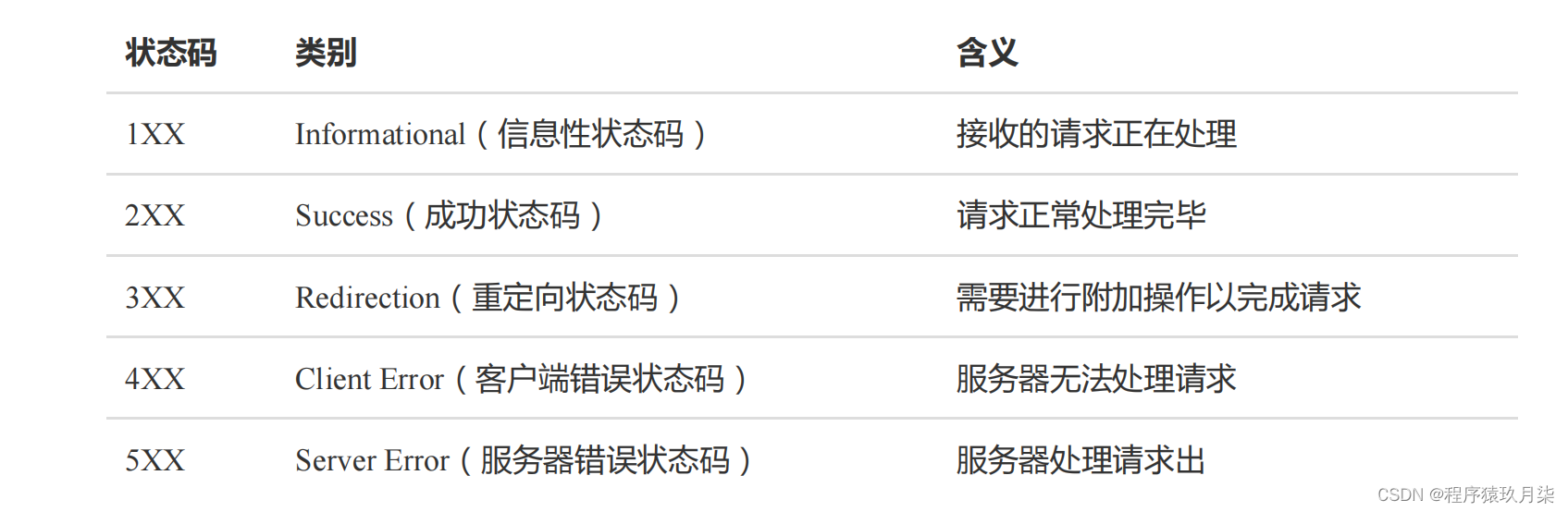
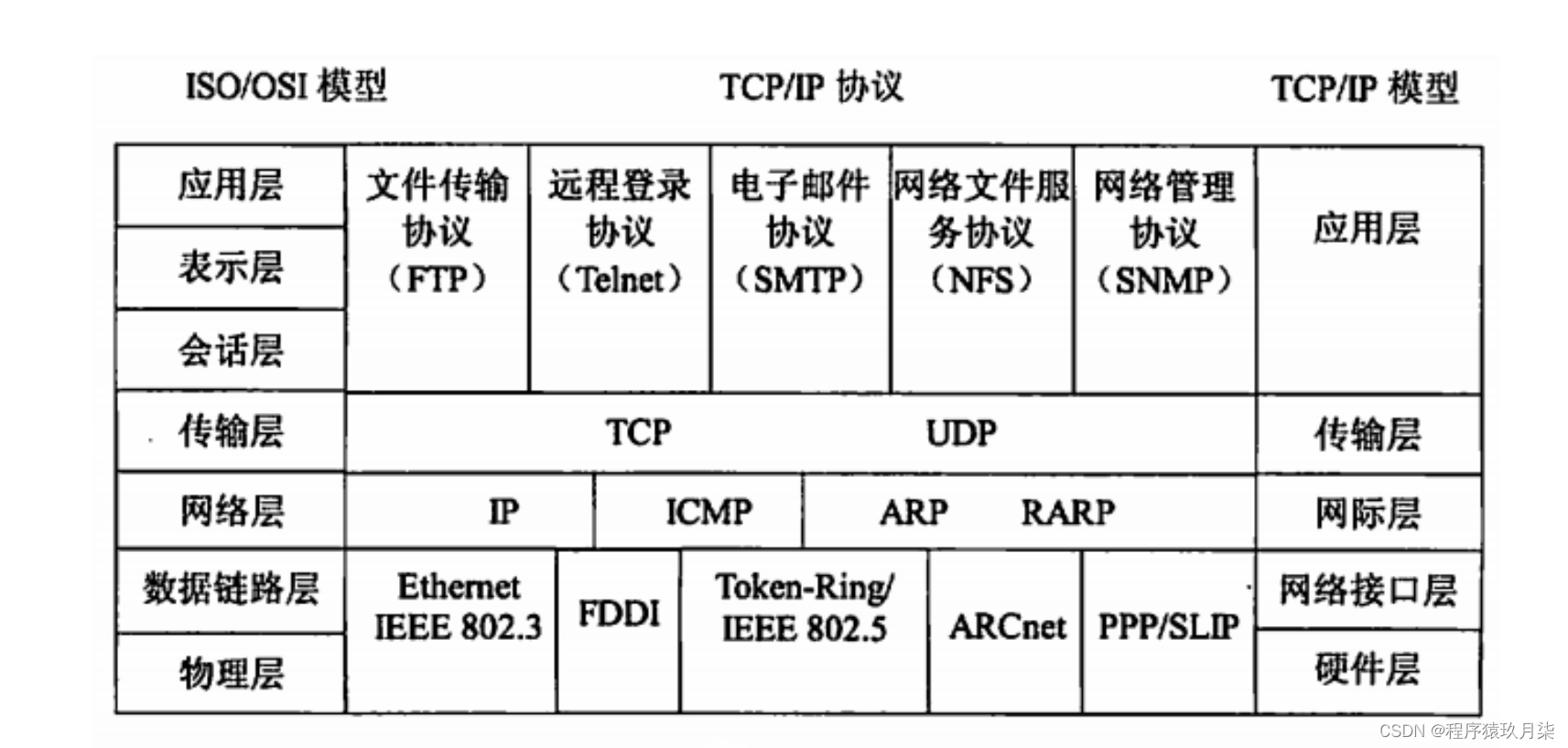
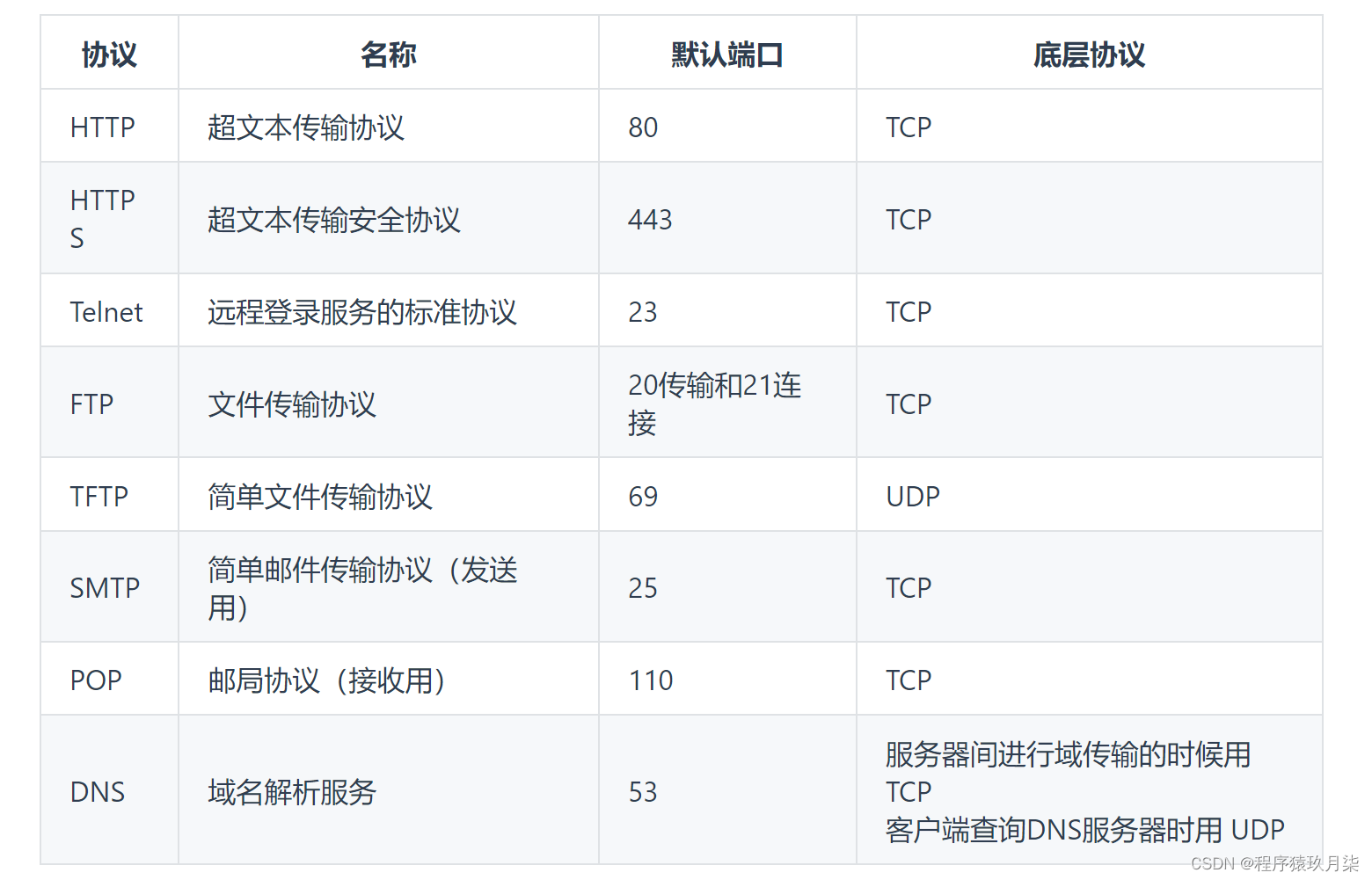
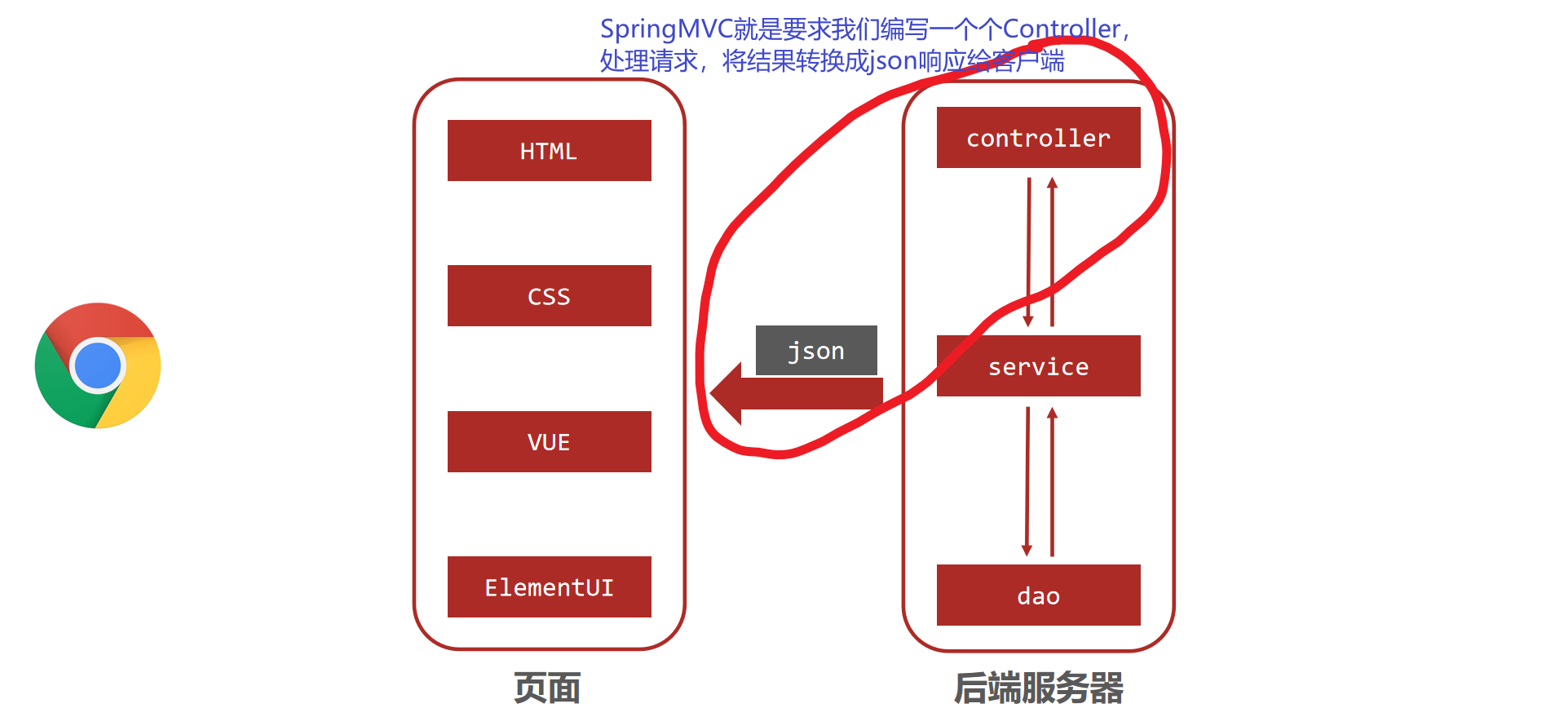
说明:
- 面试群,群号: 228447240
- 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);
- 文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要经过认真思考,答案不重要,重要的是通过题目理解所考知识点,好应对题目更多的变化;
- 博主与大家一起学习,一起刷题,共同进步;
- 写文不易,麻烦给个三连!!!
前面1-15已经是C/C++,但是由于前面写的比较混乱,把八股文和题目混在了一起,所以从这一篇开始重新整理重新写,前面1-15也就可以选看了,希望多多支持!
1.说一下C++左值引用和右值引用
答案:
C++11 正是通过引入右值引用来优化性能,具体来说是通过移动语义来避免无谓拷贝的问题,通过 move语义来将临时生成的左值中的资源无代价的转移到另外一个对象中去,通过完美转发来解决不能按照参数实际类型来转发的问题(同时,完美转发获得的一个好处是可以实现移动语义)。
1) 在 C++11 中所有的值必属于左值、右值两者之一,右值又可以细分为纯右值、将亡值。在 C++11 中可以取地址的、有名字的就是左值,反之,不能取地址的、没有名字的就是右值(将亡值或纯右值)。
