接上篇《47、Scrapy Shell的了解与应用》
上一篇我们学习了Scrapy终端命令行工具Scrapy Shell,并了解了它是如何帮助我们更好的调试爬虫程序的。本篇我们将正式开启一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。
一、当当网介绍
当当网成立于1999年11月,是一家知名的综合性网上购物商城。从早期以图书业务为主的业务形态,逐步拓展到全品类百货,包括图书音像、美妆、家居、母婴、服装和3C数码等几十个大类,数百万种商品。
二、需要抓取的页面分析
我们进入当当网首页,点击“图书”链接: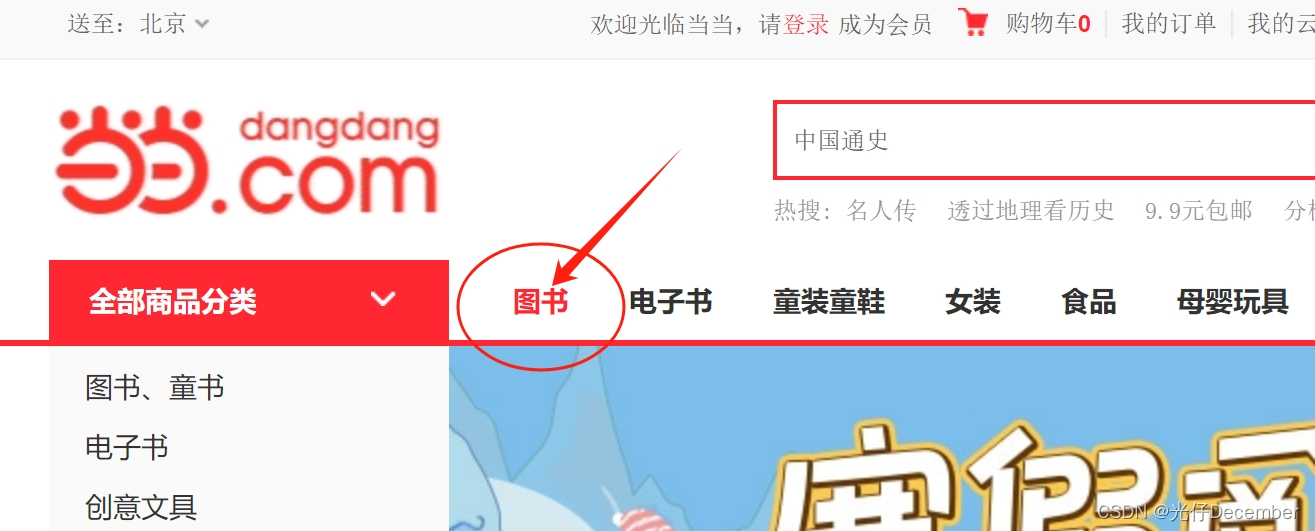
进入当当网图书分类专区首页: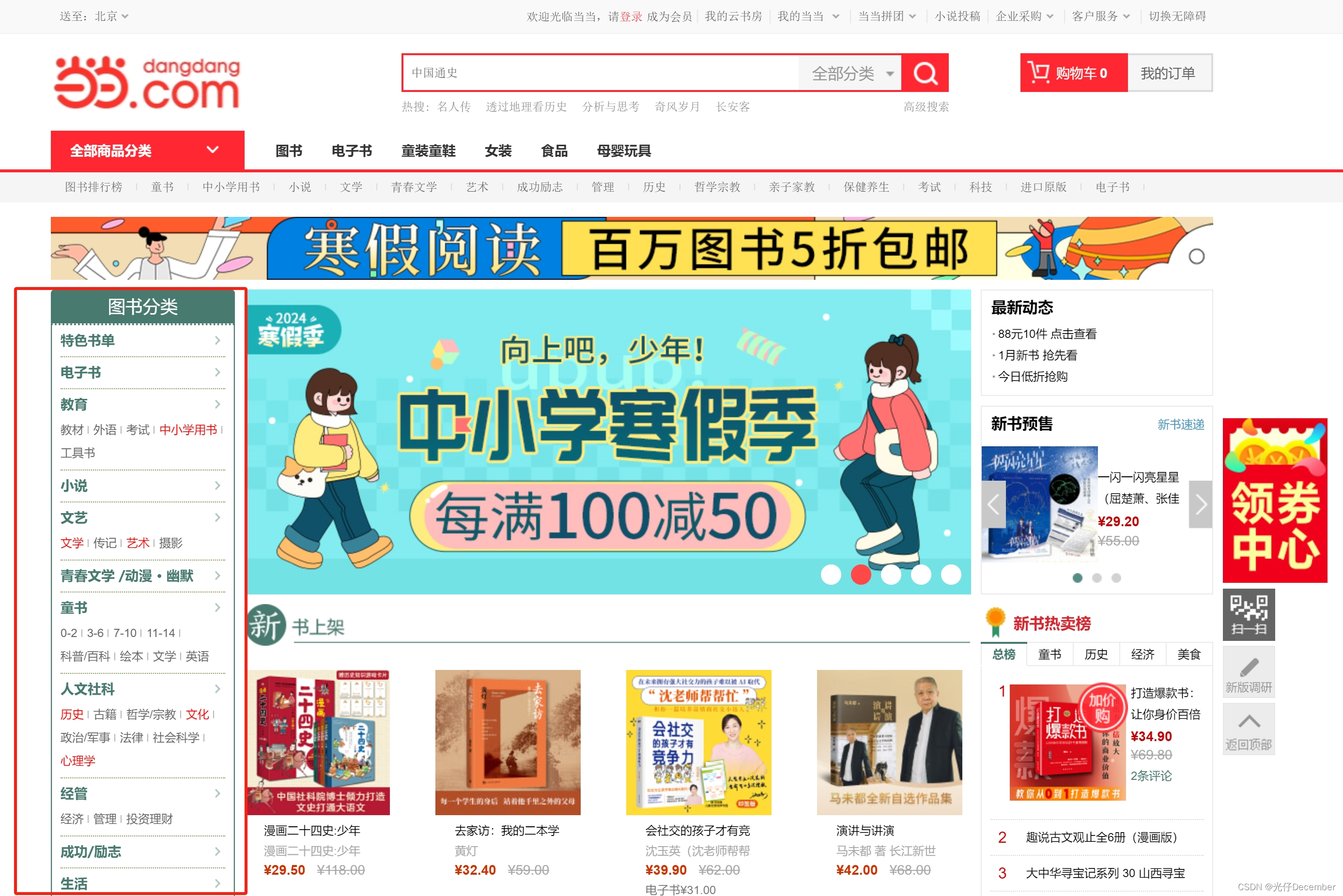
可以看到左侧有很多图书的分类。
点击其中一个最末级分类(我选择的是“一般管理类”,网址为http://category.dangdang.com/cp01.22.01.00.00.00.html),可以看到具体的图书分类列表: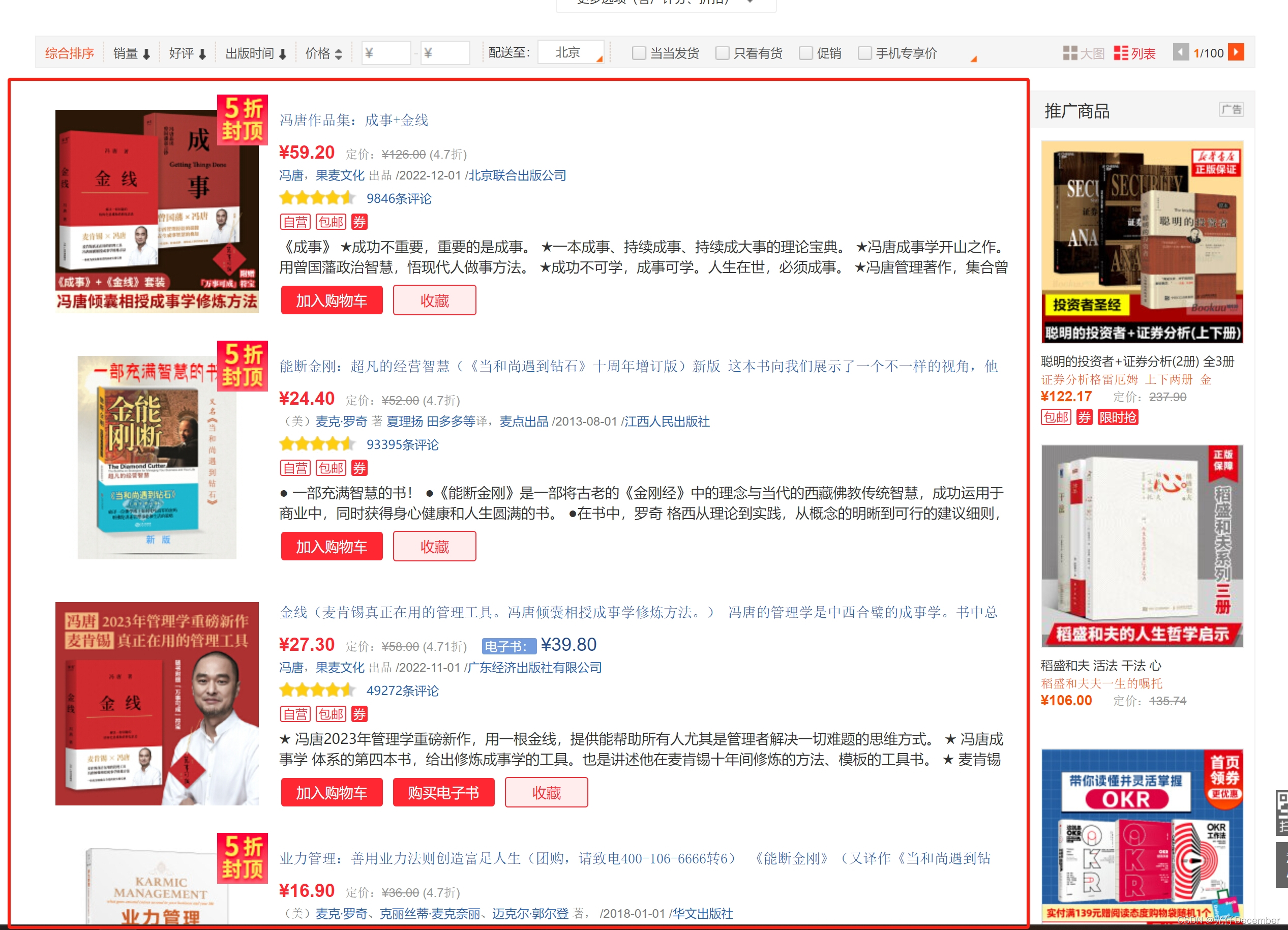
