🌈欢迎来到C++项目专栏
🙋🏾♀️作者介绍:前PLA队员 目前是一名普通本科大三的软件工程专业学生
🌏IP坐标:湖北武汉
🍉 目前技术栈:C/C++、Linux系统编程、计算机网络、数据结构、Mysql、Python
🍇 博客介绍:通过分享学习过程,加深知识点的掌握,也希望通过平台能认识更多同僚,如果觉得文章有帮助,请您动动发财手点点赞,本人水平有限,有不足之处欢迎大家扶正~
🍓 最后送大家一句话共勉:知不足而奋进,望远山而前行。
————————————————
1.项目介绍
对比常用搜索引擎,实现一个简易版的站内搜索引擎。
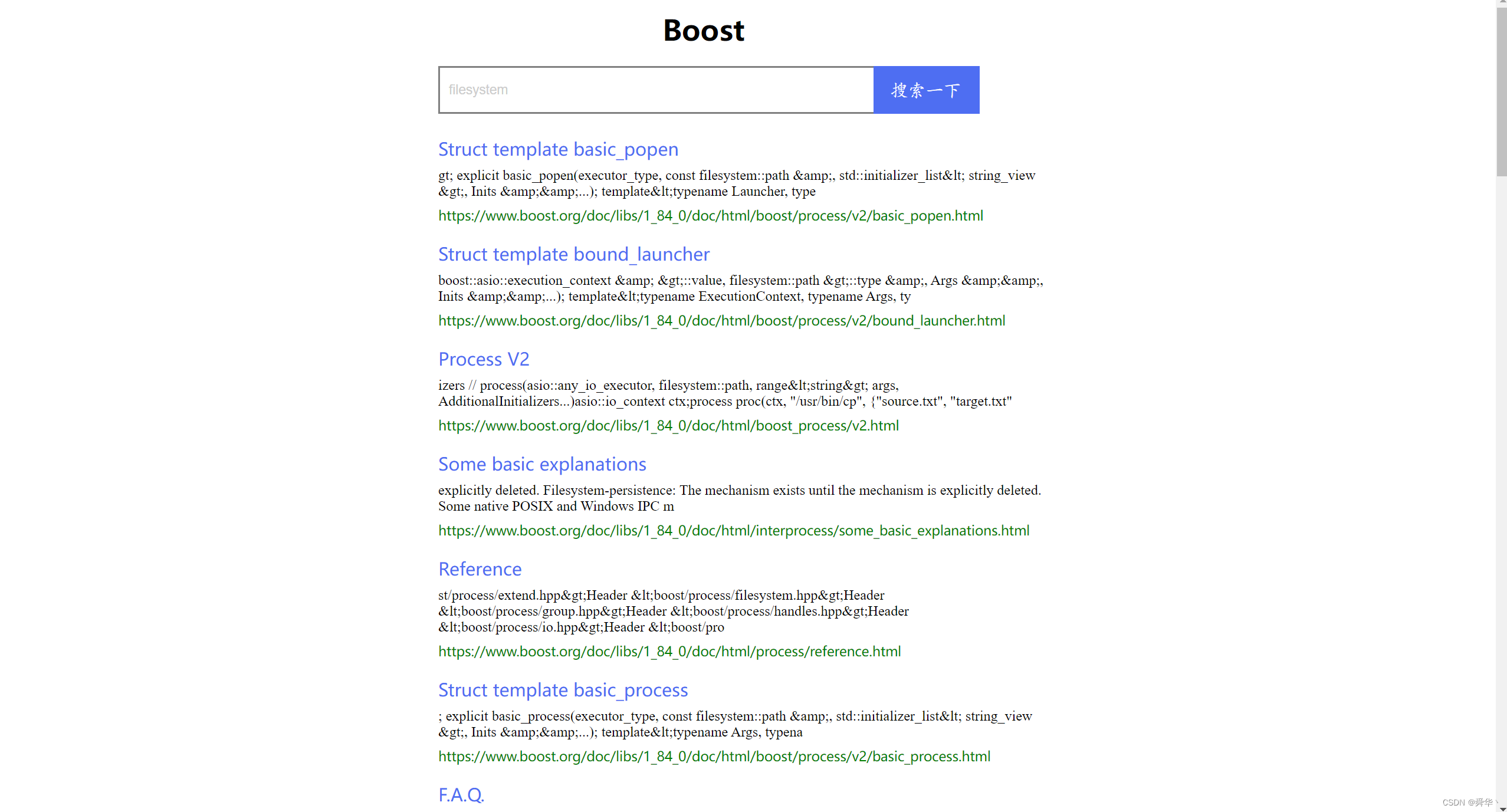
基于boost库实现,boost库官网上是没有站内搜索引擎的,我们自己实现一个,部署在自己的云服务,客户端可以通过浏览器访问服务器地址,实现搜索引擎功能的使用。
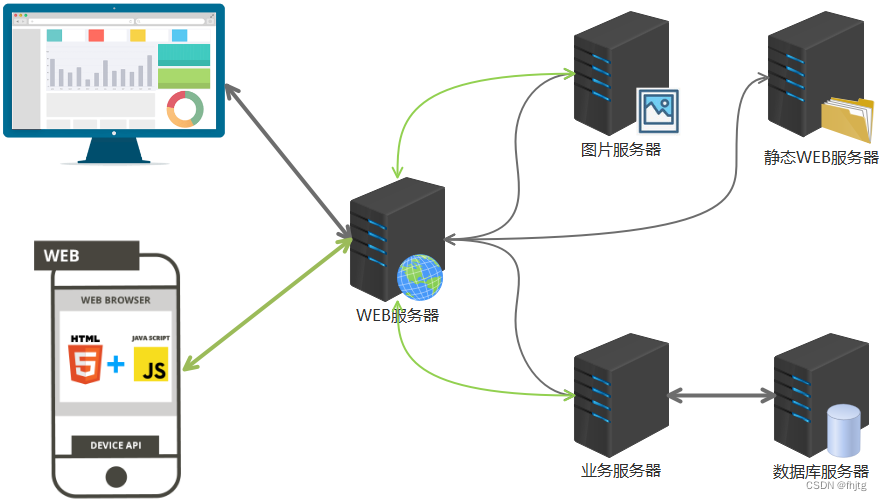
2.搜索引擎宏观介绍
