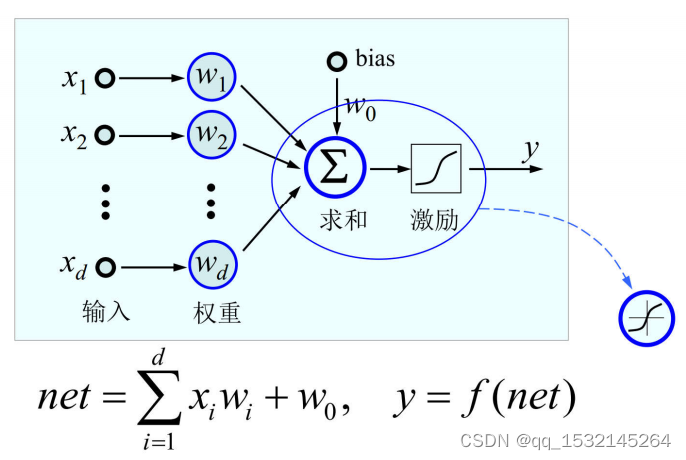
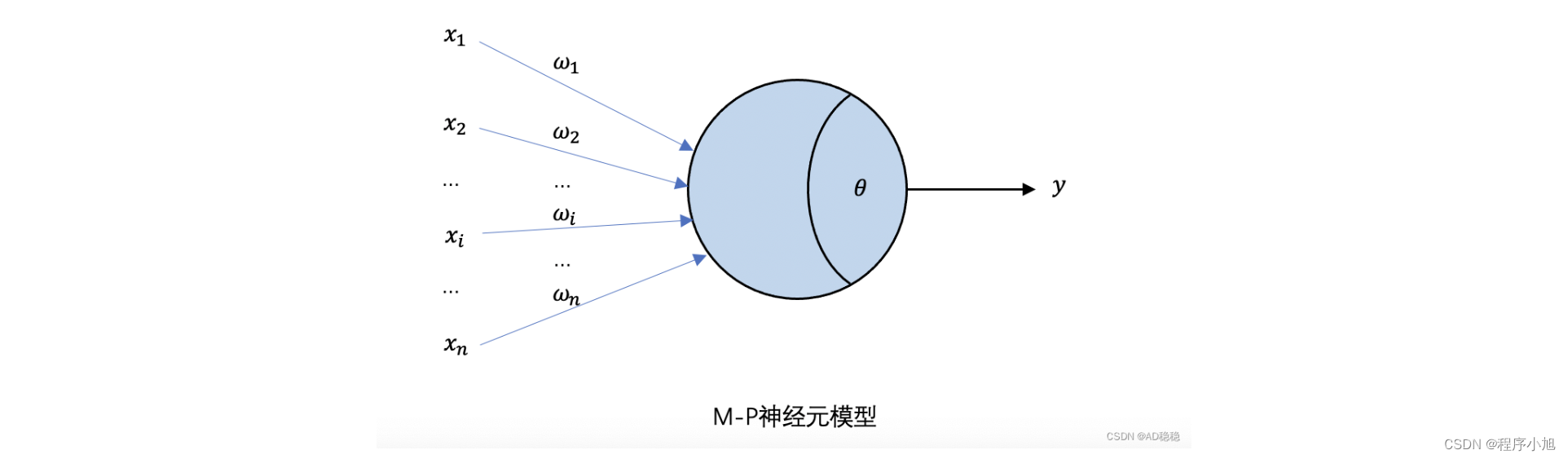
T->M<-Test = 0
预测结果:f(x, θ ) = y ˆ \^y yˆ
φ ( y ∣ x ) = f y ( x , θ ) ∈ ( 0 , 1 ) \varphi (y|x)={f}_{y}(x,\theta )\in (0,1) φ(y∣x)=fy(x,θ)∈(0,1)
解读:当参数为 x x x时,得到结果为y的概率为。 θ \theta θ为参数。
怎样进行机器学习?
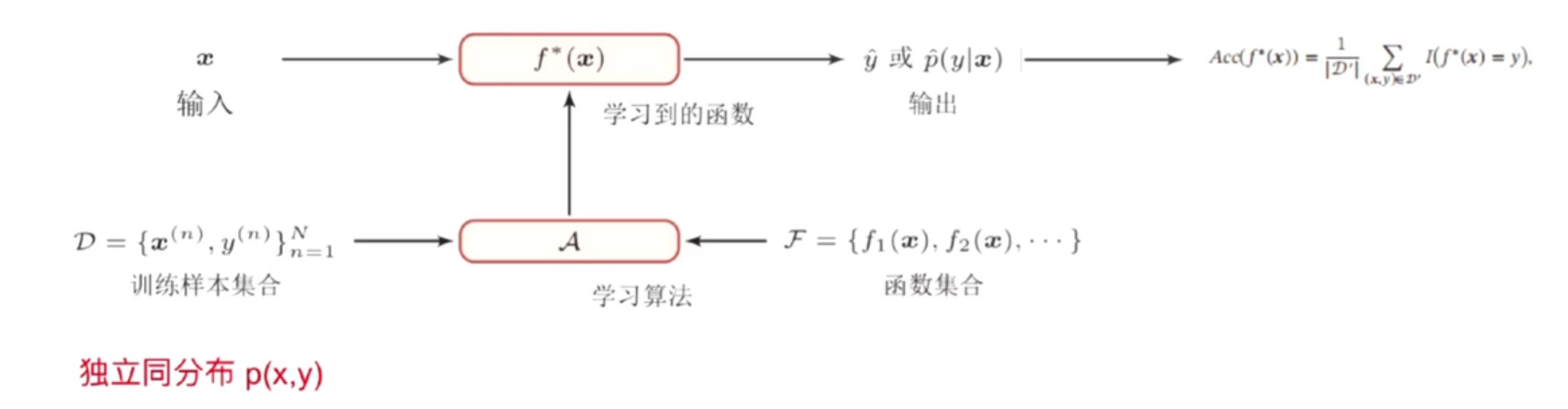
解读:ACC(F*()) , 预测函数的准确性。
机器学习三要素
- 模型
- 线性方法 f ( x , θ ) = ω T x + b f(x,\theta )={\omega }^{T}x+b f(x,θ)=ωTx+b
- 广义线性方法 f ( x , θ ) = ω T ϕ ( x ) + b f(x,\theta )={\omega }^{T}\phi (x)+b f(x,θ)=ωTϕ(x)+b如果 ϕ ( x ) \phi(x) ϕ(x)为可学习的非线性基函数, f ( x , θ ) f(x,\theta ) f(x,θ)则等价为神经网络。
- 学习准则 R ( f ) = E ( x , y ) ˜ p ( x , y ) [ L ( f ( x ) , y ) ] R(f)={E}_{(x,y)\~~p(x,y)}[L(f(x),\, y)] R(f)=E(x,y) ˜p(x,y)[L(f(x),y)]
- 优化 梯度下降
学习准则
-损失函数
- 0-1损失函数
L ( y , f ( x , θ ) ) = { 1 i f y ! = f ( x , θ ) 0 i f y = f ( x , θ ) L(y,\, f(x,\theta ))={\{ }^{0\, if\, y\, =f(x,\theta )\, }_{1\, if\, y\, !=f(x,\theta )} L(y,f(x,θ))={1ify!=f(x,θ)0ify=f(x,θ)
- 平方损失函数
L ( y , y ˆ ) = ( y − f ( x , θ ) ) 2 L(y,\,\^y)=(y\, -\, f(x,\theta ))^2 L(y,yˆ)=(y−f(x,θ))2
若y为概率。则Loss = ∑ ( − p l o g p ˆ ) \sum( -p log \^p) ∑(−plogpˆ),lLoss是每个样本误差的和。
-参数学习
期望风险未知,通过经验风险近似
在训练集: D = { x ( n ) , y ( n ) } , i ∈ ( 1 , N ) D=\{{x^{(n)},y^{(n)} }\},i\in (1,N) D={x(n),y(n)},i∈(1,N)
R D e m p ( θ ) = 1 N ∑ n = 1 N L ( y ( n ) , f ( x ( n ) , θ ) ) {R}^{emp}_{D}(\theta )=\frac {1} {N}\sum ^{N}_{n=1} {L({y}^{(n)},f({x}^{(n)},\theta ))} RDemp(θ)=N1∑n=1NL(y(n),f(x(n),θ))
经验风险最小化:
在选择合适的风险函数后,寻找一个参数 θ \theta θ*,使得经验风险函数最小化。
θ ∗ = a r g θ m i n R D e m p ( θ ) {\theta }^{*}={arg}_{\theta }min{R}^{emp}_{D}(\theta ) θ∗=argθminRDemp(θ)
将机器学习问题转化为一个最优化问题。
优化算法
过拟合
过拟合:经验风险最小化原则,容易导致模型在训练集上错误率很低,但在未知数据上的错误率很高,往往是由于训练数据少和噪声等原因造成的。
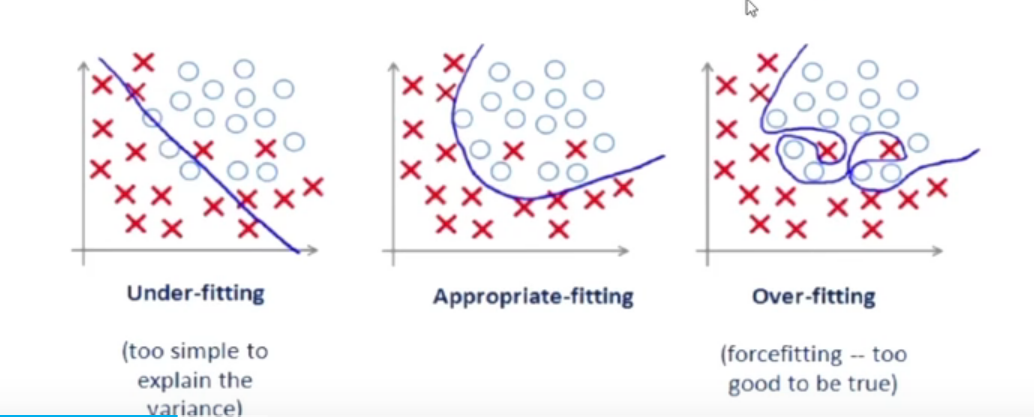
泛化错误
期望风险 !=经验风险
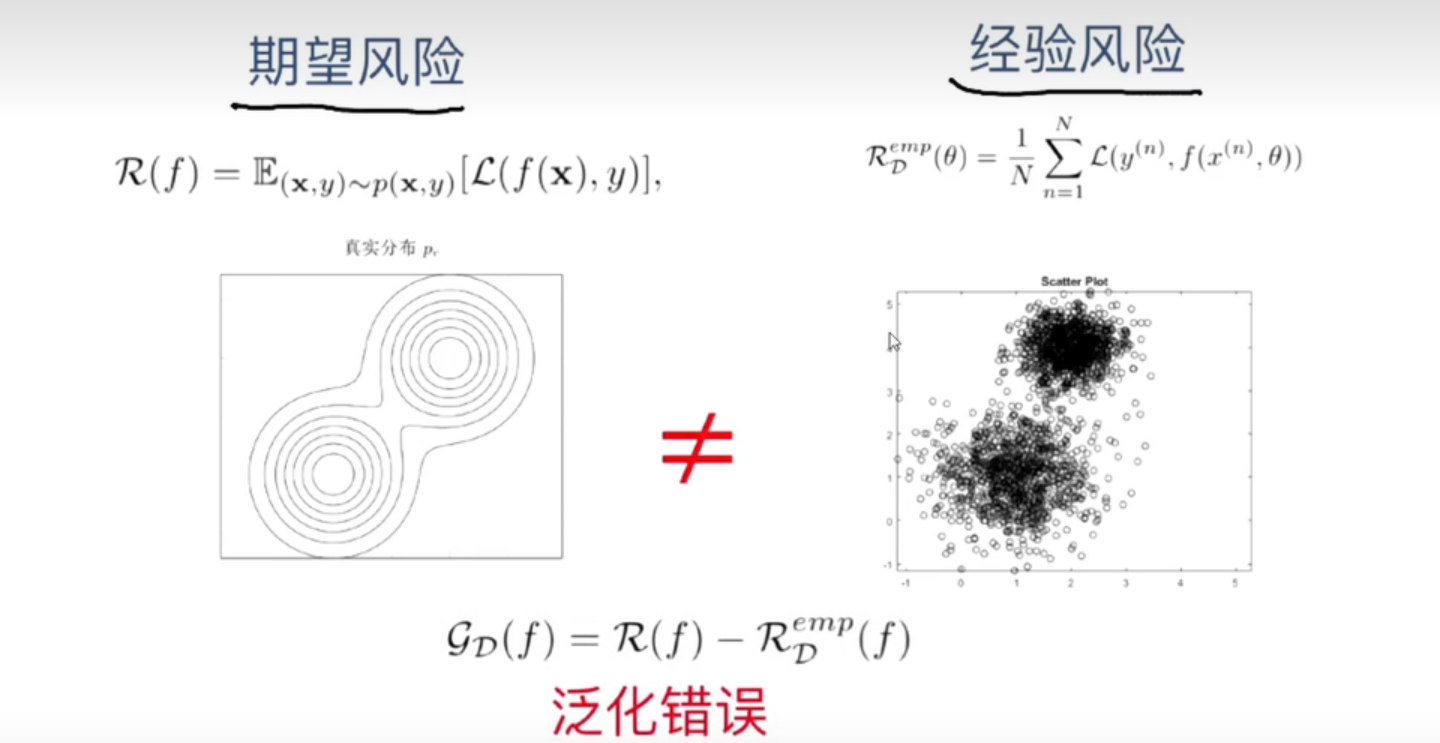
G ( f ) = R ( f ) − R D e m p ( f ) G(f)=R(f)-{R}^{emp}_{D}(f) G(f)=R(f)−RDemp(f)
优化:经验风险最小
正则化:降低模型复杂度
正则化
所有损害优化的方法都是正则化:
- 增加优化约束 L1\L2约束,数据增强
- 干扰优化过程 提前结束,减少不必要的迭代,防止过拟合
最优化问题
机器学习转化为最优化问题。
梯度下降法
α \alpha α:学习率
θ t + 1 = θ t − α ∂ R ( θ ) ∂ θ t = θ t − α 1 N ∑ i = 1 N ∂ L ( θ t , x ( i ) , y ( i ) ) ) ∂ θ {\theta }_{t+1}={\theta }_{t}-\alpha \frac {\partial R(\theta )} {\partial {\theta }_{t}}={\theta }_{t}-\alpha \frac {1} {N}\sum ^{N}_{i=1} {\frac {\partial L({\theta }_{t},{x}^{(i)},{y}^{(i)}))} {\partial \theta }} θt+1=θt−α∂θt∂R(θ)=θt−αN1∑i=1N∂θ∂L(θt,x(i),y(i)))
α \alpha α大小很重要。
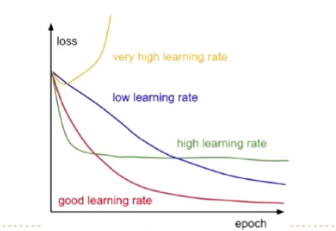
调参对象:超参数:自定义的参数
种类:
- 批量梯度下降法(BGD),每个样本都进行更新。
θ t + 1 = θ t − α ∂ R ( θ ) ∂ θ t = θ t − α 1 N ∑ i = 1 N ∂ L ( θ t , x ( i ) , y ( i ) ) ) ∂ θ {\theta }_{t+1}={\theta }_{t}-\alpha \frac {\partial R(\theta )} {\partial {\theta }_{t}}={\theta }_{t}-\alpha \frac {1} {N}\sum ^{N}_{i=1} {\frac {\partial L({\theta }_{t},{x}^{(i)},{y}^{(i)}))} {\partial \theta }} θt+1=θt−α∂θt∂R(θ)=θt−αN1∑i=1N∂θ∂L(θt,x(i),y(i)))
- 随机梯度下降法(SGD)增量梯度下降法