列表包含书籍图片、书籍标题、作者、出版社、评分、标签和简介等内容。拉到最下面可以看到具体的分页,默认我们在第1页,总计100页: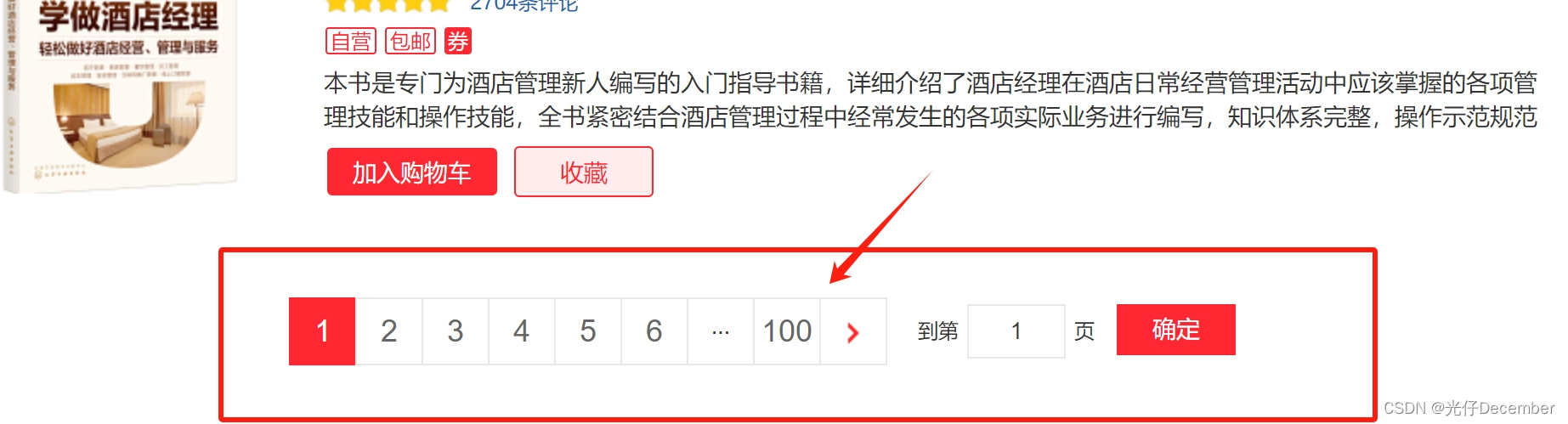
我们要做的事情,就是将这100页的全部的图书信息,给它全部抓取下来。在之前我们单独讲解爬虫的时候,可能工作量比较大,但是我们使用Scrapy框架的话,效率很高,接下来我们就进行实战。
三、创建当当网Scrapy项目
首先在工程目录下使用“scrapy startproject 项目名”指令创建项目。然后进入创建好的工程的spiders目录下,使用“scrapy genspider 爬虫名 起始url地址”指令创建一个名为“dang”的爬虫文件: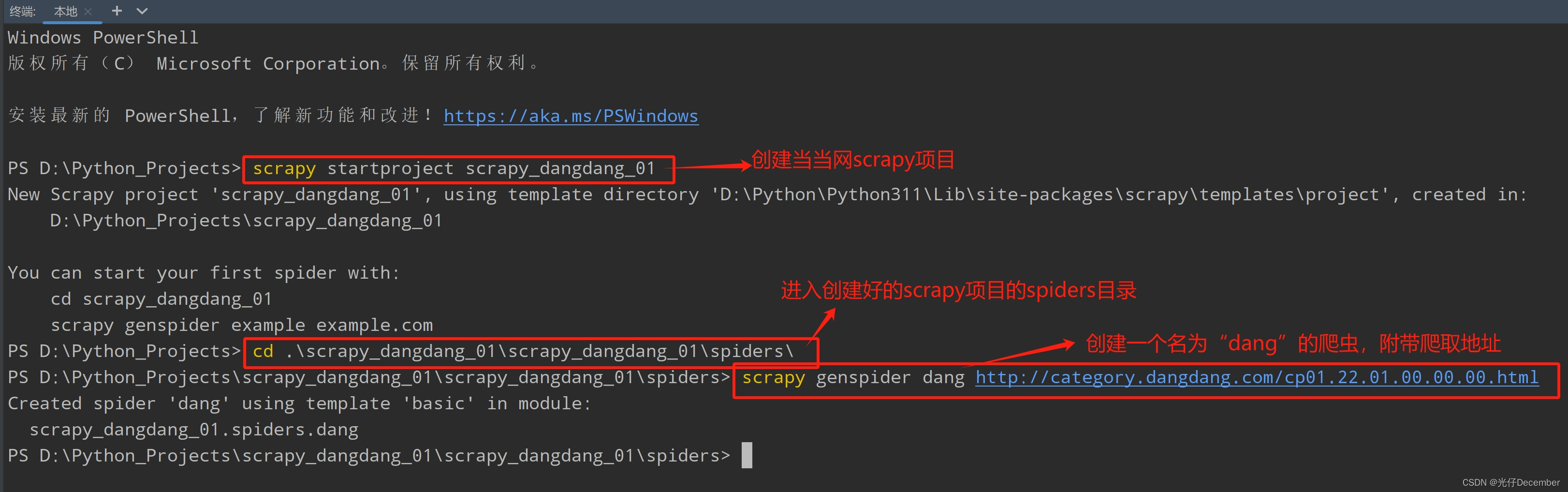
这是“dang”的爬虫文件生成的代码:
import scrapy