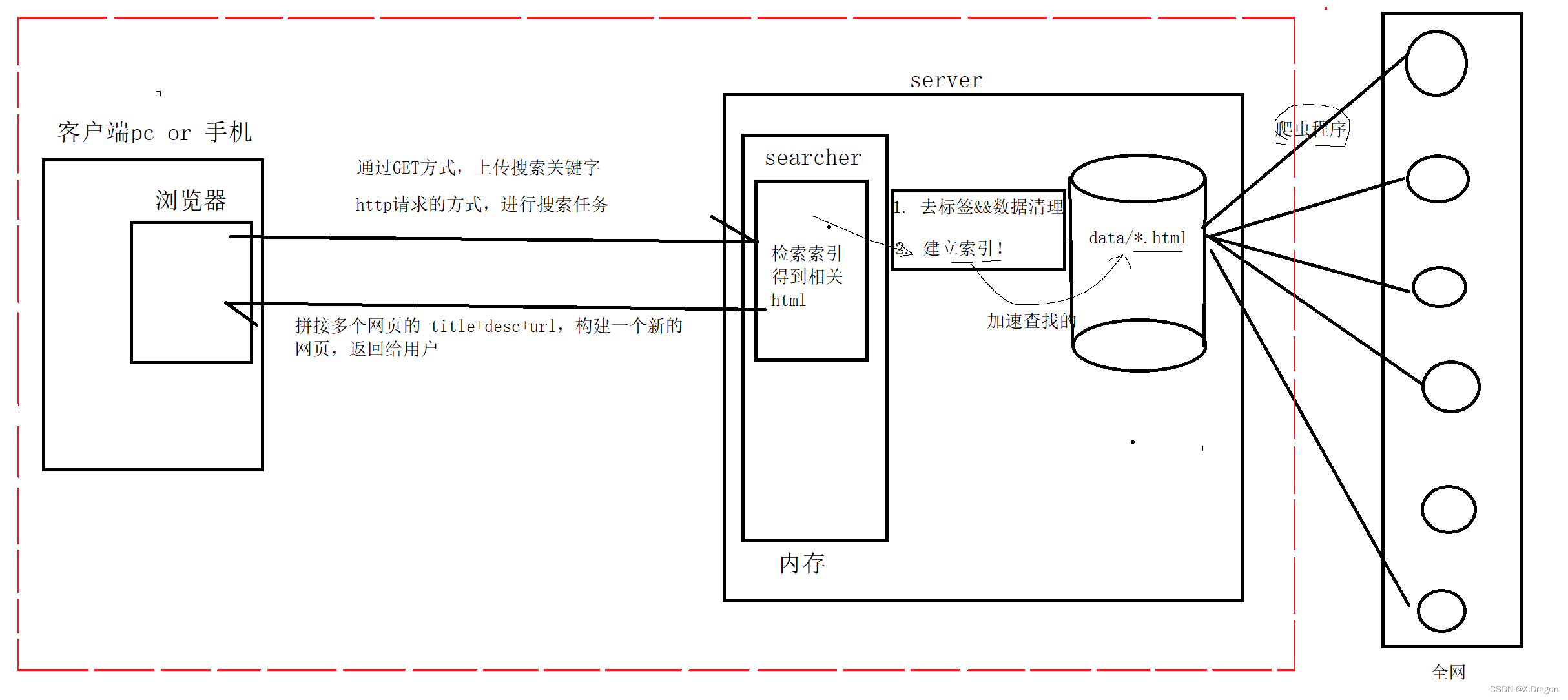
常用搜索引擎,如百度 搜狗等,搜索引擎框架可简易理解如上图,我们实现的站内搜索引擎对比就是把相关资料提前下载到云服务器本地,当用户使用搜索功能时,在服务器本地进行检索反馈。
3.相关技术栈和项目环境
- 技术栈: C/C++ C++11, STL, 准标准库Boost,Jsoncpp,cppjieba,cpp-httplib , 选学: html5,css,js、Query、Ajax
- 项目环境: Centos 7云服务器,vim/gcc(g++)/Makefile , vs2019 or vs code
4.正排索引VS倒排索引-搜索引擎具体原理
5.编写数据去标签与数据清洗的模块
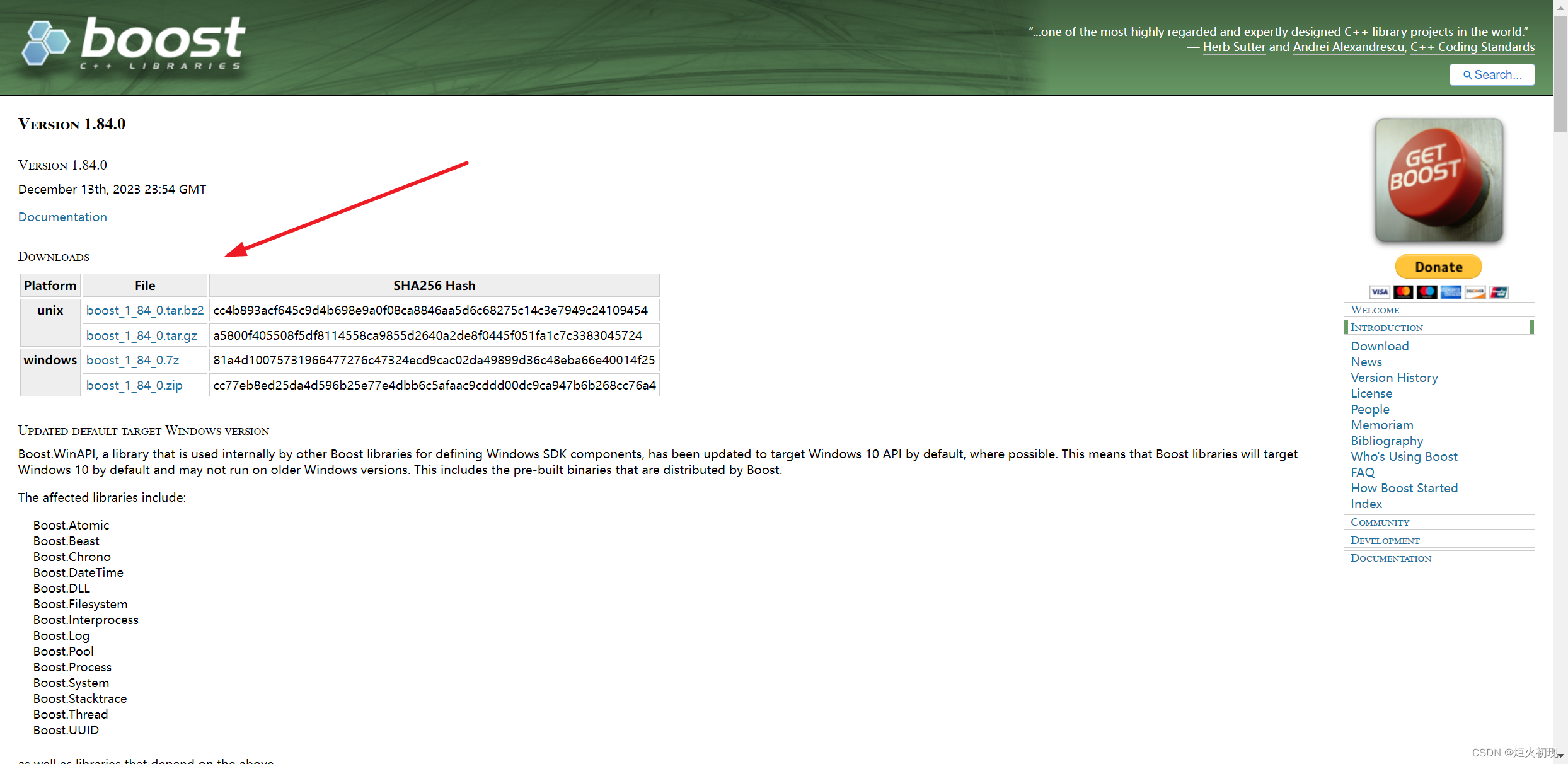
先去boost官网将文件下载下来,使用rz命令将文件拖拽到Linux服务器
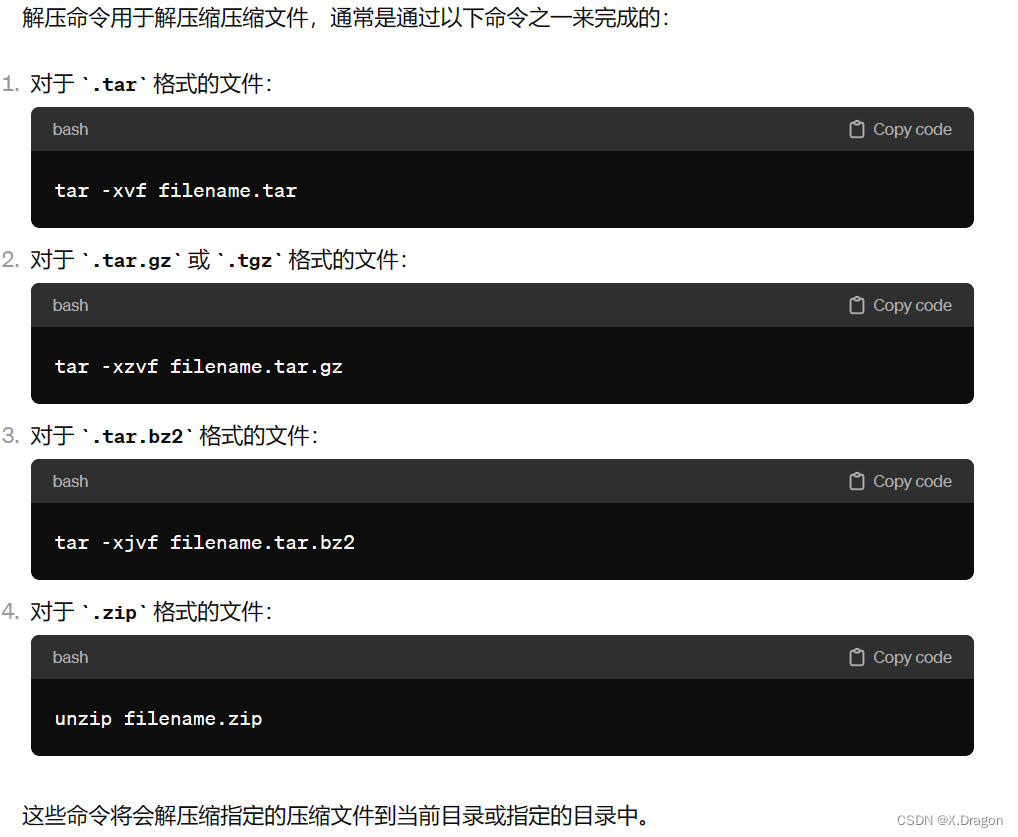
解压命令:
