概要
ConcurrentHashMap是懒加载,并不会在创建对象的时候进行初始化,只有第一次添加数据的时候才会进行初始化。
线程进来首先会判断当前对象是否为空,判断是否需要进行初始化。
使用了大量的CAS操作来进行并发控制,这种操作在多线程环境下能够有效地实现原子性更新。CAS 的引入使得在进行插入、更新和删除操作时,减少了锁的使用,提高了性能。
当链表长度超过一定阈值时,会将链表转换为红黑树,以提高查找和删除操作的性能。
提供了线程安全的 putIfAbsent() 方法,它可以在键不存在时插入一个键值对。这个方法的原子性操作可以在多线程环境中避免重复插入。
自动扩容:ConcurrentHashMap 会根据负载因子(load factor)来自动扩容,以保证数据的均衡分布和高效的查找性能。
CAS 操作:ConcurrentHashMap 使用了 CAS(Compare-And-Swap)等原子性操作来保证线程安全性。这些操作能够在不加锁的情况下进行数据的更新。
高并发环境优化:ConcurrentHashMap 在高并发环境下表现优秀,特别适合读多写少的情况,可以显著减少锁竞争,提高性能。
适用场景:ConcurrentHashMap 适用于需要在多线程环境下进行并发访问的场景,如并发缓存、并行计算等。
功能丰富的 API:ConcurrentHashMap 提供了丰富的 API,包括线程安全的插入、删除、查找操作,以及诸如 forEach、reduce 等方法,支持各种并发操作需求。
数据结构
JDK版本对比
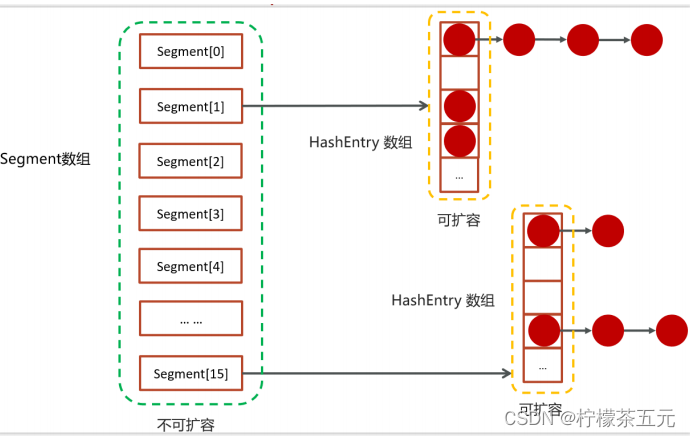
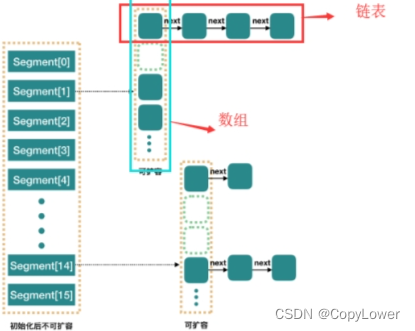
JDK1.7中的底层数据结构。
底层一个Segments数组;数组(Segment)+ 链表
JDK1.8中数据结构
Node数组+链表 / 红黑树, 类似HashMap
Node数组使用来存放树或者链表的头结点,当一个链表中的数量到达一个数目时,会使查询速率降低,所以到达一定阈值时,会将一个链表转换为一个红黑二叉树,提高查询的速率。
ConcurrentHashMap相比HashMap而言,是多线程安全的,其底层数据与HashMap的数据结构相同。
类的构造函数
public ConcurrentHashMap() {
}说明:该构造函数用于创建一个带有默认初始容量 (16)、加载因子 (0.75) 和 concurrencyLevel (16) 的新的空映射。
扩容机制
触发扩容的有三种场景
第一:在链表转红黑树的时候进行判断,如果此时没有达到阈值,则不会转成红黑树,会对数组进行扩容。
第二:进行putAll()方法的时候,可能会触发扩容机制,因为putAll传入的参数是map对象,如果这个map的数据比较多,就会进行扩容操作。
第三:添加元素的时候,如果达到阈值,会进行扩容机制。
技术名词解释
我们对以下技术名词解释
名词举例:
- CAS
CAS是Compare-and-Swap的缩写,也叫比较交换。它是一种原子性操作,用于多线程编程中同步访问共享资源的问题。CAS操作需要同时传递一个期望值和一个新值,它会比较当前共享资源的值是否等于期望值,如果相等则把共享资源的值设置为新值,否则不做任何修改,并返回当前的共享资源的值。
- 红黑树
红黑树是一种自平衡二叉查找树,是一种数据结构,典型的用途是实现关联数组。这种结构确保了红黑树在任何时候都是接近平衡的,从而在最坏情况下,其查找、插入和删除操作的时间复杂度都是O(log n)。红黑树通过一系列的规则和操作(如颜色更改和节点旋转)来维护这些性质,从而保持树的平衡。
小结
1、在 JDK1.7 中,ConcurrentHashMap 采用了分段锁策略,将一个 HashMap 切割成 Segment 数组,其中 Segment 可以看成一个 HashMap, 不同点是 Segment 继承自 ReentrantLock,在操作的时候给 Segment 赋予了一个对象锁,从而保证多线程环境下并发操作安全。
ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。
第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
2、在JDK1.8中,取消了segment数组,锁的粒度更小,减少并发冲突的概率。原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。JDK1.8中的 ConcurrentHashMap 与 HashMap 非常相似,只是 ConcurrentHashMap 中增加了同步的操作和 CAS 来实现并发操作。采用了synchronized+CAS+数组+链表+红黑树的实现方式来设计。
3、JDK1.8存储数据时采用了链表+红黑树的形式,纯链表的形式时间复杂度为O(n),红黑树则为O(logn),性能提升很大。什么时候链表转红黑树?当key值相等的元素形成的链表中元素个数超过8个的时候。
4、JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了。
5、JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个性能的极大提升。
6、JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock?
(1)锁的粒度
首先锁的粒度并没有变粗,甚至变得更细了。每当扩容一次,ConcurrentHashMap的并发度就扩大一倍。
(2)Hash冲突
JDK1.7中,ConcurrentHashMap从过二次hash的方式(Segment -> HashEntry)能够快速的找到查找的元素。在1.8中通过链表加红黑树的形式弥补了put、get时的性能差距。
JDK1.8中,在ConcurrentHashmap进行扩容时,其他线程可以通过检测数组中的节点决定是否对这条链表(红黑树)进行扩容,减小了扩容的粒度,提高了扩容的效率。
从以上两个角度分析,得以说明原因:
(1)减少内存开销
假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承AQS来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费。
(2)获得JVM的支持
可重入锁毕竟是API这个级别的,后续的性能优化空间很小。
synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。这就使得synchronized能够随着JDK版本的升级而不改动代码的前提下获得性能上的提升。
7、JDK8中的实现也是锁分离思想,只是锁住的是一个node,而不是JDK7中的Segment;锁住Node之前的操作是基于在volatile和CAS之上无锁并且线程安全的。