前言
大部分概念都会给出解释,如果你有不懂的概念,请你在评论中写出
训练集(Training Set)
用于模型拟合的数据样本。这部分数据集主要用于训练模型,使模型通过学习数据的特征来产生一个可以用于预测的模型。在训练过程中,模型会不断调整其参数,以最小化在训练集上的预测误差。
验证集(Validation Set)
用于评估模型性能的数据集。这部分数据集是在训练过程中从原始数据集中划分出来的,用于调整模型的参数和超参数,并对模型的能力进行初步评估。通过验证集,开发者可以了解模型在训练过程中的表现,从而判断是否需要继续训练、调整参数或采用其他优化策略。验证集的作用是帮助避免模型过拟合或欠拟合,确保模型在未见过的数据上也能保持较好的性能。
测试集(Test Set)
用于评估模型最终性能的数据集。测试集通常也是在训练过程中从原始数据集中划分出来的,与训练集和验证集互不重叠。它的作用是评估模型在全新的、未见过的数据上的性能,以判断模型是否足够准确和鲁棒。在实际应用中,测试集通常用于比较不同模型的优劣度,例如在机器学习竞赛中,测试集用于决定哪个模型在未知数据上的表现更好。
经验误差
经验误差(Empirical Error)通常指的是学习器在训练集上的误差,也称为训练误差。具体来说,它表示的是学习器对训练样本的预测输出与真实输出之间的差异。这种差异可以通过比较预测值和实际值来计算,通常表现为一种损失函数的度量。
经验误差是机器学习算法在训练过程中的一个关键指标,它用于评估算法在拟合训练数据上的性能。通过优化算法以减小经验误差,我们可以使模型更好地适应训练数据。然而,仅仅关注经验误差是不够的,因为过度拟合训练数据可能导致模型在新数据上的性能下降,即泛化能力降低。
为了评估模型的泛化能力,我们通常还需要考虑其他指标,如泛化误差。泛化误差是指模型在新样本(即测试集上的样本)上的误差,它代表了模型在未知数据上的性能。理想情况下,我们希望找到一个平衡点,使得经验误差和泛化误差都尽可能小。
在实际应用中,为了避免过拟合,我们通常会采取一些策略,如正则化、交叉验证、早停法等。这些策略有助于在训练过程中控制经验误差,同时保持模型的泛化能力。
拟合度
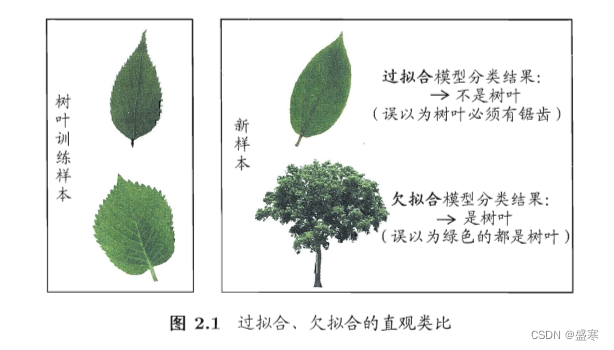
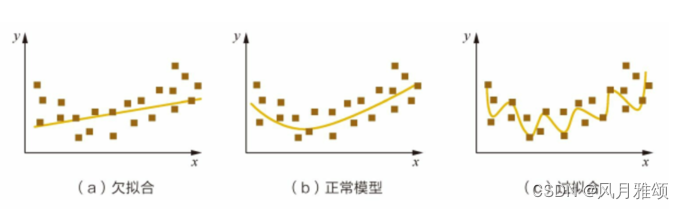
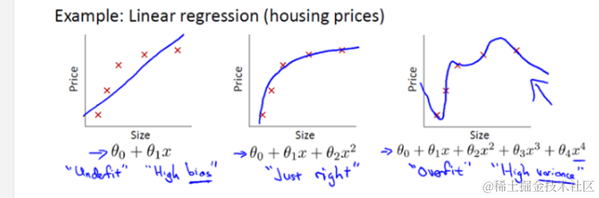
过拟合
过拟合(Overfitting)是机器学习中一个关键的问题,它发生在模型在训练数据上表现得过于出色,但在测试数据或新数据上性能较差时。简而言之,过拟合就是模型对训练数据的复杂性进行了过度拟合,而失去了对新数据的泛化能力。
过拟合原因
训练数据不足
当训练集的数量级与模型的复杂度不匹配时,模型可能过度拟合训练数据中的噪声和细节,导致在新数据上表现不佳。
训练数据噪声过大
当训练数据中包含大量的噪声或错误标签时,模型可能会错误地将这些噪声特征作为重要信息来学习,导致过拟合。
模型复杂度过高
如果模型过于复杂,它可能会尝试拟合训练数据中的每一个细节,包括那些与真实关系无关的细节。这会导致模型在训练数据上表现良好,但在新数据上表现较差。
为了避免过拟合,可以采取以下策略:
增加训练数据量
更多的训练数据可以帮助模型学习到更通用的特征,减少过拟合的风险。
简化模型
选择更简单、更易于泛化的模型可以减少过拟合。
使用正则化技术(以后再说)
如L1正则化、L2正则化等,通过在损失函数中加入与模型复杂度相关的项,来惩罚复杂的模型,防止过拟合。
L1正则化和L2正则化是机器学习中用于防止模型过拟合的两种技术,它们通过修改损失函数来实现这一目标。
采用交叉验证