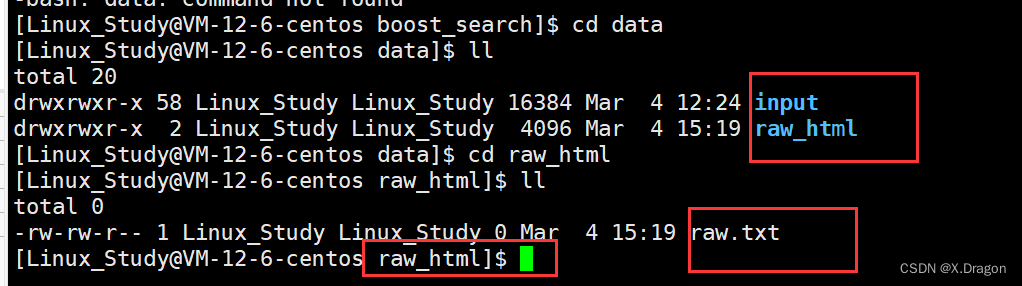
创建好数据文件夹用来区分处理好的数据,方便后期读取使用
- 编写parser.cc模块
//代码的基本结构:
#include <iostream>
#include <string>
#include <vector>
//是一个目录,下面放的是所有的html网页
const std::string src_path = "data/input/";
const std::string output = "data/raw_html/raw.txt";
typedef struct DocInfo{
std::string title; //文档的标题
std::string content; //文档内容
std::string url; //该文档在官网中的url
}DocInfo_t;
//const &: 输入
//*: 输出
//&:输入输出
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list);
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t>
*results);
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);
int main()
{
std::vector<std::string> files_list;
//第一步: 递归式的把每个html文件名带路径,保存到files_list中,方便后期进行一个一个的文件进行读取
if(!EnumFile(src_path, &files_list)){
std::cerr << "enum file name error!" << std::endl;
return 1;
}
//第二步: 按照files_list读取每个文件的内容,并进行解析
std::vector<DocInfo_t> results;
if(!ParseHtml(files_list, &results)){
std::cerr << "parse html error" << std::endl;
return 2;
}
//第三步: 把解析完毕的各个文件内容,写入到output,按照\3作为每个文档的分割符
if(!SaveHtml(results, output)){
std::cerr << "sava html error" << std::endl;
return 3;
}
return 0;
}
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{
return true;
}
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results)
{
return true;
}
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
return true;
}
- 安装boost开发库
$ sudo yum install -y boost-devel //是boost 开发库