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["http://category.dangdang.com/cp01.22.01.00.00.00.html"]
def parse(self, response):
pass我们来校验一下这个网站有没有反爬虫校验,我们把上面的“pass”更换为“print”,打印一些等于号,看看一会能不能正常获取:
def parse(self, response):
print("========================")我们在控制台使用“scrapy crawl dang”执行爬虫,可以看到结果里包含我们打印的等于号: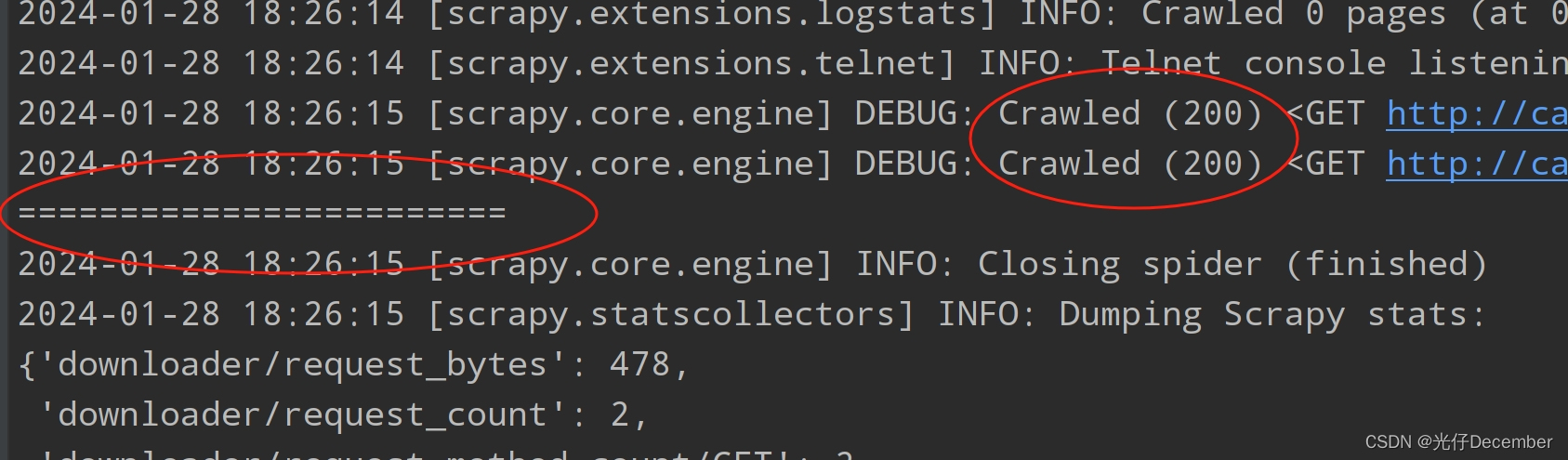
这说明网站没有反爬虫机制,我们无需调整scrapy功能的配置文件来忽略爬虫警告了。
四、编写分类图书信息获取爬虫
上面的工程以及爬虫文件创建好后,我们就来编写分类图书信息获取的爬虫逻辑。
我们再来回顾一下之前讲解的scrapy的工程项目组成:
这里面我们就会用到item、pipelines等组件类了。
1、定义item数据结构
