https://www.goethe-verlag.com/book2/ZH
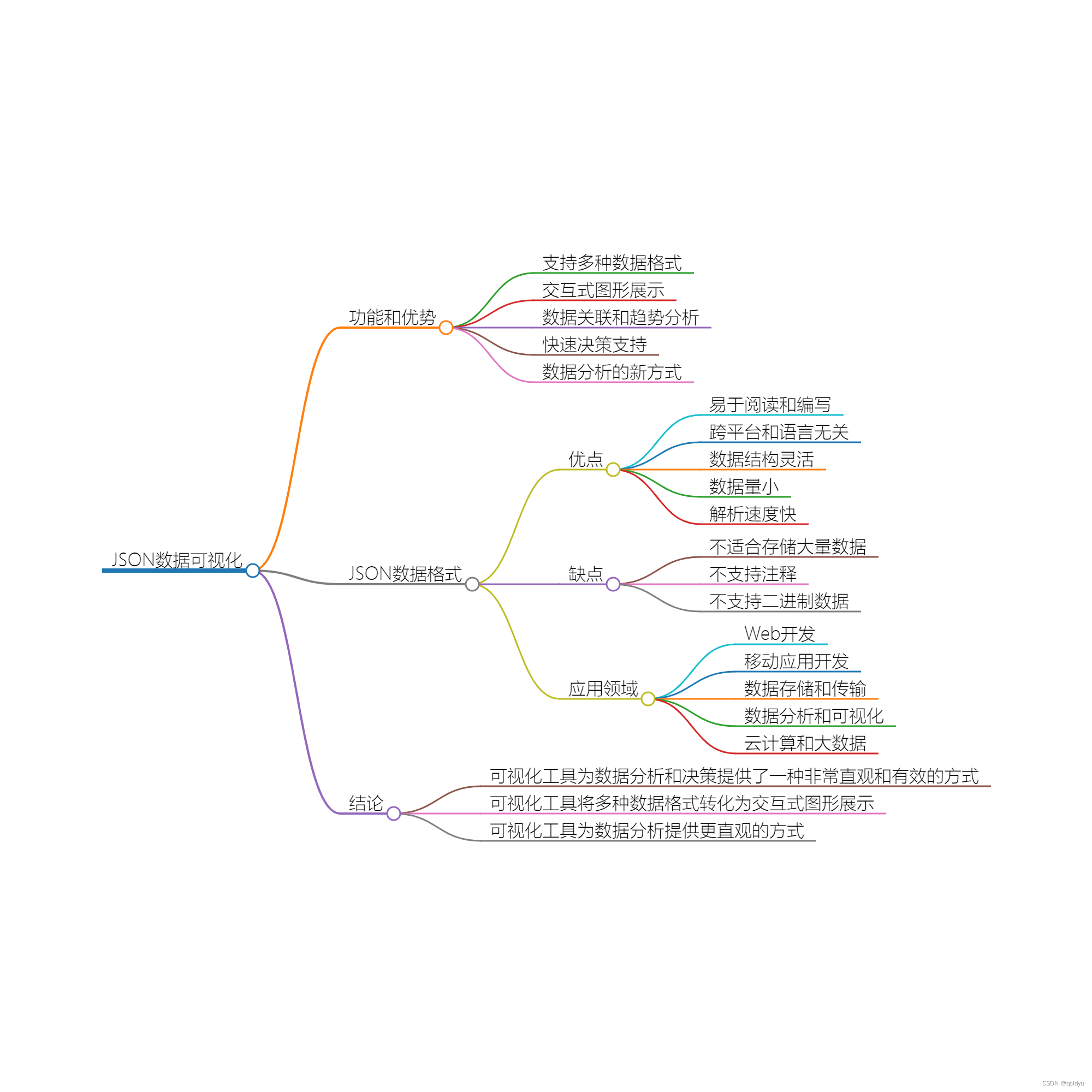
这个网站包含60种语言的日常用语,每种语言包含100课,每课包含18条语言材料(单词、短语、句子),适用于外语学习的入门。学习者选择自己的母语后,再从剩下的59种语言中选择要学习的语言,即可开始学习。以下是英语母语者学习汉语的界面:

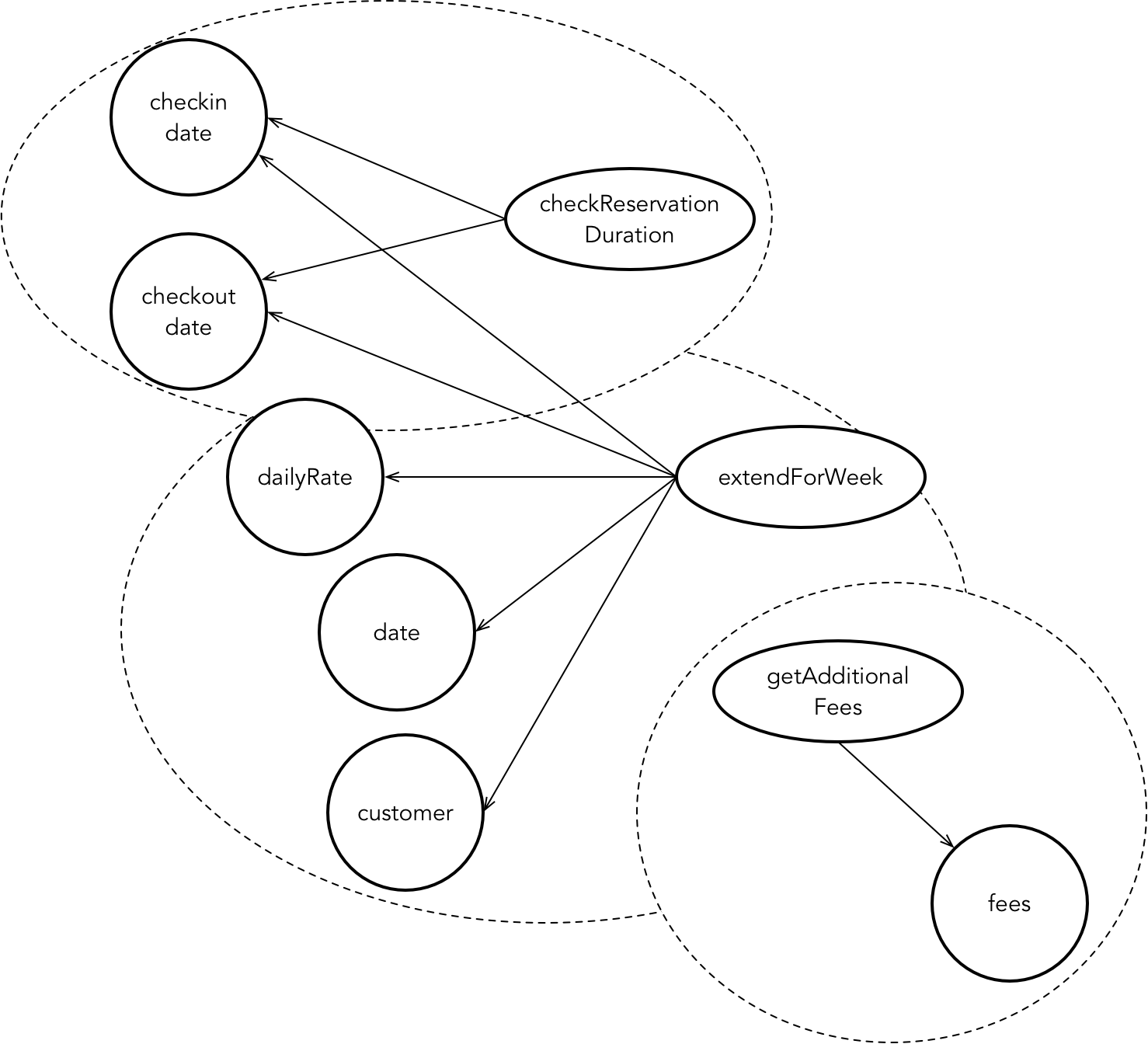
拟采用Python爬虫,获取多语种日常用语平行语料。为此,需要将课程链接、网页源代码与网站界面对照,找到规律后编写爬虫程序获取。
首先观察课程链接,例如上图对应的链接是https://www.goethe-verlag.com/book2/EN/ENZH/ENZH043.HTM
其中的EN表示英语,ZH表示汉语,043为课程号+2并补全前导0。
然后,打开网页源代码,仔细对照其与网页当中语句之间的关系。以上图为例,在源代码中搜索课程号和课程标题(“41 [forty-one] Where is ... ?”),看到以下代码:
<span class="Stil36">41 [forty-one]</span>
<span class="Stil36">
<!-- <b> </b> -->
<b>Where is ... ? </b>
</span>所以,’span‘标签,class=’Stil36‘,对应的是课程号和课程标题。
再搜索课程文本内容,例如“Where is the tourist information office?”,看到以下代码:
<div class="Stil35">
Where is the tourist information office?
