172.16.10.21 prometheus
172.16.10.33 altermanager
172.16.10.59 mysql服务,node探针以及mysql的探针
[root@k8s-node02 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d0a03819e7f8 harbor.jettech.com/prometheus/mysqld-exporter:latest "/bin/mysqld_exporte…" 10 minutes ago Up 10 minutes 0.0.0.0:9104->9104/tcp, :::9104->9104/tcp mysql-export
b62689186d4c harbor.jettech.com/prometheus/node-exporter:latest "/bin/node_exporter …" 20 hours ago Up 2 hours node
09f094a92ef1 harbor.jettech.com/jettechtools/mysql:8.0.28 "docker-entrypoint.s…" 21 hours ago Up 5 minutes
1.prometheus 172.16.10.21
1.1)配置文件
[root@nginx conf]# cat prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout: 10s
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.16.10.33:9093
rule_files:
- "rules/*_rules.yml"
scrape_configs:
- job_name: "jettech-prod-node-59"
static_configs:
- targets:
- 172.16.10.59:9100
labels:
instance: "172.16.10.59-wubo"
ip: "172.16.10.59-wubo"
env: "prod-wubo-59"
team: "jettopro-wubo-59"
name: jettech
group1: g1
nodeDown: NodeDown
#file ds
- job_name: "jettech-prod-mysql8"
static_configs:
- targets: ["172.16.10.59:9104"]
labels:
instance: mysqld-exporter
node: NodeDown
name: wubo1.2)规则mysql
[root@nginx rules]# cat mysql_rules.yml
groups:
- name: 数据库资源监控
rules:
#mysql状态检测
- alert: MySQL Status
expr: mysql_up == 0
for: 10s
labels:
severity: warning
annotations:
summary: "{
{ $labels.instance }} Mysql服务 !!!"
description: "{
{ $labels.instance }} Mysql服务不可用 请检查!"
#mysql主从IO线程停止时触发告警
- alert: MySQL Slave IO Thread Status
expr: mysql_slave_status_slave_io_running == 0
for: 5s
labels:
severity: warning
annotations:
summary: "{
{ $labels.instance }} Mysql从节点IO线程"
description: "Mysql主从IO线程故障,请检测!"
#mysql主从sql线程停止时触发告警
- alert: MySQL Slave SQL Thread Status
expr: mysql_slave_status_slave_sql_running == 0
for: 5s
labels:
severity: error
annotations:
summary: "{
{$labels.instance}}: MySQL Slave SQL Thread has stop !!!"
description: "检测MySQL主从SQL线程运行状态"
#mysql主从延时状态告警
- alert: MySQL Slave Delay Status
expr: mysql_slave_status_sql_delay == 30
for: 5s
labels:
severity: warning
annotations:
summary: "{
{$labels.instance}}: MySQL 主从延迟超过 30s !!!"
description: "检测MySQL主从延时状态"
#mysql连接数告警
- alert: Mysql_Too_Many_Connections
expr: rate(mysql_global_status_threads_connected[5m]) > 200
for: 2m
labels:
severity: warning
annotations:
summary: "{
{$labels.instance}}: 连接数过多"
description: "{
{$labels.instance}}: 连接数过多,请处理 ,(current value is: {
{ $value }})!"
#mysql慢查询有点多告警
- alert: Mysql_Too_Many_slow_queries
expr: rate(mysql_global_status_slow_queries[5m]) > 3
for: 2m
labels:
severity: warning
annotations:
summary: "{
{$labels.instance}}: 慢查询有点多,请检查处理!"
description: "{
{$labels.instance}}: Mysql slow_queries is more than 3 per second ,(current value is: {
{ $value }})"1.3)node规则
[root@nginx rules]# cat node_rules.yml
groups:
- name: 服务器资源监控
rules:
- alert: 内存使用率过高
expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 80
for: 3m
labels:
severity: 严重告警
annotations:
summary: "{
{ $labels.instance }} 内存使用率过高, 请尽快处理!"
description: "{
{ $labels.instance }}内存使用率超过80%,当前使用率{
{ $value }}%."