我们打开item.py文件,来定义我们的基础数据结构,通俗的来说就是我们需要下载的数据都有什么。这里我们根据页面剖析的结果,可以看到有以下几种数据:
我们在item.py文件定义相关的数据:
import scrapy
class ScrapyDangdang01Item(scrapy.Item):
# 书籍图片
src = scrapy.Field()
# 书籍名称
title = scrapy.Field()
# 书籍作者
search_book_author = scrapy.Field()
# 书籍价格
price = scrapy.Field()
# 书籍简介
detail = scrapy.Field()2、分析spider爬取逻辑
我们分析书籍图片的地址xpath代码: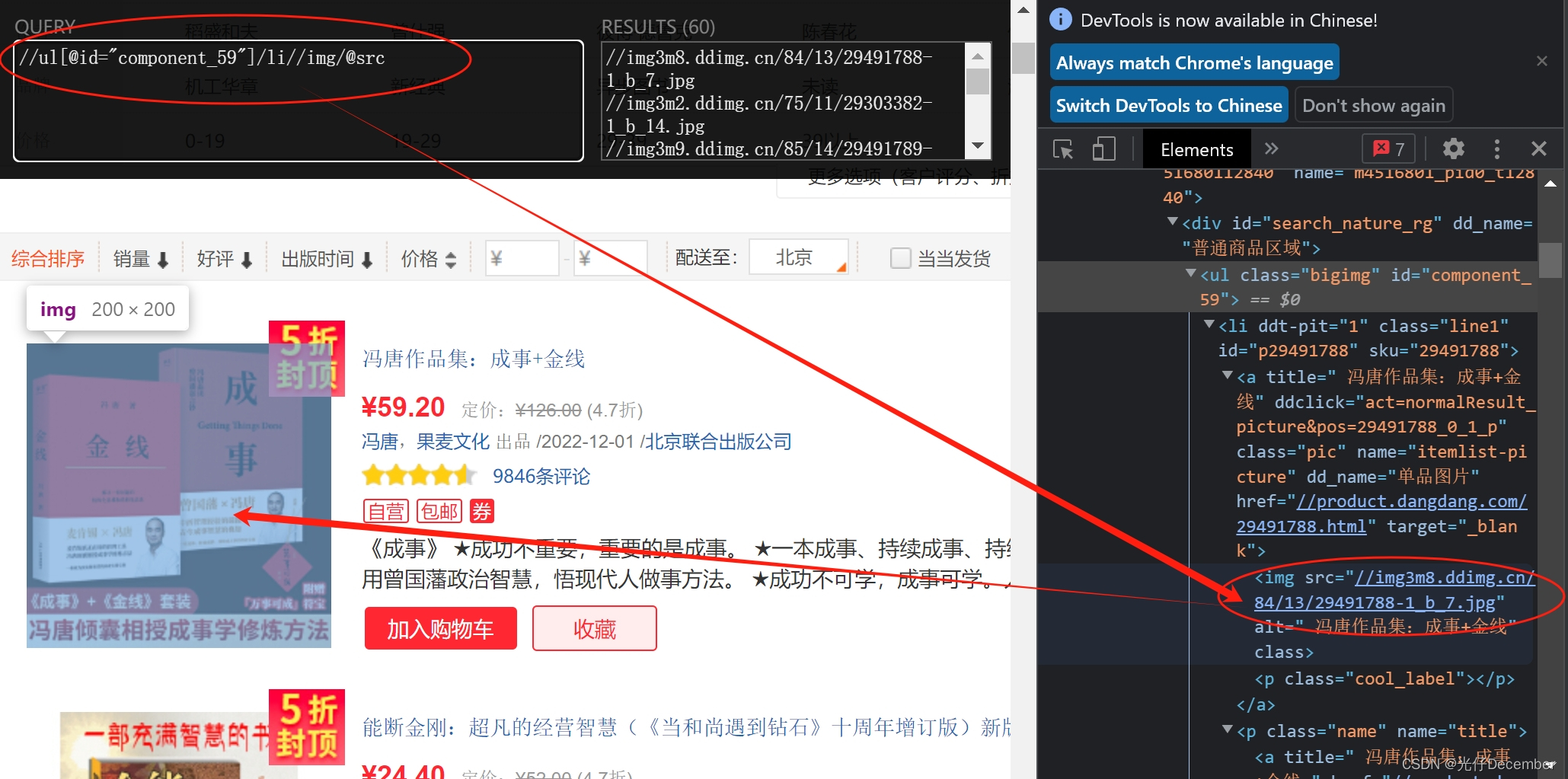
经过分析,获取每一页的所有图书的图片的xpath代码为:
//ul[@id="component_59"]/li//img/@src同样的,获取书籍名称,可以直接从img的alt属性获取,xpath代码为:
//ul[@id="component_59"]/li//img/@alt然后我们分析作者的数据: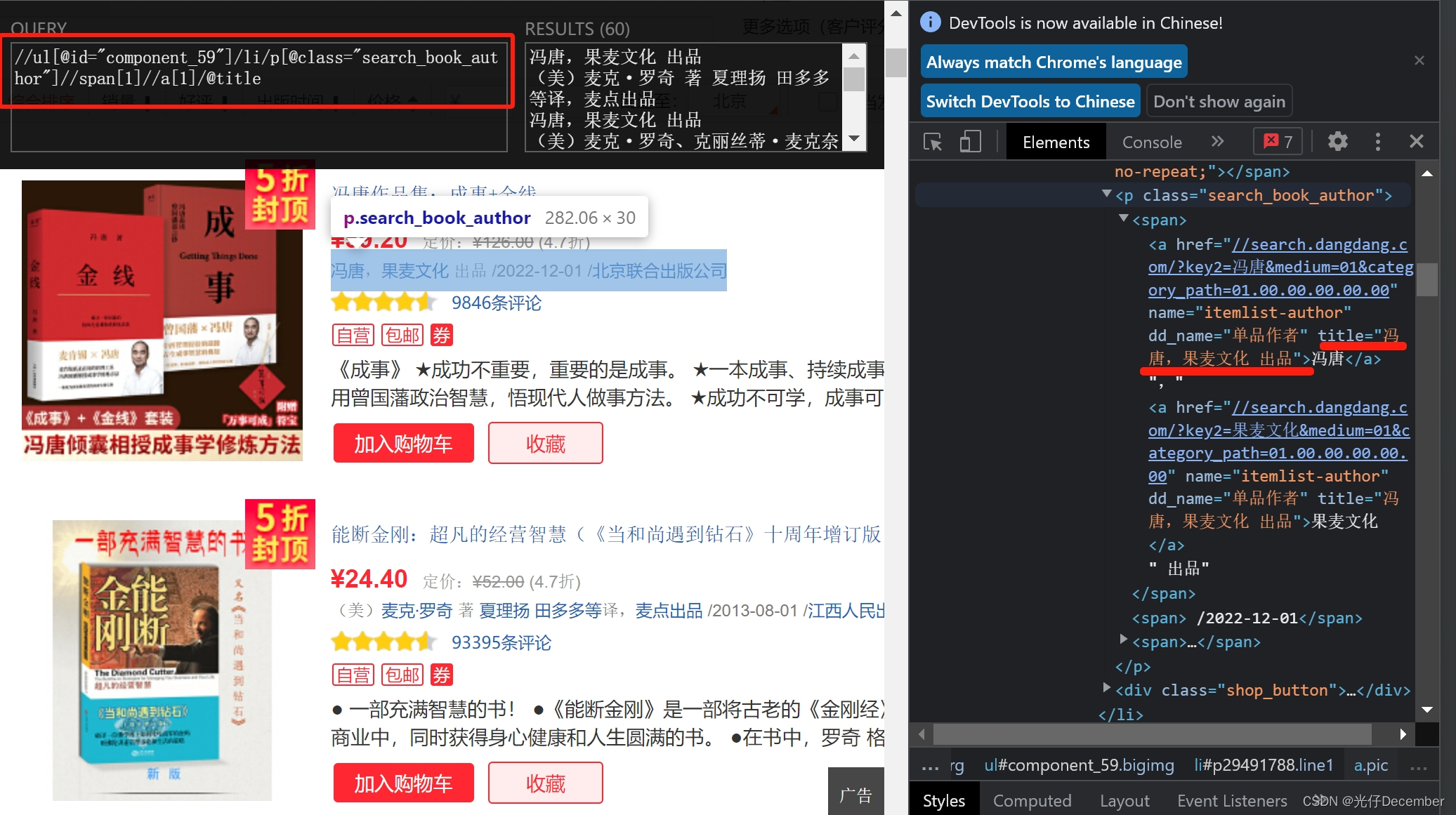
获取作者的xpath代码为:
//ul[@id="component_59"]/li/p[@class="search_book_author"]//span[1]//a[1]/@title然后我们分析价格的数据: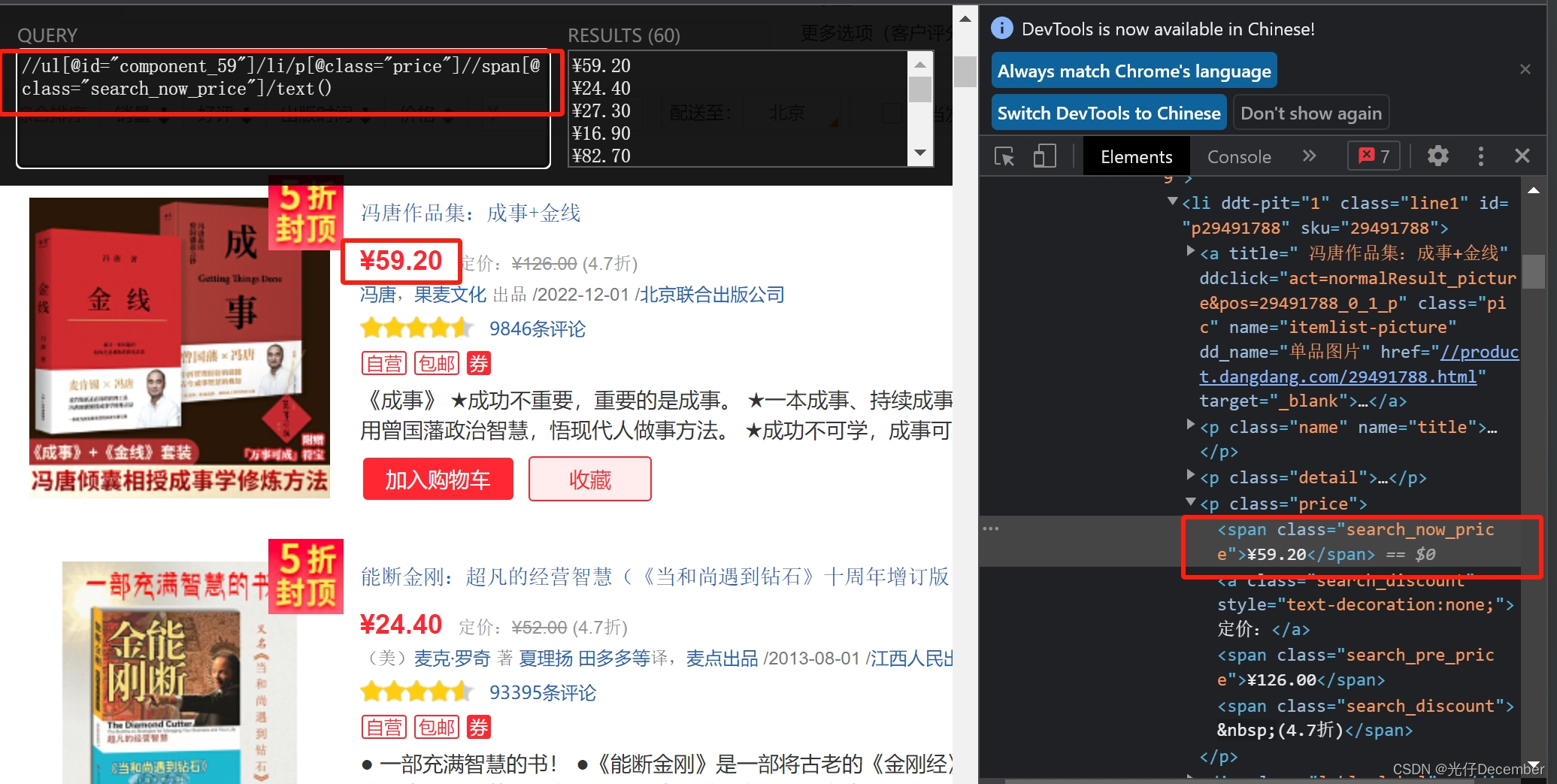
获取价格的xpath代码为:
//ul[@id="component_59"]/li/p[@class="price"]//span[@class="search_now_price"]/text()最后我们分析书籍简介的数据:
获取书籍简介的xpath代码为:
//ul[@id="component_59"]/li/p[@class="detail"]/text()3、编写spider爬虫代码
按照上面的分析,编写初步的spider爬虫代码,如下:
import scrapy