θ t + 1 = θ t − α ∂ L ( θ t , x ( t ) , y ( t ) ) ∂ θ {\theta }_{t+1}={\theta }_{t}-\alpha \frac {\partial L({\theta }_{t},{x}^{(t)},{y}^{(t)})} {\partial \theta } θt+1=θt−α∂θ∂L(θt,x(t),y(t))
- 小批量随机梯度下降法(MBGD)
θ t + 1 ← θ t − α 1 K ∑ ( x , y ) ∈ δ t ∂ L ( y , f ( x , θ ) ) ∂ θ {\theta }_{t+1}\gets {\theta }_{t}-\alpha \frac {1} {K}\sum _{(x,y)\in {\delta }_{t}} {\frac {\partial L(y,f(x,\theta ))} {\partial \theta }} θt+1←θt−αK1∑(x,y)∈δt∂θ∂L(y,f(x,θ))
随机梯度下降法实现:

参数学习
- 经验风险最小化(最小二乘法)应用于实数
- 结构风险最小化(岭回归)应用于实数
- 最大似然估计 应用于概率
- 最大后验估计 应用于概率
*随机梯度下降法实战
线性回归
线性回归模型
f ( x ; w , b ) = w T x + b f(x;w,b)=w^Tx+b f(x;w,b)=wTx+b
从一维线性回归拓展到多个特征。
增广权重向量和增广特征向量
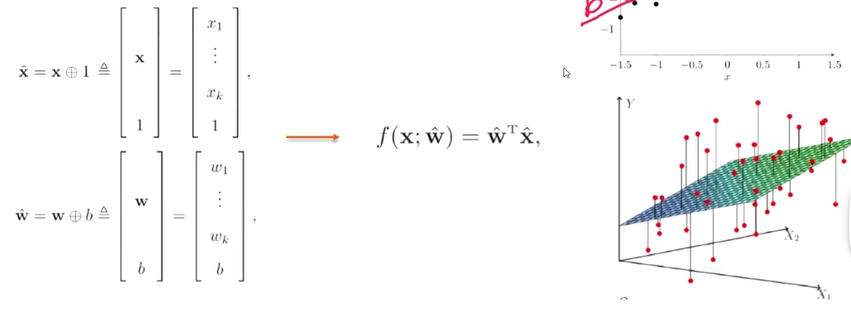
经验风险最小化
最小均方误差算法(Least Mean Squares)LMS
- 模型
f ( x ; w ) = w T x f(x;w)=w^Tx f(x;w)=wTx
- 学习准则
R ( w ) = ∑ n = 1 N L ( y ( n ) , f ( x n ; w ) ) R(w)=\sum ^{N}_{n=1} {L({y}^{(n)},f({x}^{n};w))} R(w)=∑n=1NL(y(n),f(xn;w))
= 1 2 ∑ n = 1 N ( y ( n ) − w T x n ) 2 =\frac {1} {2}\sum ^{N}_{n=1} {({y}^{(n)}-{w}^{T}{x}^{n})^2} =21∑n=1N(y(n)−wTxn)2
= 1 2 ∣ ∣ y − X T w ∣ ∣ 2 =\frac {1} {2}||y-{X}^{T}w||^2 =21∣∣y−XTw∣∣2平方损失函数
- 优化
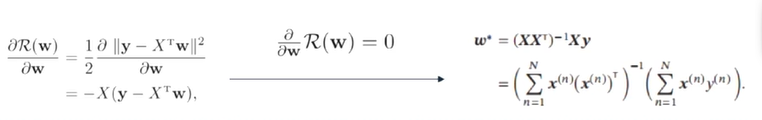
范数:度量向量的大小和长度。
1范数: ∣ ∣ x ∣ ∣ 1 = ∑ i = 1 N ( x i ) ||x||_1=\sum^{N}_{i=1}{(x_i)} ∣∣x∣∣1=∑i=1N(xi)
2范数: ∣ ∣ x ∣ ∣ 2 = ∑ i = 1 N x i 2 ||x||_2 = \sqrt {\sum^{N}_{i=1}{{x_i}^2}} ∣∣x∣∣2=∑i=1Nxi2
最小二乘法前提:特征之间线性不相关
解决办法:使用主成分分析法处理特征
结构风险法-岭回归

从概率角度看线性回归
假设标签y为一个随机变量,使其服从均值为 f ( x ; w ) = w T f(x;w)=w^T f(x;w)=wT,方差为 σ 2 \sigma^2 σ2的高斯分布
p ( y ∣ x ; w , σ ) = N ( y ; w T x , σ 2 ) = 1 2 π σ e x p ( − ( y − w T x ) 2 2 σ 2 ) p(y|x;w,\sigma)=N(y;w^Tx,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y-w^Tx)^2}{2\sigma^2}) p(y∣x;w,σ)=N(y;wTx,σ2)=2πσ1exp(−2σ2(y−wTx)2)
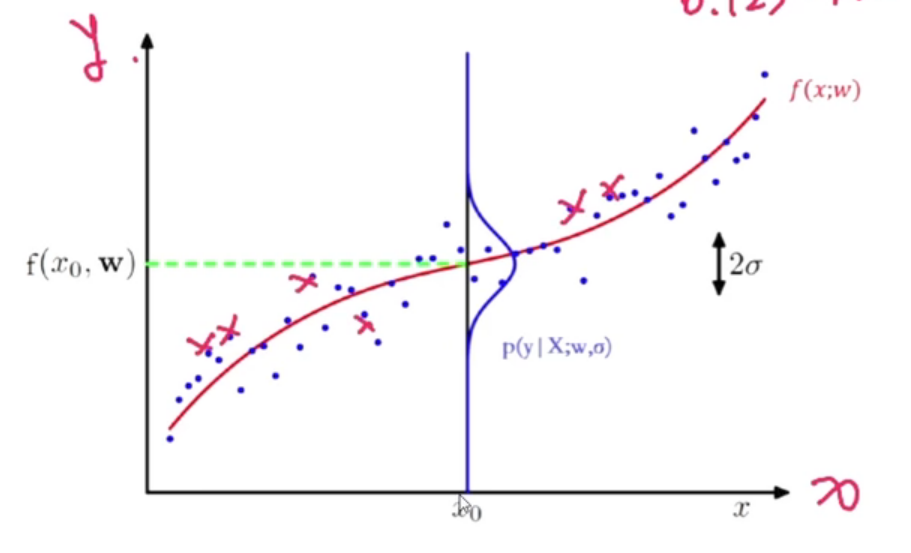
解读:如何判断好坏,p(y|X;w, σ \sigma σ)凸点,距离 x 0 x_0 x0的距离越大,则误差越大,越小则误差越小。
要求样本独立同分布。


*最小二乘法实战
更新方法:
L o s s = 1 2 ( y − y ˆ ) 2 Loss=\frac{1}{2}(y-\^y)^2 Loss=21(y−yˆ)2
w t + 1 < w t − α ∂ R ∂ w w_{t+1}<w_t-\alpha\frac{\partial R}{\partial w} wt+1<wt−α∂w∂R
∂ R ∂ w = − X ( y − X T w ) \frac{\partial R}{\partial w}=-X(y-X^Tw) ∂w∂R=−X(y−XTw)
w ˆ = w , b \^w={w,b} wˆ=w,b
x ˆ = x , 1 \^x=x,1 xˆ=x,1
最小二乘法实战.ipynb
偏差与方法-理论与定理
模型选择:
- 拟合能力强的模型一般复杂度比较高,容易过拟合
- 如果限制模型复杂度,降低拟合能力,可能会欠拟合
偏差与方差分解
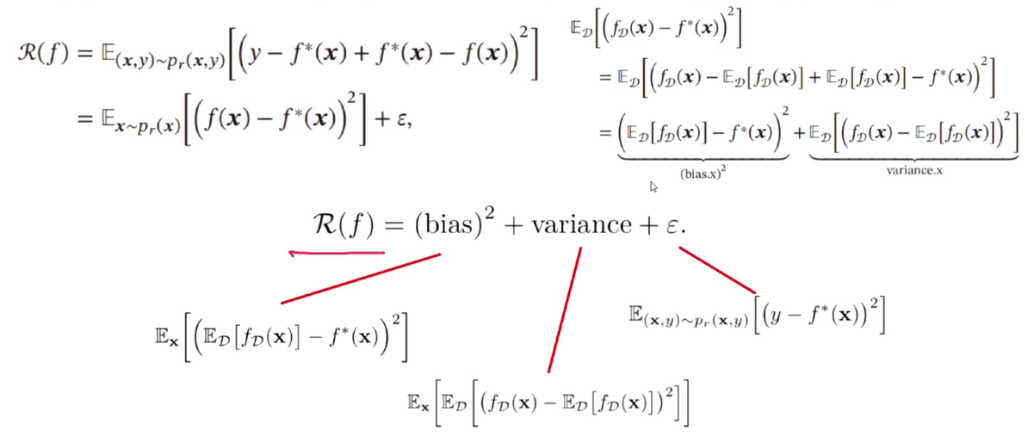
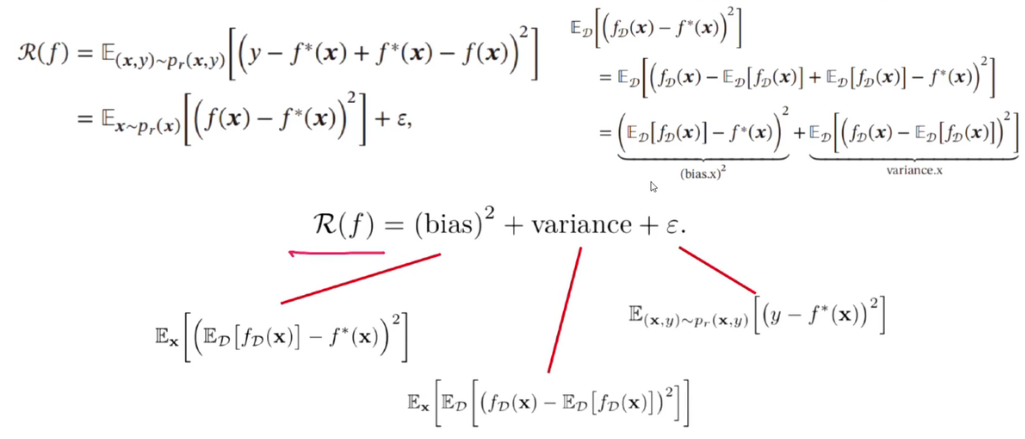
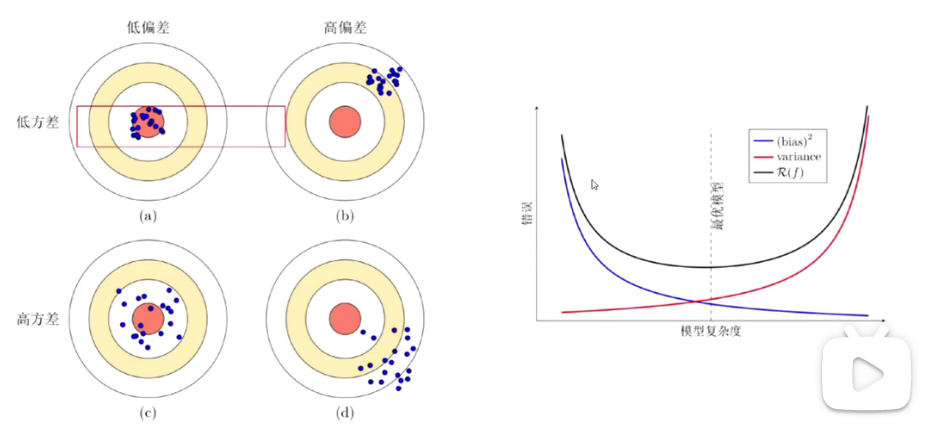
集成模型:有效降低方差的方法
集成模型:
f ( c ) ( x ) = 1 M ∑ m = 1 M f m ( x ) f^{(c)}(x)=\frac{1}{M}\sum^{M}_{m=1}{f_m(x)} f(c)(x)=M1∑m=1Mfm(x)
通过多个高方差模型的平均来降低方差。
集成模型的期望错误大于等于所有模型的平均期望错误的 1 M \frac{1}{M} M1,小于等于所有模型的平均期望错误。
R ˉ ( f ) ≥ R ( f ( c ) ) ≥ 1 M R ˉ f \bar{R}(f)\geq R(f^{(c)})\geq \frac{1}{M}\bar{R}{f} Rˉ(f)≥R(f(c))≥M1Rˉf

常用评价指标
- 准确率:分类正确的样本数 与 样本总数之比。
- 错误率
- 查准率:被正确检索的样本数 与 被检索到样本总数之比。 P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP
- 查全率:被正确检索的样本数 与 应当被检索到的样本数之比。 R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
- F值
- 宏平均与微平均
- AUC曲线
- ROC曲线
- PR曲线
- 交叉验证 k值
- **TP:**被检索到正样本,实际也是正样本(正确识别)
在本例表现为:预测及格,实际也及格。 - **FP:**被检索到正样本,实际是负样本(一类错误识别)
在本例表现为:预测及格,实际不及格。 - **FN:**未被检索到正样本,实际是正样本。(二类错误识别)