2) C++11 对 C++98 中的右值进行了扩充。在 C++11 中右值又分为纯右值( prvalue , Pure Rvalue )和将亡值(xvalue , eXpiring Value )。其中纯右值的概念等同于我们在 C++98 标准中右值的概念,指的是临时变量和不跟对象关联的字面量值;将亡值则是C++11 新增的跟右值引用相关的表达式,这样表达式通常是将要被移动的对象(移为他用),比如返回右值引用T&& 的函数返回值、 std::move 的返回值,或者转换为T&& 的类型转换函数的返回值。将亡值可以理解为通过 “盗取” 其他变量内存空间的方式获取到的值。在确保其他变量不再被使用、或即将被销毁时,通过“ 盗取 ” 的方式可以避免内存空间的释放和分配,能够延长变量值的生命期。
3) 左值引用就是对一个左值进行引用的类型。右值引用就是对一个右值进行引用的类型,事实上,由于右值通常不具有名字,我们也只能通过引用的方式找到它的存在。右值引用和左值引用都是属于引用类型。无论是声明一个左值引用还是右值引用,都必须立即进行初始化。而其原因可以理解为是引用类型本身自己并不拥有所绑定对象的内存,只是该对象的一个别名。左值引用是具名变量值的别名,而右值引用则是不具名(匿名)变量的别名。左值引用通常也不能绑定到右值,但常量左值引用是个“ 万能 ”的引用类型。它可以接受非常量左值、常量左值、右值对其进行初始化。不过常量左值所引用的右值在它的“ 余生 ” 中只能是只读的。相对地,非常量左值只能接受非常量左值对其进行初始化。
4) 右值值引用通常不能绑定到任何的左值,要想绑定一个左值到右值引用,通常需要 std::move() 将左值强制转换为右值。
简单来看看概念:
左值:表示的是可以获取地址的表达式,它能出现在赋值语句的左边,对该表达式进行赋值。但是修饰符const的出现使得可以声明如下的标识符,它可以取得地址,但是没办法对其进行赋值。 const int & a = 10 ;
右值:表示无法获取地址的对象,有常量值、函数返回值、 lambda 表达式等。无法获取地址,但不表示其不可改变,当定义了右值的右值引用时就可以更改右值。