- alert: 服务器宕机
expr: up == 0
for: 10s
labels:
severity: 严重告警
annotations:
summary: "{
{$labels.instance}} 服务器宕机, 请尽快处理!"
description: "{
{$labels.instance}} 服务器延时超过3分钟,当前状态{
{ $value }}. "
- alert: CPU高负荷
expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{
{$labels.instance}} CPU使用率过高,请尽快处理!"
description: "{
{$labels.instance}} CPU使用大于90%,当前使用率{
{ $value }}%. "
- alert: 磁盘IO性能
expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 90
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{
{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"
description: "{
{$labels.instance}} 流入磁盘IO大于90%,当前使用率{
{ $value }}%."
- alert: 网络流入
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{
{$labels.instance}} 流入网络带宽过高,请尽快处理!"
description: "{
{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{
{$value}}."
- alert: 网络流出
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: 严重告警
annotations:
summary: "{
{$labels.instance}} 流出网络带宽过高,请尽快处理!"
description: "{
{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."
- alert: TCP连接数
expr: node_netstat_Tcp_CurrEstab > 10000
for: 2m
labels:
severity: 严重告警
annotations:
summary: " TCP_ESTABLISHED过高!"
description: "{
{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{
{ $value }}%."
- alert: 磁盘容量
#expr: 100 - round(node_filesystem_free_bytes{fstype=~"ext3|ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 30
expr: 100 - round(node_filesystem_free_bytes{device="/dev/mapper/centos-root",fstype=~"ext3|ext4|xfs"}/node_filesystem_size_bytes {device="/dev/mapper/centos-root",fstype=~"ext4|xfs"}*100) > 10
for: 1m
labels:
severity: 严重告警
annotations:
summary: "{
{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"
description: "{
{$labels.instance}} 磁盘分区使用大于10%,当前使用率{
{ $value }}%."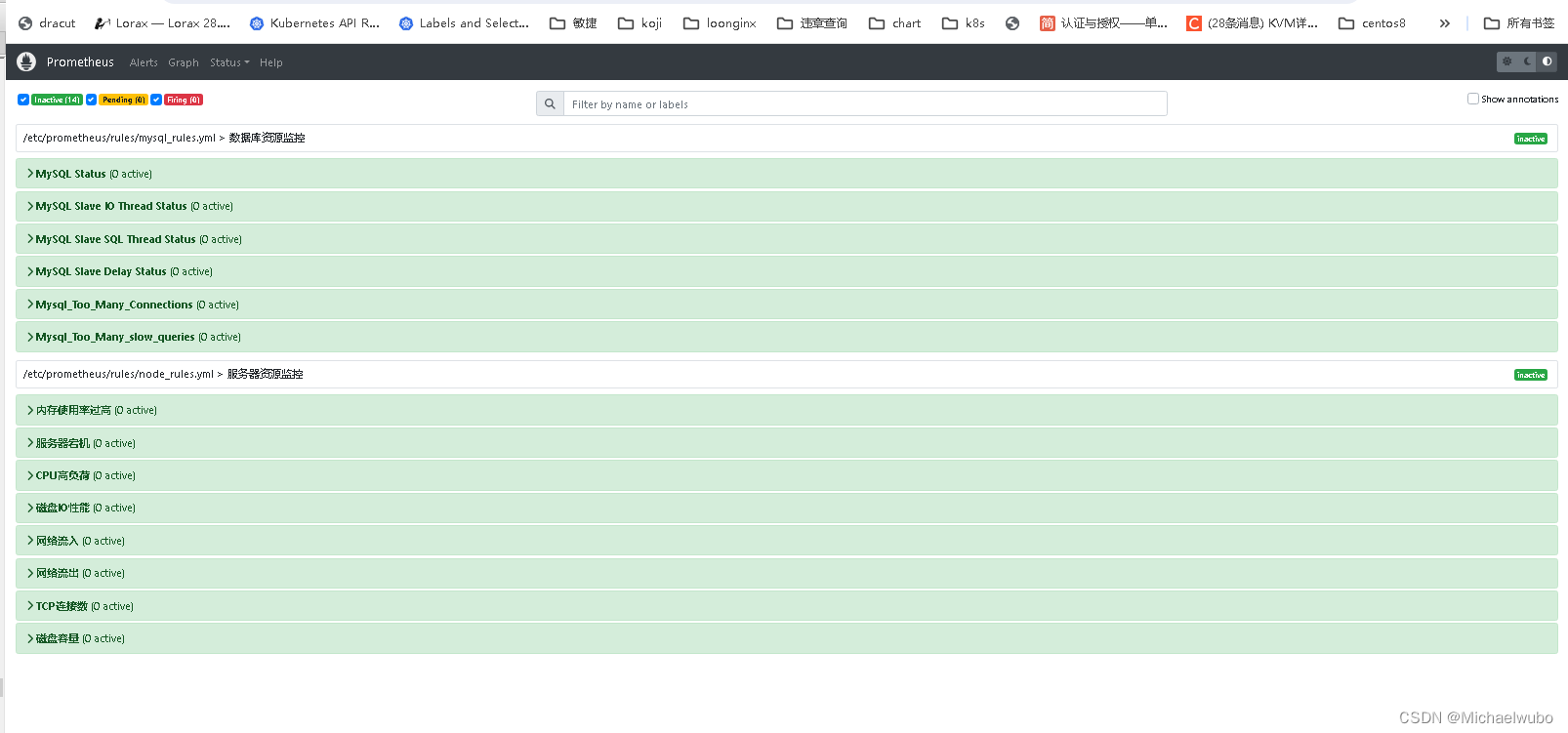
2.altermanger 172.16.10.33
2.1)配置
[root@k8s-node03 config]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_hello: 'localhost'
smtp_from: '459097610@qq.com'
smtp_auth_username: '459097610@qq.com'
smtp_auth_password: 'oqiapxzubiajbgjh'
smtp_require_tls: false
templates:
- 'templates/email.tmpl'
- 'templates/email_wubo.tmpl'
- 'templates/email_wuqi.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
routes:
- receiver: 'email_wubo'
continue: false
#group_by: [group1]
#match:
# name: jettech
#team: jettopro-wubo-33
