Kafka 简介
kafka 是一款分布式消息发布和订阅的系统,具有高性能和高吞吐率。
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。

核心概念:
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为brokerTopic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.Producer
负责发布消息到Kafka brokerConsumer
消息消费者,向Kafka broker读取消息的客户端。Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)消息的发布(publish)称作producer,消息的订阅(subscribe)称作consumer,中间的存储阵列称作broker。
多个broker协同合作,producer、consumer和broker三者之间通过zookeeper来协调请求和转发。
producer产生和推送(push)数据到broker,consumer从broker拉取(pull)数据并进行处理。
broker端不维护数据的消费状态,提升了性能。
直接使用磁盘进行存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制,减少耗性能的创建对象和垃圾回收。
Kafka使用scala编写,可以运行在JVM上。
Kafaka 安装
可以按照 CHD5.11 离线安装或者升级 Spark2.x 详细步骤 教程进行安装。
角色分配:
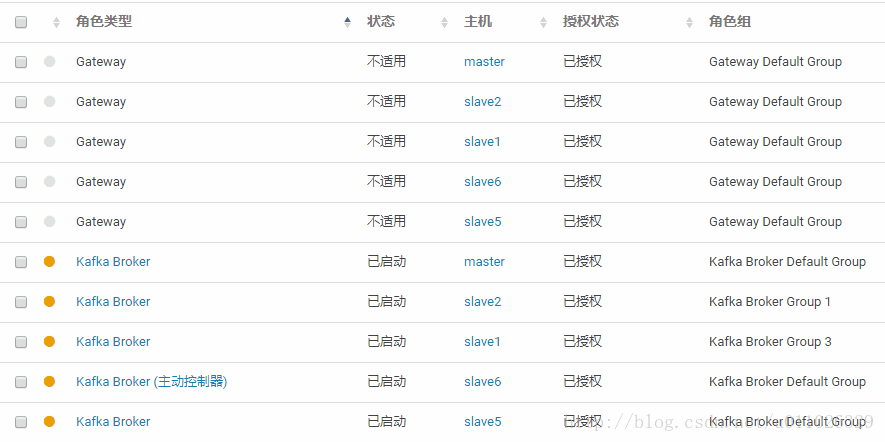
安装出现如下问题及解决方案:
WARN Log Found a corrupted index file, /var/local/kafka/data/__consumer_offsets-33/00000000000000000000.index, deleting and rebuilding index...
上午10点10:04.842分 FATAL KafkaServer
Fatal error during KafkaServer startup. Prepare to shutdown
kafka.common.InconsistentBrokerIdException: Configured broker.id 118 doesn't match stored broker.id 145 in meta.properties. If you moved your data, make sure your configured broker.id matches. If you intend to create a new broker, you should remove all data in your data directories (log.dirs).
at kafka.server.KafkaServer.getBrokerId(KafkaServer.scala:648)
at kafka.server.KafkaServer.startup(KafkaServer.scala:187)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:37)
at kafka.Kafka$.main(Kafka.scala:67)
at com.cloudera.kafka.wrap.Kafka$.main(Kafka.scala:76)
at com.cloudera.kafka.wrap.Kafka.main(Kafka.scala)
// 解决方案
vi /opt/cloudera/parcels/KAFKA/etc/kafka/conf.dist/server.properties
看到:
log.dirs=/tmp/kafka-logs
删除 log.dirs 目录
结果发现 /tmp/kafka-logs没有,全部在/tmp目录下,故执行 rm -rf /tmp/kafka*
在删除log 文件, rm -Rf /var/log/kafka*
// 然后重新安装kafka就可以了
Kafka 简单使用
Kafka command-line tools are located in /usr/bin:
kafka-topics
// 创建 topic test
# kafka-topics --create --zookeeper master:2181 --replication-factor 2 --partitions 4 --topic test
Created topic "test".
// 查看 topics
# kafka-topics --zookeeper master:2181 --list
test
// 删除 topic test
kafka-topics --delete --zookeeper master:2181 --topic test
kafka-console-consumer
Read data from a Kafka topic and write it to standard output. For example:
// 在slave1 上启动 consumer
kafka-console-consumer --zookeeper slave1:2181 --topic test
kafka-console-producer
Read data from standard output and write it to a Kafka topic. For example:
# kafka-console-producer --broker-list slave1:9092,slave2:9092 --topic test
然后在屏幕上输入数据,在consumer端可以接收到数据。






























![[嵌入式系统-7]:龙芯1B 开发学习套件 -4- LoongIDE 集成开发工具的使用-创建应用程序工程、编译、下载、调试](https://img-blog.csdnimg.cn/direct/4615fb235e954865b25d57868378e751.png)