左值引用:传统的 C++ 中引用被称为左值引用
右值引用: C++11 中增加了右值引用,右值引用关联到右值时,右值被存储到特定位置,右值引用指向该特定位置,也就是说,右值虽然无法获取地址,但是右值引用是可以获取地址的,该地址表示临时对象的存储位置
右值引用的特点:
1. 通过右值引用的声明,右值又 “ 重获新生 ” ,其生命周期与右值引用类型变量的生命周期一样 长,只要该变量还活着,该右值临时量将会一直存活下去
2. 右值引用独立于左值和右值。意思是右值引用类型的变量可能是左值也可能是右值
3. T&& t 在发生自动类型推断的时候,它是左值还是右值取决于它的初始化
#include <bits/stdc++.h>
using namespace std;
template<typename T>
void fun(T&& t)
{
cout << t << endl;
}
int getInt()
{
return 5;
}
int main() {
int a = 10;
int& b = a; //b是左值引用
int& c = 10; //错误,c是左值不能使用右值初始化
int&& d = 10; //正确,右值引用用右值初始化
int&& e = a; //错误,e是右值引用不能使用左值初始化
const int& f = a; //正确,左值常引用相当于是万能型,可以用左值或者右值初始化
const int& g = 10;//正确,左值常引用相当于是万能型,可以用左值或者右值初始化
const int&& h = 10; //正确,右值常引用
const int& aa = h;//正确
int& i = getInt(); //错误,i是左值引用不能使用临时变量(右值)初始化
int&& j = getInt(); //正确,函数返回值是右值