#env: prod-wubo-33
#- receiver: 'email_wuqi'
# continue: false
# group_by: [group1]
# #match:
# # name: jettech
# #team: jettopro-wuqi-65
# #env: prod-wuqi-65
receivers:
- name: 'email'
email_configs:
- to: '{
{ template "email.to" }}'
html: '{
{ template "email.to.html" . }}'
send_resolved: true #故障恢复后通知
- name: 'email_wubo'
email_configs:
- to: '{
{ template "email_wubo.to" }}'
html: '{
{ template "email_wubo.to.html" . }}'
send_resolved: true #故障恢复后通知
- name: 'email_wuqi'
email_configs:
- to: '{
{ template "email_wuqi.to" }}'
html: '{
{ template "email_wuqi.to.html" . }}'
send_resolved: true #故障恢复后通知
#inhibit_rules:
# - target_match:
# name: jettech
# nodeDown: NodeDown
# source_match:
# name: wubo
# equal:
# - node2.2)模版
[root@k8s-node03 config]# cat templates/email.tmpl
{
{ define "email.to" }}459097610@qq.com{
{ end }}
{
{ define "email.to.html" }}
{
{- if gt (len .Alerts.Firing) 0 -}}{
{ range .Alerts }}
<h2>@告警通知</h2>
告警程序: prometheus_alertmanager <br>
告警级别: {
{ .Labels.severity }} 级 <br>
告警类型: {
{ .Labels.alertname }} <br>
故障主机: {
{ .Labels.instance }} <br>
故障主机所属环境: {
{ .Labels.env }} <br>
故障主机所属团队: {