</div>所以,’div‘标签,class=’Stil35‘,对应的是课程号和课程标题。
经过以上分析,即可确定爬取方案。该网站不涉及登录、点击按钮等操作,只需要打开页面后提取相关信息,所以无需使用较高级的爬虫技巧,用Python自带的urllib库读取网页,再用第三方库BeautifulSoup解析网页内容,即可获取内容。代码如下:
import urllib.request
from bs4 import BeautifulSoup
lang = 'ZH' # 语言代号,用户自行更改
with open('d:\\temp\\' + lang + r'.txt','w',encoding='utf-8') as f:
for lesson in range(100):
url = r'https://www.goethe-verlag.com/book2/' + lang + r'/' \
+ lang + r'NL/' + lang + r'NL' + "{:03d}".format(lesson + 3) + '.HTM' # 与荷兰语的对照页面
response = urllib.request.urlopen(url)
print(lesson)
html_doc = response.read()
soup = BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")
texts = soup.find_all('span',class_='Stil36') # 课程号、课程标题
for text in texts:
f.write(text.get_text())
texts = soup.find_all('div',class_='Stil35') # 网页左侧一栏的语句
for text in texts[0:18]:
f.write(text.get_text())
f.write('\n')
lang变量存储语言代号,可由用户自行更改,例如EN(英语)、DE(德语)、FR(法语)、RU(俄语)等,具体的可参照:
https://www.goethe-verlag.com/book2/ZH。
url变量中的NL表示荷兰语,是除了lang变量表示的语言之外的任选的一种语言。如果要爬取荷兰语文本,那么设置lang='NL',url变量中指定的网页右侧语言就任选荷兰语之外的一种语言。
由于课程文本很有规律,因此,在输出文件中输出课程号、课程标题和18条课程文本语句即可。
运行程序,爬取指定语种日常用语文本,不同网络环境下,爬取的速度不同。根据本人学习和研究的需求,已在较好的网络环境下,爬取了德语、英语、法语、意大利语、日语、韩语、汉语、俄语的日常用语,并做了后续的整理。除用于外语学习之外,这些语言材料相互之间存在对应关系,是不带分词、词性标注的原始平行语料,可用作自然语言处理算法研究的数据集。




![第一个<span style='color:red;'>Python</span>程序_<span style='color:red;'>获取</span>网页 HTML 信息[<span style='color:red;'>Python</span><span style='color:red;'>爬虫</span><span style='color:red;'>学习</span>笔记]](https://img-blog.csdnimg.cn/img_convert/4aba5bc1617222a7fe9282b011c3b444.png)


























![【sgCreateTableColumn】自定义小工具:敏捷开发→自动化生成表格列html代码(表格列生成工具)[基于el-table-column]](https://img-blog.csdnimg.cn/direct/1ce75f457fb24b5ba540809aedce0013.gif)