fun(10); //此时fun函数的参数t是右值
fun(a); //此时fun函数的参数t是左值
return 0;
}2.vector与list的区别与应用
答案:
1) vector数据结构
vector 和数组类似,拥有一段连续的内存空间,并且起始地址不变。因此能高效的进行随机存取,时间复杂度为o(1); 但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,时间复杂度为o(n) 。另外,当数组中内存空间不够时,会重新申请一块内存空间并进行内存拷贝。连续存储结构:vector 是可以实现动态增长的对象数组,支持对数组高效率的访问和在数组尾端的删除和插入操作,在中间和头部删除和插入相对不易,需要挪动大量的数据。它与数组最大的区别就是vector 不需程序员自己去考虑容量问题,库里面本身已经实现了容量的动态增长,而数组需要程序员手动写入扩容函数进形扩容。
2) list数据结构
list 是由双向链表实现的,因此内存空间是不连续的。只能通过指针访问数据,所以 list 的随机存取非常没有效率,时间复杂度为o(n); 但由于链表的特点,能高效地进行插入和删除。非连续存储结构: list 是一个双链表结构,支持对链表的双向遍历。每个节点包括三个信息:元素本身,指向前一个元素的节点(prev )和指向下一个元素的节点( next )。因此 list 可以高效率的对数据元素任意位置进行访问和插入删除等操作。由于涉及对额外指针的维护,所以开销比较大。
区别:
vector 的随机访问效率高,但在插入和删除时(不包括尾部)需要挪动数据,不易操作。 list 的访问要遍历整个链表,它的随机访问效率低。但对数据的插入和删除操作等都比较方便,改变指针的指向即可。list是单向的, vector 是双向的。 vector 中的迭代器在使用后就失效了,而 list 的迭代器在使用之后还可以 继续使用。