{ .Labels.team }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ .Annotations.description }} <br>
触发时间: {
{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{
{ end }}{
{ end -}}
{
{- if gt (len .Alerts.Resolved) 0 -}}{
{ range .Alerts }}
<h2>@告警恢复</h2>
告警程序: prometheus_alert <br>
故障主机: {
{ .Labels.instance }}<br>
故障主机所属环境: {
{ .Labels.env }} <br>
故障主机所属团队: {
{ .Labels.team }} <br>
故障主题: {
{ .Annotations.summary }}<br>
告警详情: {
{ .Annotations.description }}<br>
告警时间: {
{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}<br>
恢复时间: {
{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}<br>
{
{ end }}{
{ end -}}
{
{- end }}3 被检测服务 172.16.10.59
3.1)探针mysql
[root@k8s-node02 ~]# docker run -d --name mysql-export -p 9104:9104 -v /opt/export/mysql/conf/my.cnf:/etc/mysql/my.cnf -d harbor.jettech.com/prometheus/mysqld-exporter:latest --collect.info_schema.processlist --collect.info_schema.innodb_tablespaces --collect.info_schema.innodb_metrics --collect.perf_schema.tableiowaits --collect.perf_schema.indexiowaits --collect.perf_schema.tablelocks --collect.engine_innodb_status --collect.perf_schema.file_events --collect.binlog_size --collect.info_schema.clientstats --collect.perf_schema.eventswaits --config.my-cnf=/etc/mysql/my.cnf3.2)探针node
