Redis 的 HyperLogLog 数据结构实现了一种基于概率的基数估算算法,用于在占用极小内存的情况下估算一个集合中不重复元素(唯一值)的数量。以下是 HyperLogLog 算法的基本原理:
哈希函数:
- HyperLogLog 使用一个强散列函数将输入的元素映射为固定长度的二进制串。
位前导零统计:
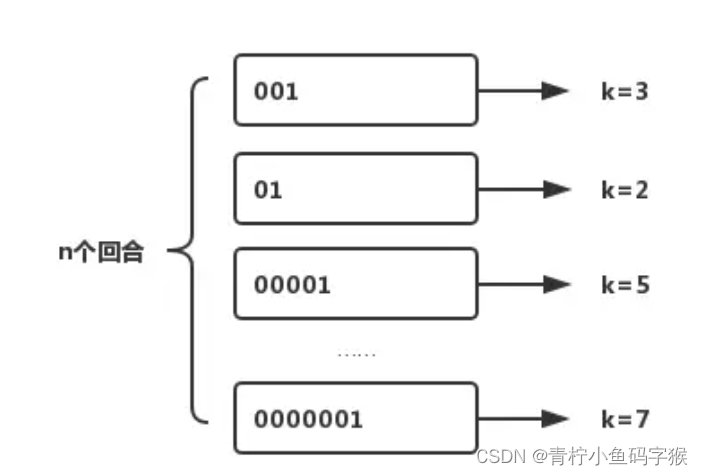
- 对每个元素经过哈希后的二进制串,统计从最高位开始连续零的个数(即前导零个数)。这个值反映了元素哈希值的稀有程度,间接表示了元素的独特性。
存储与计数:
- Redis 中的 HyperLogLog 结构内部维护了一个大小固定的桶数组,默认大小为 2^14 = 16384 个桶。
- 每个桶用于存储对应的元素哈希值所观察到的最大前导零个数。
- 当添加新的元素时,它会被哈希并找到对应的桶来更新该桶中的最大前导零计数值。
基数估算:
- 利用统计的所有桶中最长的前导零序列,通过预定义的公式计算出一个近似的基数(唯一元素数量),这个估算值通常会非常接近实际基数,但不是精确值。
- 标准误差大约是 0.81%,这意味着对于大量数据,HyperLogLog 能够以相对较小的误差估计基数。
空间效率:
- 即使可以处理多达 2^64 (18亿左右)个不同的元素,Redis 中单个 HyperLogLog 键只需要大约 12KB 的固定内存空间。
- 在初始阶段或基数较小的时候,HyperLogLog 使用稀疏存储模式,随着基数增加,当满足一定条件后会转换为稠密存储模式,即上述的固定大小的桶数组。
合并操作:
- HyperLogLog 还支持多个集合的合并操作(
pfmerge命令),允许将多个 HyperLogLog 键合并成一个新的键,同时正确估算所有源键包含的唯一元素总数,这对于分布式环境下的基数统计尤为有用。
- HyperLogLog 还支持多个集合的合并操作(
总之,HyperLogLog 是一种高效的空间优化型算法,适合于在有限资源下进行大规模数据集的去重计数任务。
Redis 的 HyperLogLog 原理可以用一个简单的比喻来通俗易懂地解释:
想象一下你在一个巨大的、无限大的公园里随机扔硬币。每次扔出的硬币落地时,我们只关心它正面朝上还是反面朝上,并且记录下第一次出现正面朝上的次数(比如,扔了5次才见到第一个正面,就记为5)。由于硬币是随机的,这个“第一次正面”的次数与公园中人的数量有一定的关系:人越多,每个区域平均需要扔更多次才能看到正面的概率越大。
HyperLogLog 就像是这样一种神奇的计数器,不过它不是真的扔硬币,而是对输入元素(如用户ID、网页访问等)进行哈希处理,将这些元素映射到一个很大的虚拟空间内,就好比在不同的区域内扔硬币。每个哈希值对应的就是一次“扔硬币”,而观察到的最长连续零位(前导零个数)就代表了需要多少次“扔”才能见到“正面”。