在本例表现为:预测不及格,实际及格了。 - **TN:**未被检索到正样本,实际也是负样本。(正确识别)
在本例表现为:预测不及格,实际也不及格。
| | 正类 | 负类 |
| — | — | — |
| 被检索到 | True Positive | False Positive |
| 未被检索到 | False Negative | True Negative |

了解即可:

奥卡姆剃刀原则
如无必要,勿增实体(即"简单有效原理")
作业:
实现随机梯度下降,批量随机梯度下降,批量梯度下降
import numpy as np
import random
# y = 3x+8
random.seed(10)
x = np.arange(0,50)
b = np.ones(50)
for i in range(50):
b[i] = (np.random.rand()*2-1)*5
# print(b)
y = 3*x+80+b
y
array([ 81.47383544, 82.05011071, 88.91998784, 85.06878128,
95.3316403 , 94.61717627, 100.56953448, 96.86971355,
102.04104581, 102.68684407, 107.47490817, 113.81682423,
112.56549793, 114.73075846, 121.05677389, 126.00655417,
126.29178878, 130.98361654, 136.15910122, 132.69109131,
135.86825161, 139.41705741, 141.71029563, 150.85720817,
153.03651871, 151.97460508, 155.77653884, 163.50484161,
159.91390695, 164.08185928, 170.82715679, 175.04020514,
172.30211409, 180.19252806, 186.77344755, 180.78071184,
185.72654324, 192.30381679, 197.12214301, 201.68161869,
202.36769656, 204.24656199, 210.48633622, 207.74129985,
209.76883867, 215.17008898, 216.2746035 , 219.00155788,
225.87335376, 222.39711294])
x.reshape((50,1))
y.reshape((50,1))
array([[ 81.47383544],
[ 82.05011071],
[ 88.91998784],
[ 85.06878128],
[ 95.3316403 ],
[ 94.61717627],
[100.56953448],
[ 96.86971355],
[102.04104581],
[102.68684407],
[107.47490817],
[113.81682423],
[112.56549793],
[114.73075846],
[121.05677389],
[126.00655417],
[126.29178878],
[130.98361654],
[136.15910122],
[132.69109131],
[135.86825161],
[139.41705741],
[141.71029563],
[150.85720817],
[153.03651871],
[151.97460508],
[155.77653884],
[163.50484161],
[159.91390695],
[164.08185928],
[170.82715679],
[175.04020514],
[172.30211409],
[180.19252806],
[186.77344755],
[180.78071184],
[185.72654324],
[192.30381679],
[197.12214301],
[201.68161869],
[202.36769656],
[204.24656199],
[210.48633622],
[207.74129985],
[209.76883867],
[215.17008898],
[216.2746035 ],
[219.00155788],
[225.87335376],
[222.39711294]])
x = x[:,np.newaxis]
y = y[:,np.newaxis]
data = np.concatenate((x,y),axis = 1)
data
array([[ 0. , 81.47383544],
[ 1. , 82.05011071],
[ 2. , 88.91998784],
[ 3. , 85.06878128],
[ 4. , 95.3316403 ],
[ 5. , 94.61717627],
[ 6. , 100.56953448],
[ 7. , 96.86971355],
[ 8. , 102.04104581],
[ 9. , 102.68684407],
[ 10. , 107.47490817],
[ 11. , 113.81682423],
[ 12. , 112.56549793],
[ 13. , 114.73075846],
[ 14. , 121.05677389],
[ 15. , 126.00655417],
[ 16. , 126.29178878],
[ 17. , 130.98361654],
[ 18. , 136.15910122],
[ 19. , 132.69109131],
[ 20. , 135.86825161],
[ 21. , 139.41705741],
[ 22. , 141.71029563],
[ 23. , 150.85720817],
[ 24. , 153.03651871],
[ 25. , 151.97460508],
[ 26. , 155.77653884],
[ 27. , 163.50484161],
[ 28. , 159.91390695],
[ 29. , 164.08185928],
[ 30. , 170.82715679],
[ 31. , 175.04020514],
[ 32. , 172.30211409],
[ 33. , 180.19252806],
[ 34. , 186.77344755],
[ 35. , 180.78071184],
[ 36. , 185.72654324],
[ 37. , 192.30381679],
[ 38. , 197.12214301],