3. STL 中vector删除其中的元素,迭代器如何变化?为什么是两倍扩容?释放空间
答案:
size() 函数返回的是已用空间大小, capacity() 返回的是总空间大小, capacity()-size() 则是剩余的可用空间大小。当size() 和 capacity() 相等,说明 vector 目前的空间已被用完,如果再添加新元素,则会引起 vector 空间的动态增长。
resize() 成员函数只改变元素的数目,不改变 vector 的容量。
1 、空的 vector 对象, size() 和 capacity() 都为 0
2 、当空间大小不足时,新分配的空间大小为原空间大小的 2 倍。
3 、使用 reserve() 预先分配一块内存后,在空间未满的情况下,不会引起重新分配,从而提升了效率。
4 、当 reserve() 分配的空间比原空间小时,是不会引起重新分配的。
5 、 resize() 函数只改变容器的元素数目,未改变容器大小。
6 、用 reserve(size_type) 只是扩大 capacity 值,这些内存空间可能还是 “ 野 ” 的,如果此时使用 “[ ]” 来访问,则可能会越界。而resize(size_type new_size) 会真正使容器具有 new_size 个对象。
不同的编译器,vector有不同的扩容大小。在vs下是1.5倍,在GCC下是2倍。
4.Vector如何释放空间
答案:
由于 vector 的内存占用空间只增不减,比如你首先分配了 10,000 个字节,然后 erase 掉后面 9,999 个,留下一个有效元素,但是内存占用仍为10,000 个。所有内存空间是在 vector 析构时候才能被系统回收。empty()用来检测容器是否为空的, clear() 可以清空所有元素。但是即使 clear() , vector 所占用的内存空间依然如故,无法保证内存的回收。