[root@k8s-node02 ~]# docker run --name node --net="host" --pid="host" -v "/:/host:ro,rslave" -d harbor.jettech.com/prometheus/node-exporter:latest --path.rootfs=/host3.3)被检测服务:mysql服务
[root@k8s-node02 ~]# docker run --name mysql8 --net host -e MYSQL_ROOT_PASSWORD=123456aA -d harbor.jettech.com/jettechtools/mysql:8.0.284开始测试:
4.1)alertmanager,不加抑制inhibit_rules配置
[root@k8s-node03 config]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_hello: 'localhost'
smtp_from: '459097610@qq.com'
smtp_auth_username: '459097610@qq.com'
smtp_auth_password: 'oqiapxzubiajbgjh'
smtp_require_tls: false
templates:
- 'templates/email.tmpl'
- 'templates/email_wubo.tmpl'
- 'templates/email_wuqi.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
routes:
- receiver: 'email_wubo'
continue: false
#group_by: [group1]
#match:
# name: jettech
#team: jettopro-wubo-33
#env: prod-wubo-33
#- receiver: 'email_wuqi'
# continue: false
# group_by: [group1]
# #match:
# # name: jettech
# #team: jettopro-wuqi-65
# #env: prod-wuqi-65
receivers:
- name: 'email'
email_configs:
- to: '{