[ 39. , 201.68161869],
[ 40. , 202.36769656],
[ 41. , 204.24656199],
[ 42. , 210.48633622],
[ 43. , 207.74129985],
[ 44. , 209.76883867],
[ 45. , 215.17008898],
[ 46. , 216.2746035 ],
[ 47. , 219.00155788],
[ 48. , 225.87335376],
[ 49. , 222.39711294]])
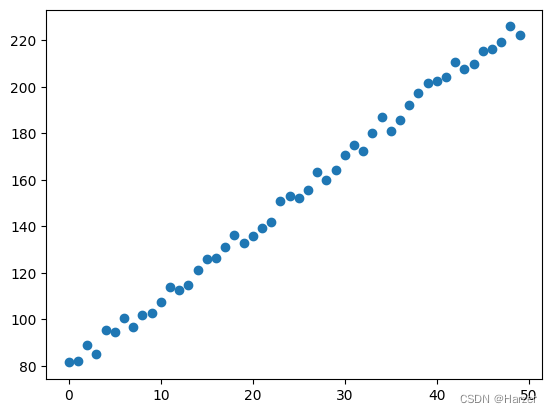
draw data point
import matplotlib.pyplot as plt
plt.scatter(x, y)
<matplotlib.collections.PathCollection at 0x1dbda582508>
随机梯度下降算法
a = 0.001
theta =1
bias = 1
loss_list = []
epselon = 100
flag = True
n = 30
epoch = 0
val = data[30:]
train_data = np.array(data[:30])
while flag:
np.random.shuffle(train_data)
for i in range(n):
xx = train_data[i][0]
yy = train_data[i][1]
theta = theta + a*(yy - theta*xx-bias)*xx
bias = bias + a*(yy - theta*xx-bias)
loss = np.sum(0.5*(val[:,1]-(val[:,0]*theta+bias))**2)
loss_list.append(loss)
print("epoch:%5d theta: %6.5f bias:%6.5f loss:%6.5f"%(epoch,theta, bias, loss) )
epoch = epoch + 1
if loss <= epselon :
flag = False
break
epoch: 0 theta: 8.23710 bias:1.98866 loss:175429.63727
epoch: 1 theta: 7.91997 bias:2.70179 loss:145290.81219
epoch: 2 theta: 7.48218 bias:3.38115 loss:107766.18590
epoch: 3 theta: 6.45480 bias:4.03911 loss:40740.84579
epoch: 4 theta: 7.18155 bias:4.77317 loss:86926.79316
epoch: 5 theta: 6.54729 bias:5.46762 loss:47372.03354
epoch: 6 theta: 6.49361 bias:6.16048 loss:45391.83958
epoch: 7 theta: 6.29115 bias:6.85567 loss:36086.80867
epoch: 8 theta: 6.37115 bias:7.52667 loss:40773.50486
epoch: 9 theta: 7.34032 bias:8.19749 loss:105773.67943
epoch: 10 theta: 6.20046 bias:8.84165 loss:34098.59929
epoch: 11 theta: 7.68010 bias:9.53649 loss:138409.82772
epoch: 12 theta: 6.40847 bias:10.11052 loss:45954.02448
epoch: 13 theta: 6.50293 bias:10.73895 loss:52013.01694
epoch: 14 theta: 6.05552 bias:11.36479 loss:30355.45389
epoch: 15 theta: 6.35081 bias:12.01049 loss:45335.94981
epoch: 16 theta: 6.81136 bias:12.64291 loss:74239.65065
epoch: 17 theta: 6.30484 bias:13.24738 loss:44491.04759
epoch: 18 theta: 5.52229 bias:13.84684 loss:13443.27181
epoch: 19 theta: 6.13493 bias:14.48579 loss:37435.64025
epoch: 20 theta: 6.64870 bias:15.11415 loss:67407.56659
epoch: 21 theta: 6.21778 bias:15.70239 loss:43055.08463
epoch: 22 theta: 6.82282 bias:16.32201 loss:81320.88444
epoch: 23 theta: 5.37470 bias:16.87146 loss:11398.52728
epoch: 24 theta: 6.80477 bias:17.49014 loss:82072.19217
epoch: 25 theta: 6.01759 bias:18.02370 loss:35926.04120
epoch: 26 theta: 6.07468 bias:18.60833 loss:39376.66184
epoch: 27 theta: 5.83988 bias:19.15966 loss:29183.37570
epoch: 28 theta: 5.88388 bias:19.73058 loss:31694.72684
epoch: 29 theta: 5.98413 bias:20.31020 loss:36974.07480
epoch: 30 theta: 5.28537 bias:20.84857 loss:11537.66773
epoch: 31 theta: 5.52916 bias:21.40659 loss:19323.12192
epoch: 32 theta: 6.35320 bias:21.95678 loss:59290.31297
epoch: 33 theta: 5.66277 bias:22.46947 loss:25204.20846
epoch: 34 theta: 6.51033 bias:23.01264 loss:70996.11021
epoch: 35 theta: 5.55933 bias:23.50338 loss:22204.24038