如果需要空间动态缩小,可以考虑使用 deque 。如果 vector ,可以用 swap() 来帮助你释放内存。
vector(Vec).swap(Vec); //将Vec的内存清除;
vector().swap(Vec); //清空Vec的内存;5.容器内部删除一个元素
答案:
1) 顺序容器(序列式容器,比如 vector 、 deque )
erase 迭代器不仅使所指向被删除的迭代器失效,而且使被删元素之后的所有迭代器失效 (list 除外 ),所以不能使用erase(it++)的方式,但是erase的返回值是下一个有效迭代器;it = c.erase(it);
2) 关联容器 ( 关联式容器,比如 map 、 set 、 multimap 、 multiset 等 )
erase 迭代器只是被删除元素的迭代器失效,但是返回值是 void ,所以要采用 erase(it++)的方式删除迭代器; c.erase(it++)
6.STL迭代器如何实现
答案:
1 、 迭代器是一种抽象的设计理念,通过迭代器可以在不了解容器内部原理的情况下遍历容器,除此之外,STL 中迭代器一个最重要的作用就是作为容器与 STL 算法的粘合剂。
2 、 迭代器的作用就是提供一个遍历容器内部所有元素的接口,因此迭代器内部必须保存一个与容器相关联的指针,然后重载各种运算操作来遍历,其中最重要的是* 运算符与 -> 运算符,以及 ++ 、 -- 等可能需要重载的运算符重载。这和C++ 中的智能指针很像,智能指针也是将一个指针封装,然后通过引用计数或是其他方法完成自动释放内存的功能。
3 、最常用的迭代器的相应型别有五种: value type 、 difference type 、 pointer 、 reference 、 iterator catagoly;
7.map插入方式有哪几种?