{ template "email.to" }}'
html: '{
{ template "email.to.html" . }}'
send_resolved: true #故障恢复后通知
- name: 'email_wubo'
email_configs:
- to: '{
{ template "email_wubo.to" }}'
html: '{
{ template "email_wubo.to.html" . }}'
send_resolved: true #故障恢复后通知
- name: 'email_wuqi'
email_configs:
- to: '{
{ template "email_wuqi.to" }}'
html: '{
{ template "email_wuqi.to.html" . }}'
send_resolved: true #故障恢复后通知4.1.1)同时172.16.10.59这个服务器mysql服务停止和磁盘写入数据
[root@k8s-node02 ~]# docker stop 09f094a92ef1
09f094a92ef1
[root@k8s-node02 ~]# dd if=/dev/zero of=/test bs=1024M count=5
记录了5+0 的读入
记录了5+0 的写出
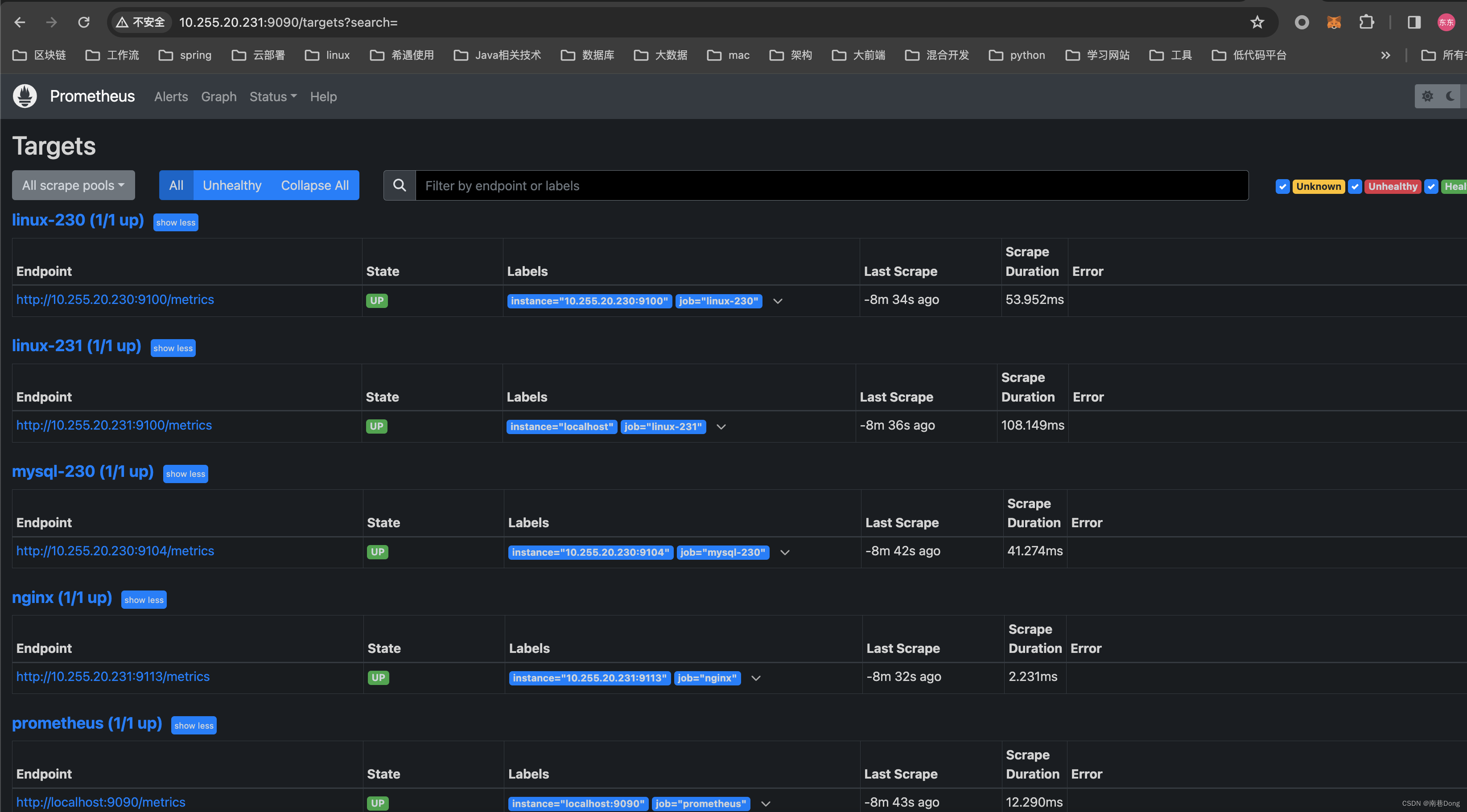
5368709120字节(5.4 GB)已复制,12.2983 秒,437 MB/秒4.1.2)这样prometheus会触发两次报警

4.1.3)alertmanager也会收到2次prometheus传过来的报警
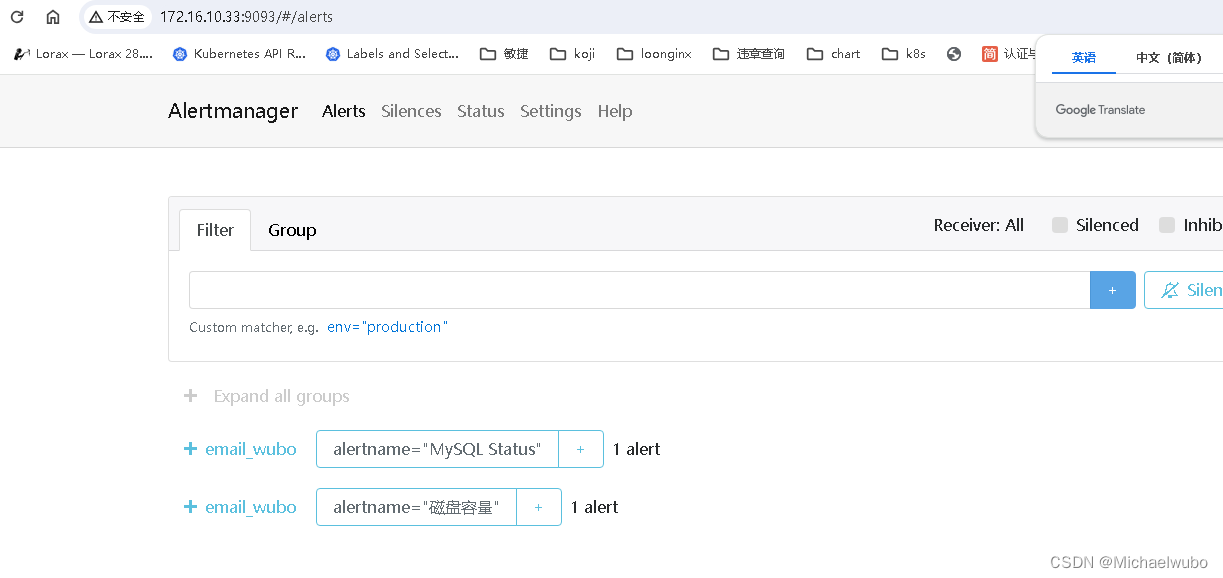
4.1.4)进而alertmanager也会发两次邮件

4.1.5)者直接给node关机,看看发几次报警
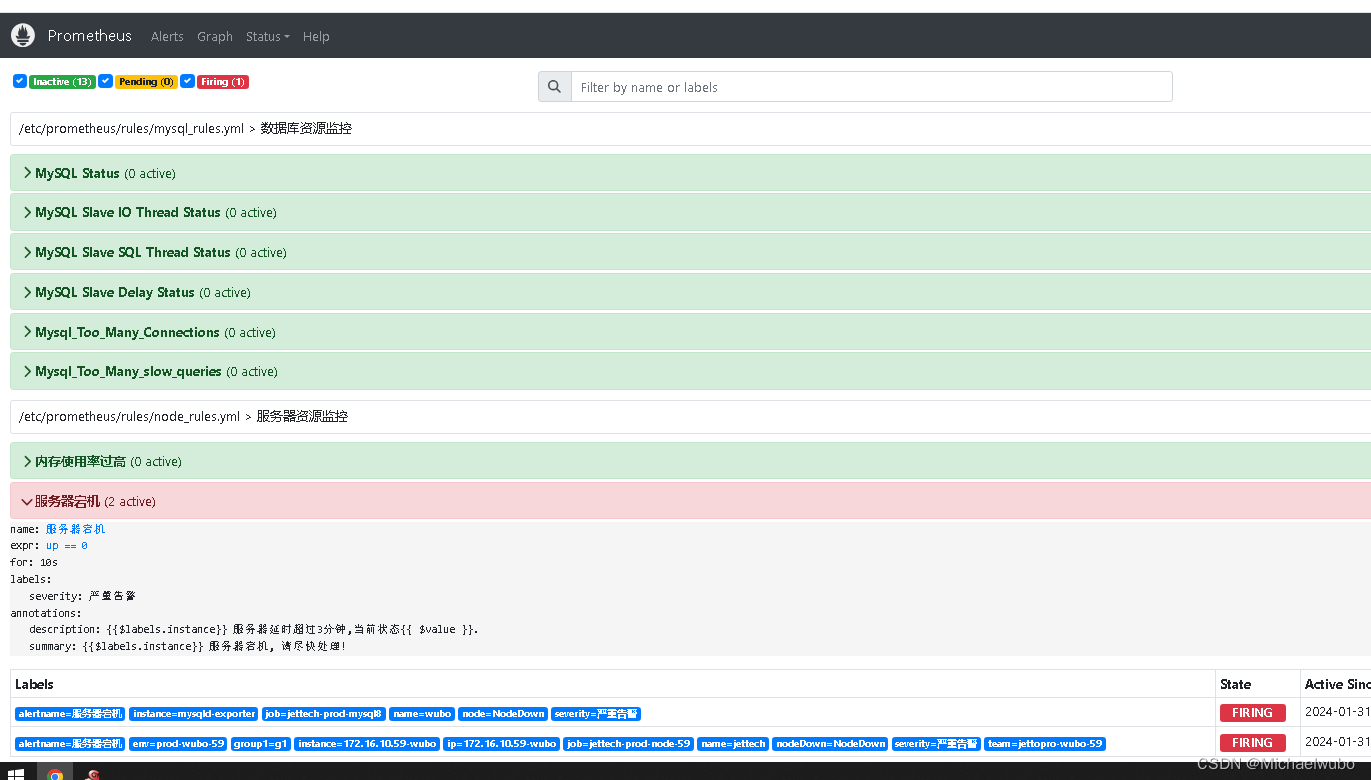
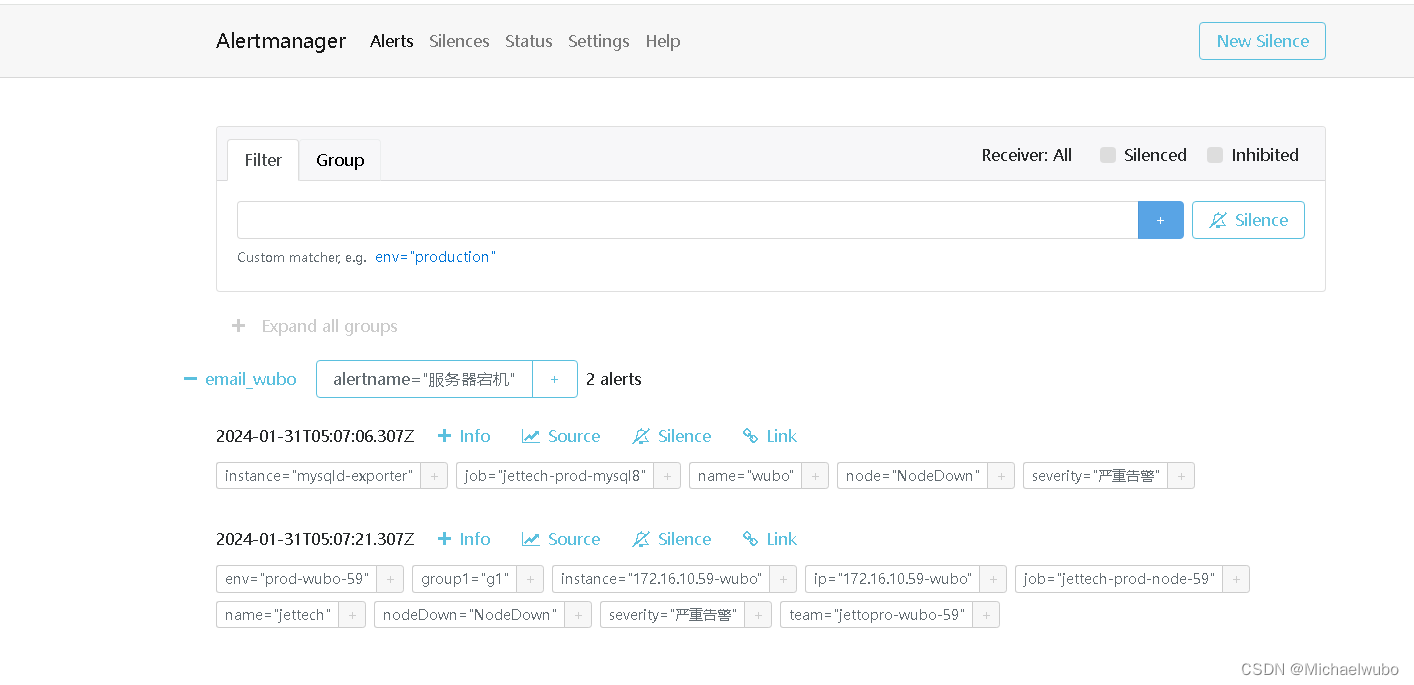

看结果还是两次 ,但是如果node节点关机了,mysql服务就一定断开了,node节点应该发一次报警就可以了,mysql服务器不用再次发送报警才合理


































![[嵌入式系统-7]:龙芯1B 开发学习套件 -4- LoongIDE 集成开发工具的使用-创建应用程序工程、编译、下载、调试](https://img-blog.csdnimg.cn/direct/4615fb235e954865b25d57868378e751.png)