epoch: 36 theta: 5.07841 bias:24.00584 loss:8357.61729
epoch: 37 theta: 5.79236 bias:24.55055 loss:32830.78907
epoch: 38 theta: 5.38051 bias:25.00096 loss:17246.92828
epoch: 39 theta: 5.60776 bias:25.51151 loss:25944.84733
epoch: 40 theta: 5.54913 bias:26.01463 loss:24115.02768
epoch: 41 theta: 5.82984 bias:26.53131 loss:36822.87106
epoch: 42 theta: 5.45363 bias:27.00947 loss:21434.51494
epoch: 43 theta: 6.61249 bias:27.51534 loss:85926.42383
epoch: 44 theta: 5.81519 bias:27.96601 loss:37802.13007
epoch: 45 theta: 5.80839 bias:28.45804 loss:38054.62943
epoch: 46 theta: 5.24612 bias:28.90846 loss:15963.47787
epoch: 47 theta: 5.26451 bias:29.37339 loss:16903.77375
epoch: 48 theta: 5.72077 bias:29.85376 loss:35479.48232
epoch: 49 theta: 5.52206 bias:30.30901 loss:27191.02568
epoch: 50 theta: 4.95824 bias:30.75992 loss:9287.04839
epoch: 51 theta: 5.31422 bias:31.23640 loss:20103.00961
epoch: 52 theta: 6.63177 bias:31.69771 loss:95144.76462
epoch: 53 theta: 5.58924 bias:32.12356 loss:31973.96281
epoch: 54 theta: 5.39406 bias:32.57985 loss:24273.36084
epoch: 55 theta: 5.20461 bias:33.01243 loss:17821.16092
epoch: 56 theta: 5.76137 bias:33.47353 loss:41823.33551
epoch: 57 theta: 5.72324 bias:33.91089 loss:40426.49986
epoch: 58 theta: 5.33483 bias:34.34822 loss:23643.57057
epoch: 59 theta: 5.47715 bias:34.75891 loss:29863.98874
epoch: 60 theta: 5.22375 bias:35.16894 loss:20274.01943
epoch: 61 theta: 5.48748 bias:35.59355 loss:31206.03360
epoch: 62 theta: 4.76570 bias:35.97474 loss:7757.53140
epoch: 63 theta: 5.29239 bias:36.38043 loss:23911.48131
epoch: 64 theta: 5.06555 bias:36.78579 loss:16271.21867
epoch: 65 theta: 5.13403 bias:37.19747 loss:18860.98568
epoch: 66 theta: 5.45586 bias:37.59714 loss:31973.41918
epoch: 67 theta: 5.23504 bias:37.98499 loss:23208.08388
epoch: 68 theta: 5.19591 bias:38.37659 loss:22093.92504
epoch: 69 theta: 4.72973 bias:38.75065 loss:8433.08478
epoch: 70 theta: 5.12476 bias:39.15523 loss:20196.26657
epoch: 71 theta: 4.89752 bias:39.51573 loss:13197.13451
epoch: 72 theta: 5.33955 bias:39.90956 loss:29344.10699
epoch: 73 theta: 5.30876 bias:40.28527 loss:28422.83775
epoch: 74 theta: 5.08711 bias:40.65479 loss:20154.04961
epoch: 75 theta: 4.70442 bias:41.01697 loss:9107.71221
epoch: 76 theta: 4.66851 bias:41.37927 loss:8478.36077
epoch: 77 theta: 5.13233 bias:41.76141 loss:22799.09770
epoch: 78 theta: 5.35272 bias:42.12370 loss:32305.02807
epoch: 79 theta: 5.22255 bias:42.47475 loss:27053.56440
epoch: 80 theta: 4.94089 bias:42.81512 loss:16966.88222
epoch: 81 theta: 5.28378 bias:43.16027 loss:30367.17420
epoch: 82 theta: 5.05503 bias:43.51083 loss:21507.12719
epoch: 83 theta: 4.90415 bias:43.83516 loss:16580.31376
epoch: 84 theta: 4.96622 bias:44.16043 loss:18910.82105
epoch: 85 theta: 5.13054 bias:44.48079 loss:25307.14021
epoch: 86 theta: 5.03609 bias:44.80316 loss:21971.44125
epoch: 87 theta: 4.94073 bias:45.12048 loss:18838.37608
epoch: 88 theta: 4.96141 bias:45.45847 loss:19845.09955
epoch: 89 theta: 4.32176 bias:45.76840 loss:3905.06339
