参考文档:https://github.com/InternLM/tutorial/blob/main/lmdeploy/lmdeploy.md
基础作业:
使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)
2.1 模型转换
(1)在线转换
直接启动本地的 Huggingface 模型
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b

(2)离线转换
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式
# 转换模型(FastTransformer格式) TurboMind
# lmdeploy convert internlm-chat-7b /path/to/internlm-chat-7b
# 用户根目录执行
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/
执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。
目录如下图所示。

Tensor并行一般分为行并行或列并行,原理如下图所示。
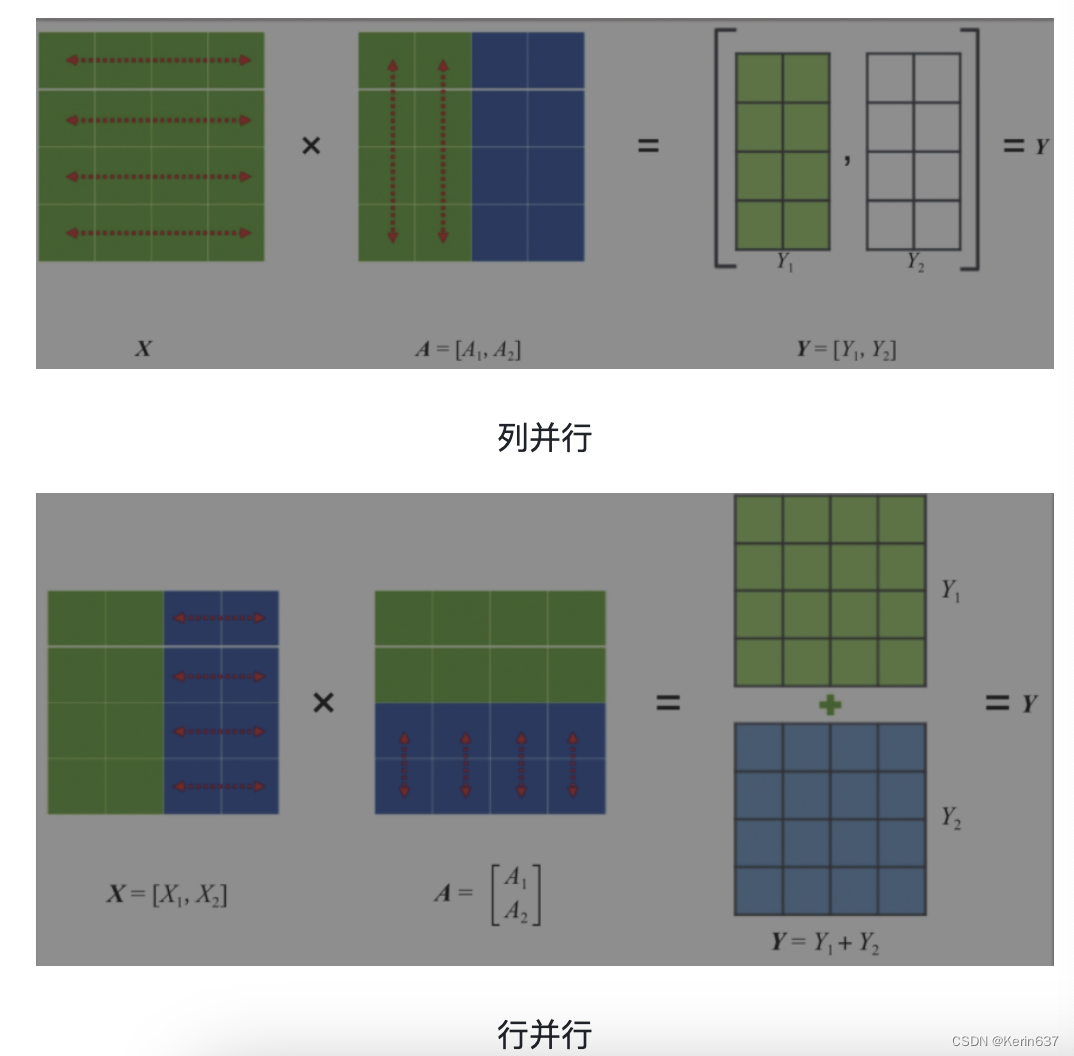
简单来说,就是把一个大的张量(参数)分到多张卡上,分别计算各部分的结果,然后再同步汇总。
2.2 TurboMind 推理+命令行本地对话
我们先尝试本地对话(Bash Local Chat),下面用(Local Chat 表示)在这里其实是跳过 API Server 直接调用 TurboMind。简单来说,就是命令行代码直接执行 TurboMind。
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace

输入后两次回车,退出时输入exit 回车两次即可。此时,Server 就是本地跑起来的模型(TurboMind),命令行可以看作是前端。
2.3 TurboMind推理+API服务
”模型推理/服务“目前提供了 Turbomind 和 TritonServer 两种服务化方式。此时,Server 是 TurboMind 或 TritonServer,API Server 可以提供对外的 API 服务。我们推荐使用 TurboMind,TritonServer 使用方式详见《附录1》。
首先,通过下面命令启动服务。
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
上面的参数中 server_name 和 server_port 分别表示服务地址和端口,tp 参数我们之前已经提到过了,表示 Tensor 并行。还剩下一个 instance_num 参数,表示实例数,可以理解成 Batch 的大小。执行后如下图所示。

然后,我们可以新开一个窗口,执行下面的 Client 命令。如果使用官方机器,可以打开 vscode 的 Terminal,执行下面的命令。
# ChatApiClient+ApiServer(注意是http协议,需要加http)
lmdeploy serve api_client http://localhost:23333

当然,刚刚我们启动的是 API Server,自然也有相应的接口。可以直接打开 http://{host}:23333 查看,如下图所示。


这里一共提供了 4 个 HTTP 的接口,任何语言都可以对其进行调用,我们以 v1/chat/completions 接口为例,简单试一下。
curl -X 'POST' \
> 'http://localhost:23333/v1/chat/completions' \
> -H 'accept:application/json' \
> -H 'Content-Type: application/json' \
> -d '{
"model": "internlm-chat-7b",
"messages": "写一首春天的诗",
"temperature": 0.7,
"top_p": 1,
"n": 1,
"max_tokens": 512,
"stop": false,
"stream": false,
"presence_penalty": 0,
"frequency_penalty": 0,
"user": "string",
"repetition_penalty": 1,
"renew_session": false,
"ignore_eos": false
}'
{
"id":"1825","object":"chat.completion","created":1708224888,"model":"internlm-chat-7b","choices":[{
"index":0,"message":{
"role":"assistant","content":"\n写一首春天的诗\n春天来了,大地复苏,\n花儿绽放,鸟儿歌唱。\n春风拂面,温暖宜人,\n人们欢庆,心情舒畅。\n\n春天来了,冰雪融化,\n河水潺潺,鱼儿游荡。\n草木葱茏,绿意盎然,\n大自然,生机勃勃。\n\n春天来了,万物复苏,\n生命力,无限强大。\n让我们珍惜,这美好的时光,\n共同创造,更美好的未来。"},"finish_reason":"stop"}],"usage":{
"prompt_tokens":5,"total_tokens":106,"completion_tokens":101}}%
2.4 网页 Demo 演示
这一部分主要是将 Gradio 作为前端 Demo 演示。在上一节的基础上,我们不执行后面的 api_client 或 triton_client,而是执行 gradio.由于 Gradio 需要本地访问展示界面,因此也需要通过 ssh 将数据转发到本地。
2.4.1 TurboMind 服务作为后端
API Server 的启动和上一节一样,这里直接启动作为前端的 Gradio。访问http://127.0.0.1:6006/
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True

2.4.2 TurboMind 推理作为后端
当然,Gradio 也可以直接和 TurboMind 连接,如下所示。
# Gradio+Turbomind(local)
lmdeploy serve gradio ./workspace
可以直接启动 Gradio,此时没有 API Server,TurboMind 直接与 Gradio 通信。如下图所示。访问http://127.0.0.1:6006/