答案:
1) 用insert函数插入pair数据,
mapStudent.insert(pair<int, string>(1, "student_one"));
2) 用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type (1, "student_one"));
3) 在insert函数中使用make_pair()函数
mapStudent.insert(make_pair(1, "student_one"));
4) 用数组方式插入数据
mapStudent[1] = "student_one";8.map中[]与find的区别
答案:
1) map 的下标运算符 [] 的作用是:将关键码作为下标去执行查找,并返回对应的值;如果不存在这个关键码,就将一个具有该关键码和值类型的默认值的项插入这个map 。
2) map 的 find 函数:用关键码执行查找,找到了返回该位置的迭代器;如果不存在这个关键码,就返回尾迭代器。
9.STL中list与queue之间的区别
答案:
1. list不再能够像vector一样以普通指针作为迭代器,因为其节点不保证在存储空间中连续存在;
2. list不仅是一个双向链表,而且还是一个环状双向链表,所以它只需要一个指针;
3. list不像vector那样有可能在空间不足时做重新配置、数据移动的操作,所以插入前的所有迭代器在插入操作之后都仍然有效;
4. deque是一种双向开口的连续线性空间,所谓双向开口,意思是可以在头尾两端分别做元素的插入和删除操作;
5. deque和vector最大的差异,一在于deque允许常数时间内对起头端进行元素的插入或移除操作;二在于deque没有所谓容量概念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来,deque没有所谓的空间保留功能。
10.STL中的allocator、deallocator
答案:
1) 第一级配置器直接使用 malloc() 、 free() 和 relloc() ,第二级配置器视情况采用不同的策略:当配置区块超过128bytes 时,视之为足够大,便调用第一级配置器;当配置器区块小于 128bytes 时,为了降低额外负担,使用复杂的内存池整理方式,而不再用一级配置器;
2) 第二级配置器主动将任何小额区块的内存需求量上调至 8 的倍数,并维护 16 个 free-list ,各自管理大小为8~128bytes 的小额区块;
3) 空间配置函数 allocate() ,首先判断区块大小,大于 128 就直接调用第一级配置器,小于 128 时就检查对应的free-list 。如果 free-list 之内有可用区块,就直接拿来用,如果没有可用区块,就将区块大小调整至 8的倍数,然后调用refill() ,为 free-list 重新分配空间;
4) 空间释放函数 deallocate() ,该函数首先判断区块大小,大于 128bytes 时,直接调用一级配置器,小于128bytes就找到对应的 free-list 然后释放内存。
11.说一下STL每种容器对应的迭代器
答案:

12.STL中迭代器失效的情况有哪些
答案:
以vector为例:
插入元素:
1、尾后插入:size < capacity时,首迭代器不失效尾迭代失效(未重新分配空间),size == capacity时,所有迭代器均失效(需要重新分配空间)。
2、中间插入:中间插入:size < capacity时,首迭代器不失效但插入元素之后所有迭代器失效,size == capacity时,所有迭代器均失效。
删除元素:
尾后删除:只有尾迭代失效。
中间删除:删除位置之后所有迭代失效。
deque 和 vector 的情况类似,
而list双向链表每一个节点内存不连续, 删除节点仅当前迭代器失效,erase返回下一个有效迭代器;
map/set等关联容器底层是红黑树删除节点不会影响其他节点的迭代器, 使用递增方法获取下一个迭代器 mmp.erase(iter++);
unordered_(hash) 迭代器意义不大, rehash之后, 迭代器应该也是全部失效。