epoch: 90 theta: 4.93575 bias:46.10448 loss:19497.11614
epoch: 91 theta: 4.57025 bias:46.41588 loss:9017.67334
epoch: 92 theta: 5.00986 bias:46.73927 loss:22759.63453
epoch: 93 theta: 4.61426 bias:47.05455 loss:10476.68641
epoch: 94 theta: 4.61095 bias:47.36264 loss:10583.00847
epoch: 95 theta: 5.12326 bias:47.66429 loss:28201.77855
epoch: 96 theta: 4.37337 bias:47.94112 loss:5649.60700
epoch: 97 theta: 5.07463 bias:48.24795 loss:26771.32729
epoch: 98 theta: 4.63929 bias:48.53118 loss:12087.75582
epoch: 99 theta: 4.10186 bias:48.79867 loss:2004.70820
epoch: 100 theta: 5.05067 bias:49.11266 loss:26656.32597
epoch: 101 theta: 4.72259 bias:49.40203 loss:15130.92825
epoch: 102 theta: 4.26982 bias:49.67653 loss:4564.94494
epoch: 103 theta: 4.54205 bias:49.97678 loss:10443.77740
epoch: 104 theta: 4.37286 bias:50.24152 loss:6716.52769
epoch: 105 theta: 4.80907 bias:50.53391 loss:18852.26379
epoch: 106 theta: 4.10525 bias:50.77546 loss:2575.16330
epoch: 107 theta: 4.47826 bias:51.04035 loss:9499.07141
epoch: 108 theta: 4.35426 bias:51.30769 loss:6863.26160
epoch: 109 theta: 4.54485 bias:51.58306 loss:11539.56988
epoch: 110 theta: 4.45275 bias:51.85027 loss:9357.77232
epoch: 111 theta: 4.04837 bias:52.09961 loss:2274.92845
epoch: 112 theta: 4.59669 bias:52.37894 loss:13533.18069
epoch: 113 theta: 4.52481 bias:52.63536 loss:11690.09001
epoch: 114 theta: 4.66032 bias:52.88749 loss:15840.68713
epoch: 115 theta: 4.30600 bias:53.13954 loss:6783.39330
epoch: 116 theta: 4.25400 bias:53.39526 loss:5879.39635
epoch: 117 theta: 4.26893 bias:53.63982 loss:6282.60458
epoch: 118 theta: 4.09990 bias:53.87853 loss:3493.88404
epoch: 119 theta: 4.74994 bias:54.12558 loss:19854.47745
epoch: 120 theta: 4.56853 bias:54.35292 loss:14123.19757
epoch: 121 theta: 4.44230 bias:54.59086 loss:10766.32847
epoch: 122 theta: 4.29918 bias:54.82669 loss:7500.87462
epoch: 123 theta: 4.36695 bias:55.07548 loss:9181.13605
epoch: 124 theta: 4.36226 bias:55.31941 loss:9211.12548
epoch: 125 theta: 4.55279 bias:55.55286 loss:14530.95660
epoch: 126 theta: 4.20280 bias:55.78304 loss:6006.73847
epoch: 127 theta: 4.25802 bias:56.02036 loss:7240.97738
epoch: 128 theta: 4.20827 bias:56.25079 loss:6335.34060
epoch: 129 theta: 4.40471 bias:56.47765 loss:10986.60064
epoch: 130 theta: 4.33662 bias:56.69818 loss:9403.00629
epoch: 131 theta: 4.08119 bias:56.91226 loss:4331.57720
epoch: 132 theta: 4.23819 bias:57.14276 loss:7400.46508
epoch: 133 theta: 3.94691 bias:57.35708 loss:2562.47541
epoch: 134 theta: 4.27584 bias:57.58506 loss:8477.71074
epoch: 135 theta: 4.13684 bias:57.78408 loss:5676.22502
epoch: 136 theta: 3.95479 bias:57.98970 loss:2856.39484
epoch: 137 theta: 4.27452 bias:58.21085 loss:8801.69107
epoch: 138 theta: 4.24592 bias:58.41982 loss:8258.87784
epoch: 139 theta: 4.46004 bias:58.62524 loss:14004.03449
epoch: 140 theta: 4.01725 bias:58.81785 loss:4046.23462
epoch: 141 theta: 4.16363 bias:59.02299 loss:6795.57671
epoch: 142 theta: 4.00066 bias:59.22561 loss:3941.13943