在 Redis 中,HyperLogLog 用一个固定大小的桶数组(默认大小为2^14个桶)来存储各个桶对应的最长前导零个数。通过统计所有桶中的最大前导零计数值,并结合一个数学公式,就可以估算出不重复元素的大致数量,尽管实际上并没有存储每个具体的唯一元素。
所以,虽然 HyperLogLog 不会记住每一个独特的元素,但它能用极小的空间开销(仅需约12KB),相对准确地估计高达2^64个不同元素的数量。当然,这是一种概率算法,因此结果存在一定的误差,但其标准误差率相当低,在0.81%左右。
HyperLogLog 在实际开发中主要用于需要统计大量唯一值数量但又对内存占用敏感的场景,它可以提供一个非常接近真实基数的估算值,同时占用极小的存储空间。以下是一些具体的应用场景:
- 网站独立访客(UV)统计:
- 通过记录用户访问时的标识符(如 IP 地址、Cookie 或用户ID),使用 HyperLogLog 进行去重计数,可以快速估算一天内或一段时间内的独立访客数量。
使用 Redis Hyperloglog 进行 UV 统计,我们主要会使用到以下三个命令:
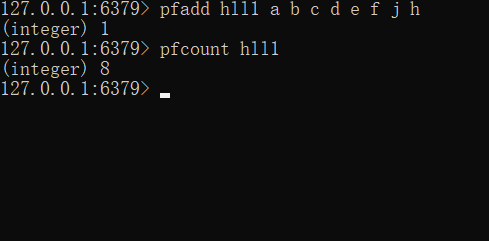
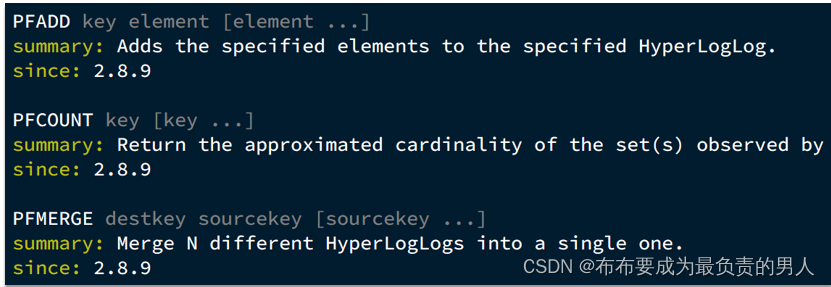
● PFADD key values : 用于数据添加,可以一次性添加多个。添加过程中,重复的记录会自动去重。
● PFCOUNT key : 对 key 进行统计。
● PFMERGE destkey sourcekey1 sourcekey2 : 合并多个统计结果,在合并的过程中,会自动去重多个集合中重复的元素。
广告点击独立用户统计:
- 在在线广告系统中,为了评估广告效果,需要统计每个广告被多少不同的用户点击过。HyperLogLog 可以用来估算每条广告的独立点击用户数。
社交网络分析:
- 社交网络中的粉丝数、关注数等指标可以通过 HyperLogLog 来进行估算,尤其是在大数据量下不需要知道具体的粉丝列表,只需估计大致的数量。
实时事件流处理:
- 对于日志收集和分析平台,HyperLogLog 可用于实时统计每天或每小时发生的不同类型的事件数量,例如异常请求次数、不同设备型号的活跃用户数等。
数据库索引优化:
- 在数据导入预处理阶段,可利用 HyperLogLog 预估某个字段的唯一值数量,以便更准确地选择合适的索引策略。
分布式环境下的去重计算:
- 在分布式系统中,数据可能分布在多个节点上。每个节点本地维护一个 HyperLogLog 结构,然后通过
pfmerge命令将各个节点的 HyperLogLog 合并,最终得到全系统的唯一值数量。
- 在分布式系统中,数据可能分布在多个节点上。每个节点本地维护一个 HyperLogLog 结构,然后通过
总之,只要涉及到在海量数据下高效估算唯一元素数量的需求,都可能是 HyperLogLog 大显身手的地方。