对比学习公式讲述
对比学习倾向于将同一图像的转换视图之间的一致性最大化,而将不同图像的转换视图之间的一致性最小化。令是一个输出特征空间
的卷积神经网络。一个图像x的两个增广图像补丁通过
进行映射,生成一个查询特征q和一个关键特征k。此外,使用其他图像的补丁生成一个包含数千个负特征
的队列。
该队列既可以使用当前批处理中的所有图像在线生成[1],也可以使用最近几个epoch的存储特征离线生成[4]。给定q,对比学习的目标是识别数千个特征中的k,可以表示为:
式中为温度参数,
相似性度量。在Exemplar[5]中,为了“在弱利用标签信息的同时保留每个正实例的唯一信息”,将
中与属于同一类
的所有样本都剔除。
什么是对比学习(无监督任务)
对比学习往往解决第一件事:在原始任务如何把特征提取的更好,encoder编码器,我们该如何设计。
有了标签,模型就会安装这个标签(一遍是人给的)为上限进行学习,但如果没有标签了,就相当于不设定上限了(但是有监督任务效果确实往往比无监督好,无简单经常出现不收敛的情况)
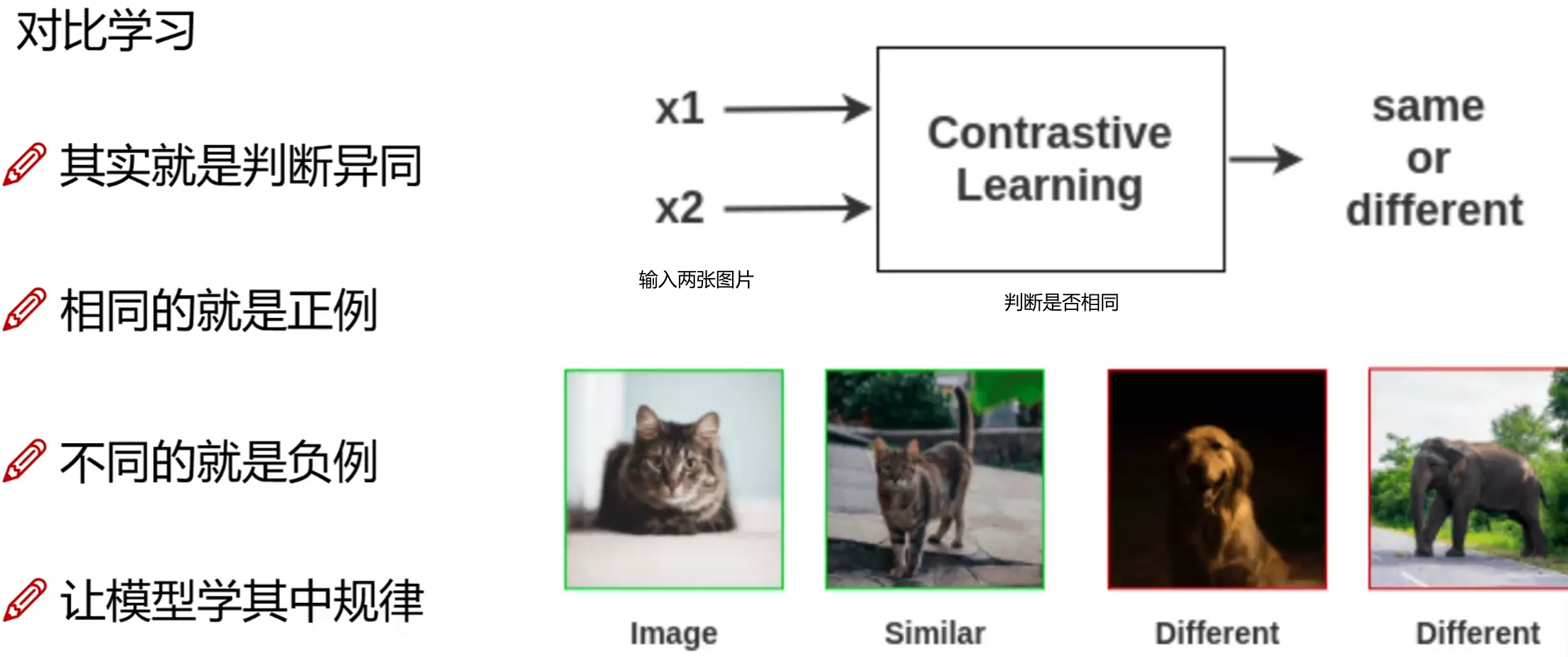
如何标注标签

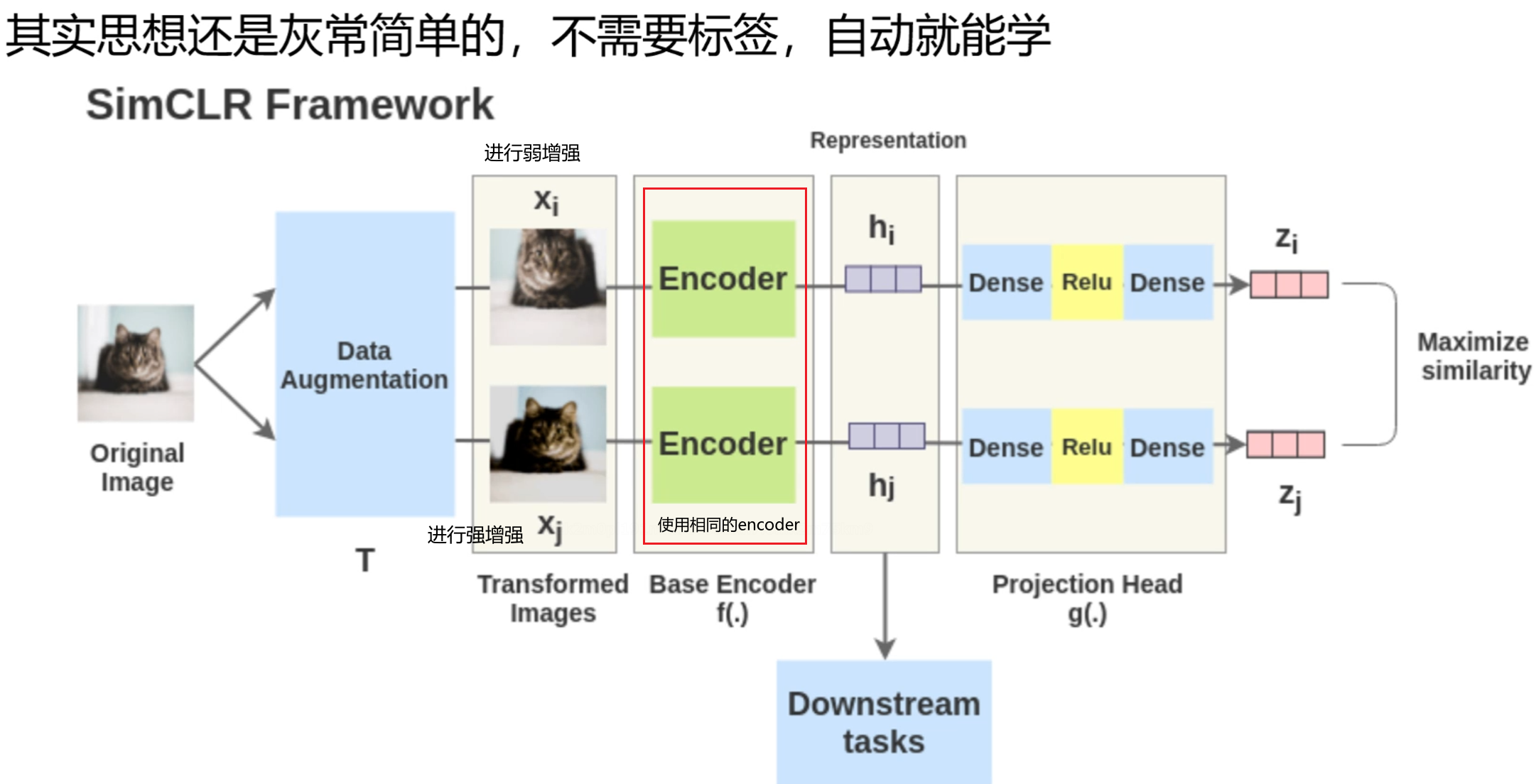
SimCLR Framework