epoch: 143 theta: 4.21896 bias:59.42789 loss:8205.09975
epoch: 144 theta: 3.99848 bias:59.61499 loss:4054.81241
epoch: 145 theta: 4.34838 bias:59.82041 loss:11663.43369
epoch: 146 theta: 3.99679 bias:60.00556 loss:4178.74524
epoch: 147 theta: 3.87157 bias:60.18698 loss:2473.46038
epoch: 148 theta: 4.10128 bias:60.38445 loss:6208.41972
epoch: 149 theta: 4.02803 bias:60.57062 loss:4932.28928
epoch: 150 theta: 4.03253 bias:60.75499 loss:5090.52205
epoch: 151 theta: 3.92822 bias:60.94203 loss:3476.39567
epoch: 152 theta: 3.97120 bias:61.12344 loss:4203.56190
epoch: 153 theta: 3.99798 bias:61.31062 loss:4723.87972
epoch: 154 theta: 4.13926 bias:61.49802 loss:7557.70517
epoch: 155 theta: 3.97991 bias:61.67133 loss:4566.14942
epoch: 156 theta: 4.07514 bias:61.85264 loss:6400.16123
epoch: 157 theta: 4.01370 bias:62.02761 loss:5309.12378
epoch: 158 theta: 3.88751 bias:62.20766 loss:3331.82417
epoch: 159 theta: 3.56972 bias:62.37253 loss:414.91482
epoch: 160 theta: 3.79898 bias:62.55237 loss:2287.87792
epoch: 161 theta: 3.95333 bias:62.71713 loss:4547.41728
epoch: 162 theta: 3.81956 bias:62.88210 loss:2636.33963
epoch: 163 theta: 3.87927 bias:63.05638 loss:3511.13658
epoch: 164 theta: 3.77989 bias:63.21199 loss:2251.15065
epoch: 165 theta: 3.78193 bias:63.37044 loss:2320.09070
epoch: 166 theta: 3.95086 bias:63.52837 loss:4842.80024
epoch: 167 theta: 3.95560 bias:63.68583 loss:4992.92603
epoch: 168 theta: 3.67885 bias:63.83612 loss:1365.99806
epoch: 169 theta: 3.80345 bias:63.98251 loss:2772.09780
epoch: 170 theta: 3.78267 bias:64.12991 loss:2552.85912
epoch: 171 theta: 3.87810 bias:64.28789 loss:3947.92677
epoch: 172 theta: 4.04279 bias:64.43727 loss:7031.82503
epoch: 173 theta: 3.83277 bias:64.58800 loss:3376.28650
epoch: 174 theta: 3.96454 bias:64.73632 loss:5622.00057
epoch: 175 theta: 3.53562 bias:64.87871 loss:530.48478
epoch: 176 theta: 3.78835 bias:65.03154 loss:2909.04114
epoch: 177 theta: 3.83948 bias:65.18074 loss:3688.63421
epoch: 178 theta: 3.71762 bias:65.31990 loss:2121.92164
epoch: 179 theta: 3.76164 bias:65.46542 loss:2697.21378
epoch: 180 theta: 3.60409 bias:65.59671 loss:1092.19979
epoch: 181 theta: 3.58472 bias:65.73373 loss:968.63461
epoch: 182 theta: 3.76338 bias:65.87921 loss:2851.14661
epoch: 183 theta: 3.55705 bias:66.01544 loss:820.14025
epoch: 184 theta: 3.64460 bias:66.14963 loss:1566.15388
epoch: 185 theta: 3.86255 bias:66.28945 loss:4486.60477
epoch: 186 theta: 3.74895 bias:66.42542 loss:2836.26485
epoch: 187 theta: 3.71698 bias:66.56001 loss:2470.33295
epoch: 188 theta: 3.70882 bias:66.69628 loss:2411.06507
epoch: 189 theta: 3.73613 bias:66.83140 loss:2797.63935
epoch: 190 theta: 3.76341 bias:66.95890 loss:3211.15396
epoch: 191 theta: 3.67848 bias:67.08523 loss:2164.41864
epoch: 192 theta: 3.93617 bias:67.20948 loss:6242.05552
epoch: 193 theta: 3.68868 bias:67.33410 loss:2355.23286
epoch: 194 theta: 3.68197 bias:67.45980 loss:2311.71301
epoch: 195 theta: 3.53750 bias:67.58455 loss:948.27658