通过将数据集分为训练集、验证集和测试集,可以在训练过程中监控模型在验证集上的性能,以便及时发现并防止过拟合。
欠拟合
欠拟合(Underfitting)是指机器学习模型无法完全拟合数据集中的复杂模式,导致模型表现较差的现象。这通常意味着模型在训练集、验证集和测试集上的表现都不佳。具体来说,欠拟合可以理解为模型容量不足,无法准确预测数据集中的细节和复杂关系。在训练期间,模型可能只能捕获数据的一小部分模式,而未能充分利用数据的许多特征。
欠拟合原因
模型过于简单或不够复杂,以至于无法捕获数据中的复杂模式。
数据集太小或噪音过多,导致模型无法从中学习到足够的规律。
特征提取不正确或特征太少,使得模型在训练时无法充分利用数据的特征。
解决欠拟合问题
增加模型的复杂度,例如增加层数或参数数量,以使模型能够捕获更多的数据模式。
增加数据量或减少噪音,使模型能够从更多的数据中学习到规律。
提高特征选择的准确性,确保模型在训练时能够充分利用数据的特征。
评估方法
评估方法主要涉及到如何有效地衡量模型在新数据上的性能。这些评估方法对于选择合适的模型、调整模型参数以及比较不同模型之间的优劣至关重要。
常见的机器学习评估方法
留出法(Hold-out Method)
它通过将数据集D划分为两个互斥的集合,即训练集S和测试集T(D = S ∪ T,S ∩ T = ∅),来进行模型的训练和评估。训练集用于训练模型,而测试集则用于评估模型的性能。一般训练集与测试集的比例为2:1 ~ 4:1,即2/3 ~ 4/5 用于训练,其他用来测试。
交叉验证法(Cross-validation)
将数据集划分为k个大小相似的互斥子集。
每次选择k-1个子集作为训练集,剩余的一个子集作为测试集。这样进行k次训练和测试,每次使用不同的子集作为测试集。
将k次测试的结果取平均值作为最终的评估结果。
又称k折交叉验证(k-fold cross-validation),k一般取值为10,称为10折交叉验证。
特殊情况:
留一法(Leave-one-out cross-validation)
在这种方法中,我们将数据集中的每一个样本都作为一次测试集,而其他所有的样本则作为训练集。因此,如果数据集中有n个样本,那么这种方法将会进行n次训练和验证。就是折交叉验证。
留一法的核心思想在于,通过让每一个样本都有机会作为测试集,从而最大限度地利用数据集,并对模型的性能进行尽可能准确的评估。这种方法尤其适用于数据集较小的情况,因为它可以给出模型性能的一个非常接近真实值的估计。
然而,留一法的缺点也很明显,那就是计算成本较高。由于每个样本都需要单独作为一次测试集,因此需要训练的模型数量就等于样本数量。对于大数据集,这可能会导致计算时间和资源的显著增加。
自助法(Bootstrapping)
自助法(Bootstrapping)是一种再抽样的统计方法,其基本思想是从现有的样本中有放回地随机抽取数据点,从而创造出多组模拟的样本。这种方法可以用来估计一个统计量的抽样分布,以及计算诸如标准误差、置信区间等统计量。
自助法的主要步骤如下:
从原始数据集中有放回地随机抽取一定数量的样本,形成新的数据集。
基于这个新数据集进行统计分析,例如计算某个统计量的值。
重复上述步骤多次(通常是几千次或更多),得到该统计量的多个估计值。
根据这些估计值,可以计算出该统计量的标准误差、置信区间等。
自助法的优点在于它不需要对总体分布做任何假设,只需要利用现有的样本数据即可。因此,它在处理复杂分布或难以用传统方法进行分析的问题时特别有用。
由于它是有放回的抽样,所以可能会导致某些样本在多次抽样中被重复选中,而另一些样本则从未被选中(因此自助采样又称可重复采样,有放回采样)。这可能会引入一些偏差,尤其是在样本量较小的情况下。此外,自助法的计算成本通常较高,因为它需要进行大量的重复抽样和统计分析。