数据增强得越大(me:原始数据被干扰得越厉害),模型,即encoder的泛化能力越强(me:能够面对各种被损坏的数据也能识别出哪种类别)


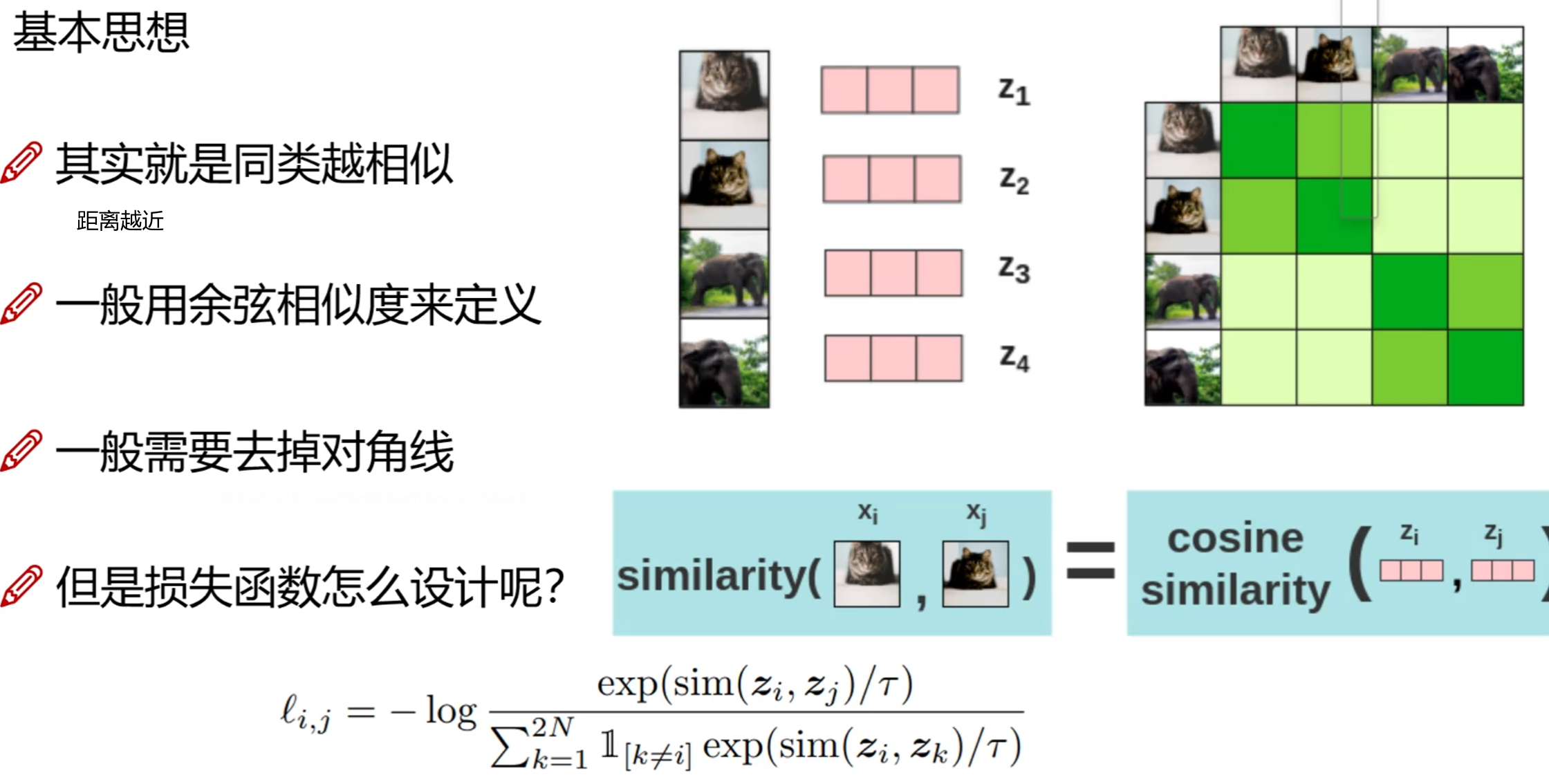


下面的直方图的y轴指准确率

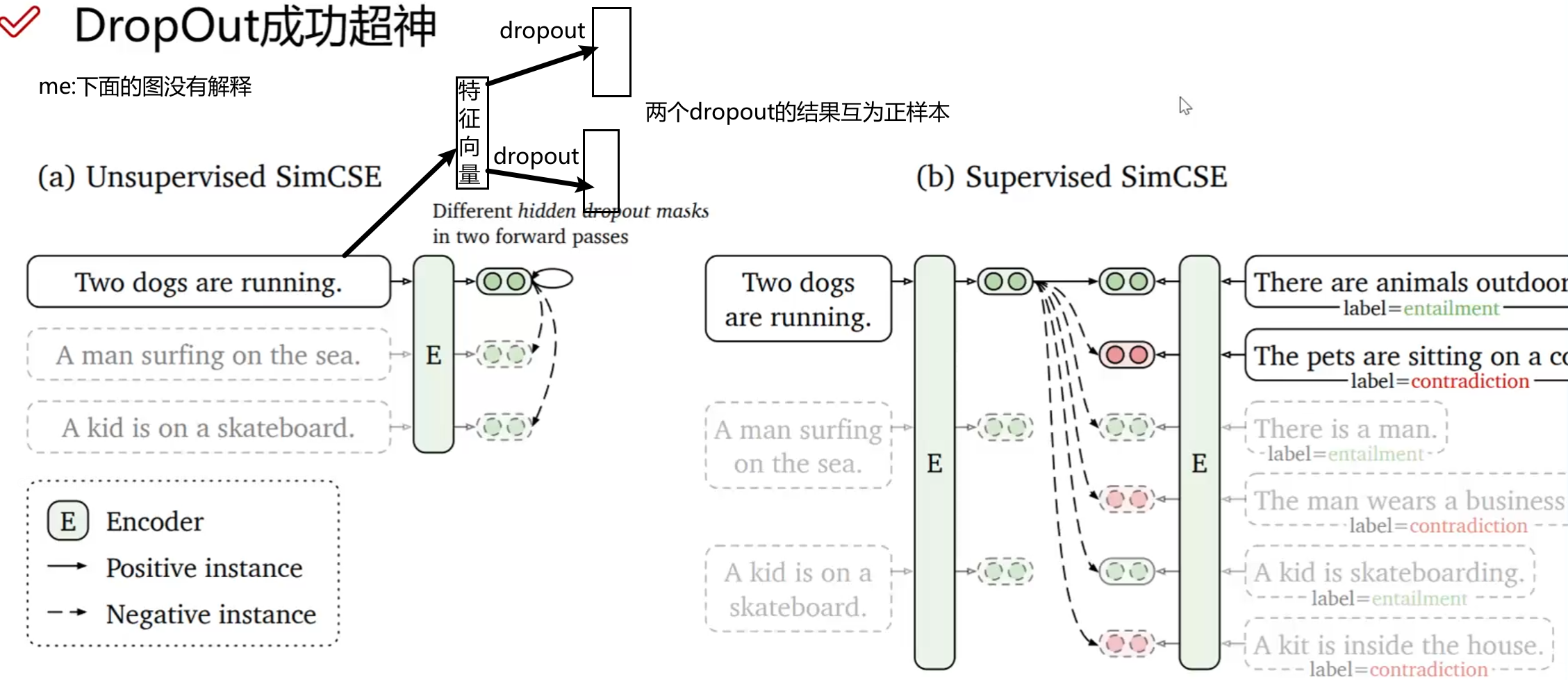
SimCSE Framework

对比学习的关键就是如何选择正样本