epoch: 196 theta: 3.55641 bias:67.71188 loss:1118.37975
epoch: 197 theta: 3.66587 bias:67.83365 loss:2229.23296
epoch: 198 theta: 3.39743 bias:67.95052 loss:252.29905
epoch: 199 theta: 3.47645 bias:68.07339 loss:622.51875
epoch: 200 theta: 3.60359 bias:68.19060 loss:1649.10394
epoch: 201 theta: 3.94153 bias:68.30883 loss:6898.90720
epoch: 202 theta: 3.65304 bias:68.40963 loss:2243.28441
epoch: 203 theta: 3.71709 bias:68.52848 loss:3099.43592
epoch: 204 theta: 3.64085 bias:68.63814 loss:2166.36054
epoch: 205 theta: 3.66030 bias:68.75363 loss:2430.57550
epoch: 206 theta: 3.68744 bias:68.86769 loss:2810.70148
epoch: 207 theta: 3.38670 bias:68.97048 loss:297.43143
epoch: 208 theta: 3.57351 bias:69.08652 loss:1567.33301
epoch: 209 theta: 3.60663 bias:69.20009 loss:1936.62607
epoch: 210 theta: 3.67696 bias:69.30848 loss:2814.43457
epoch: 211 theta: 3.64280 bias:69.42228 loss:2416.23774
epoch: 212 theta: 3.66794 bias:69.52927 loss:2766.92085
epoch: 213 theta: 3.27043 bias:69.62543 loss:86.28817
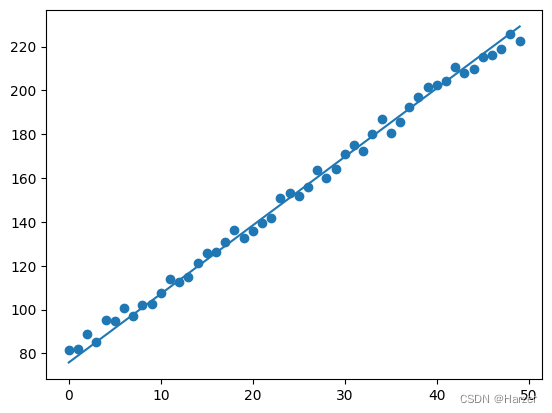
plt.scatter(x, y )
plt.plot(x, theta*x+bias)
plt.show
<function matplotlib.pyplot.show(close=None, block=None)>
plt.plot(loss_list)
plt.show
<function matplotlib.pyplot.show(close=None, block=None)>
批量梯度下降 BGD
a = 0.001
theta =1
bias = 1
loss_list = []
epselon = 100
flag = True
n = 30
epoch = 0
val = data[30:]
train_data = data[:30]
while flag:
theta = theta + a*np.sum((train_data[:,1] - theta*train_data[:,0]-bias)*train_data[:,0])/n
bias = bias + a*np.sum(train_data[:,1] - theta*train_data[:,0]-bias)/n
loss = np.sum(0.5*(val[:,1]-(val[:,0]*theta+bias))**2)
loss_list.append(loss)
print("epoch:%5d theta: %6.5f bias:%6.5f loss:%6.5f"%(epoch,theta, bias, loss) )
epoch = epoch + 1
if loss <= epselon :
flag = False
break
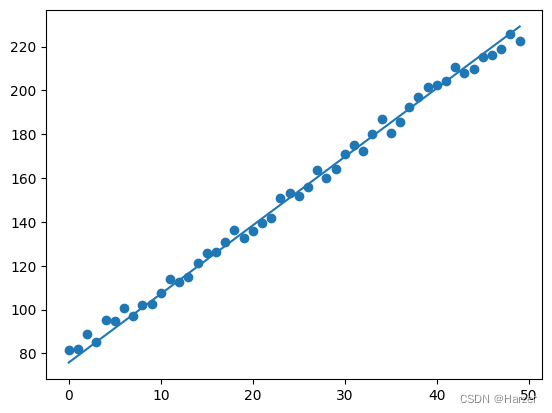
plt.scatter(x, y )
plt.plot(x, theta*x+bias)
plt.show
<function matplotlib.pyplot.show(close=None, block=None)>
plt.plot(loss_list)
plt.show
<function matplotlib.pyplot.show(close=None, block=None)>
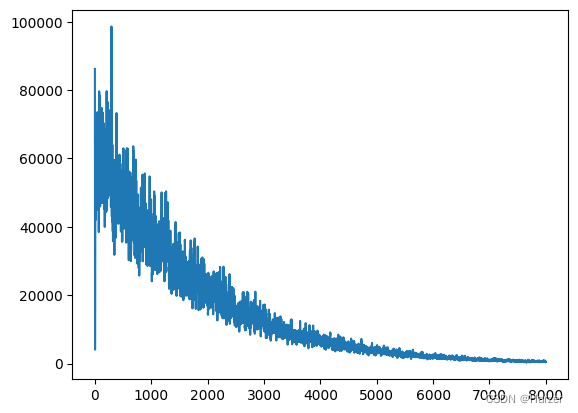
小批量随机梯度下降MBGD
a = 0.001
theta =1
bias = 1
loss_list = []
epselon = 100
flag = True
n = 30
epoch = 0
val = data[30:]
train_data = data[:30]
batch = 10
while flag:
np.random.shuffle(train_data)
xx = train_data[:batch,0]
yy = train_data[:batch,1]
theta = theta + a*np.sum((yy - theta*xx-bias)*xx)/batch
bias = bias + a*np.sum(yy - theta*xx-bias)/batch
loss = np.sum(0.5*(val[:,1]-(val[:,0]*theta+bias))**2)
loss_list.append(loss)
print("epoch:%5d theta: %6.5f bias:%6.5f loss:%6.5f"%(epoch,theta, bias, loss) )
epoch = epoch + 1
if epoch > 8000 or loss < epselon:
flag = False
break
plt.scatter(x, y )
plt.plot(x, theta*x+bias)
plt.show
<function matplotlib.pyplot.show(close=None, block=None)>
plt.plot(loss_list)
plt.show
<function matplotlib.pyplot.show(close=None, block=None)>
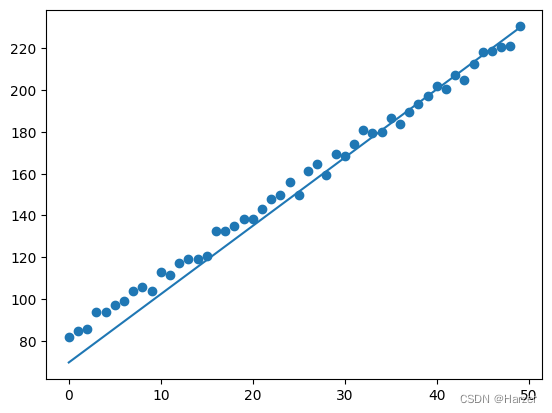
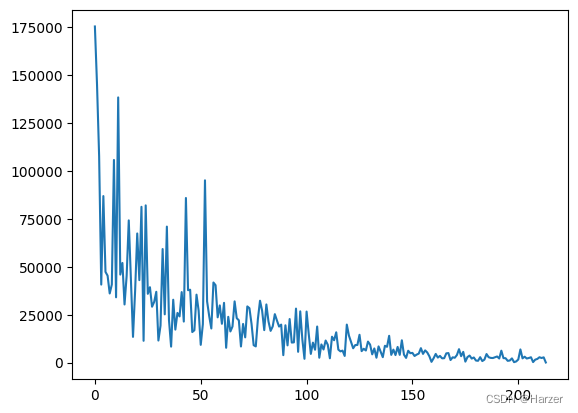
BGD
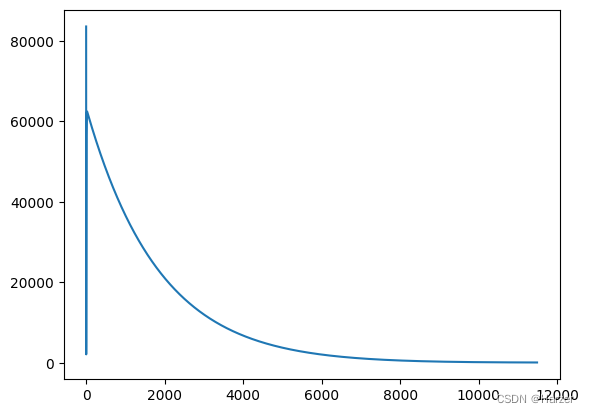
MBGD