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["http://category.dangdang.com/cp01.22.01.00.00.00.html"]
def parse(self, response):
# 获取所有的图书列表对象
li_list = response.xpath('//ul[@id="component_59"]/li')
# 遍历li列表,获取每一个li元素的几个值
for li in li_list:
# 书籍图片
src = li.xpath('.//img/@src').extract_first()
# 书籍名称
title = li.xpath('.//img/@alt').extract_first()
# 书籍作者
search_book_author = li.xpath('./p[@class="search_book_author"]//span[1]//a[1]/@title').extract_first()
# 书籍价格
price = li.xpath('./p[@class="price"]//span[@class="search_now_price"]/text()').extract_first()
# 书籍简介
detail = li.xpath('./p[@class="detail"]/text()').extract_first()
print("======================")
print("【图片地址】", src)
print("【书籍标题】", title)
print("【书籍作者】", search_book_author)
print("【书籍价格】", price,)
print("【书籍简介】", detail)我们先运行爬虫打印一下,看看获取到的信息对不对: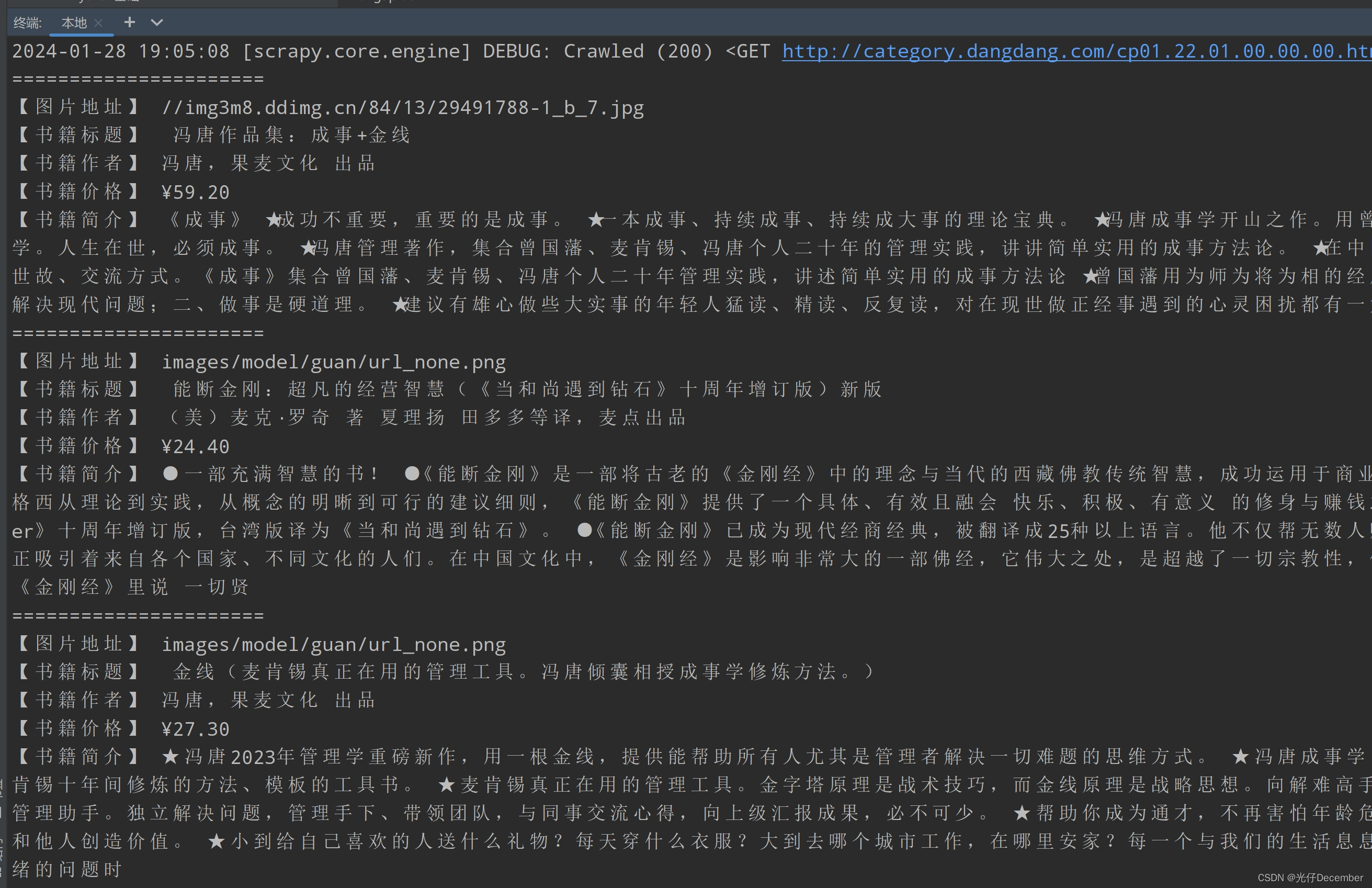
发现相关信息确实获取到了,但是我们同时也注意到了一个问题,就是书籍图片的src地址,除了第一张外,后面的地址全部是重复的,都是“ images/model/guan/url_none.png”。这是因为网页使用了懒加载功能,除了第一个图片,其他的在往下翻网页的时候,才会获取到真正的图片。
那么我们真么破除懒加载,获取真正的图片地址呢?我们去网页分析一下书籍图片的html代码:
<img data-original="//img3m9.ddimg.cn/85/14/29491789-1_b_20.jpg" src="//img3m9.ddimg.cn/85/14/29491789-1_b_20.jpg" alt=" 金线(麦肯锡真正在用的管理工具。冯唐倾囊相授成事学修炼方法。)" style="display: block;" class="">这里面的src属性,在没有往下拉网页前,里面的图片地址统一为“ images/model/guan/url_none.png”空图片,往下拉到它之后,src里面的内容才会变更为data-original中的地址(就像上面是一个已经加载过的图片,src和data-original属性的地址一样)。
所以,我们的图片地址需要更改为“data-original”属性,而不是原本的src,这样就可以破除懒加载的阻碍了:
# 书籍图片
src = li.xpath('.//img/@data-original').extract_first()此时再去看结果,真实的图片地址就有了: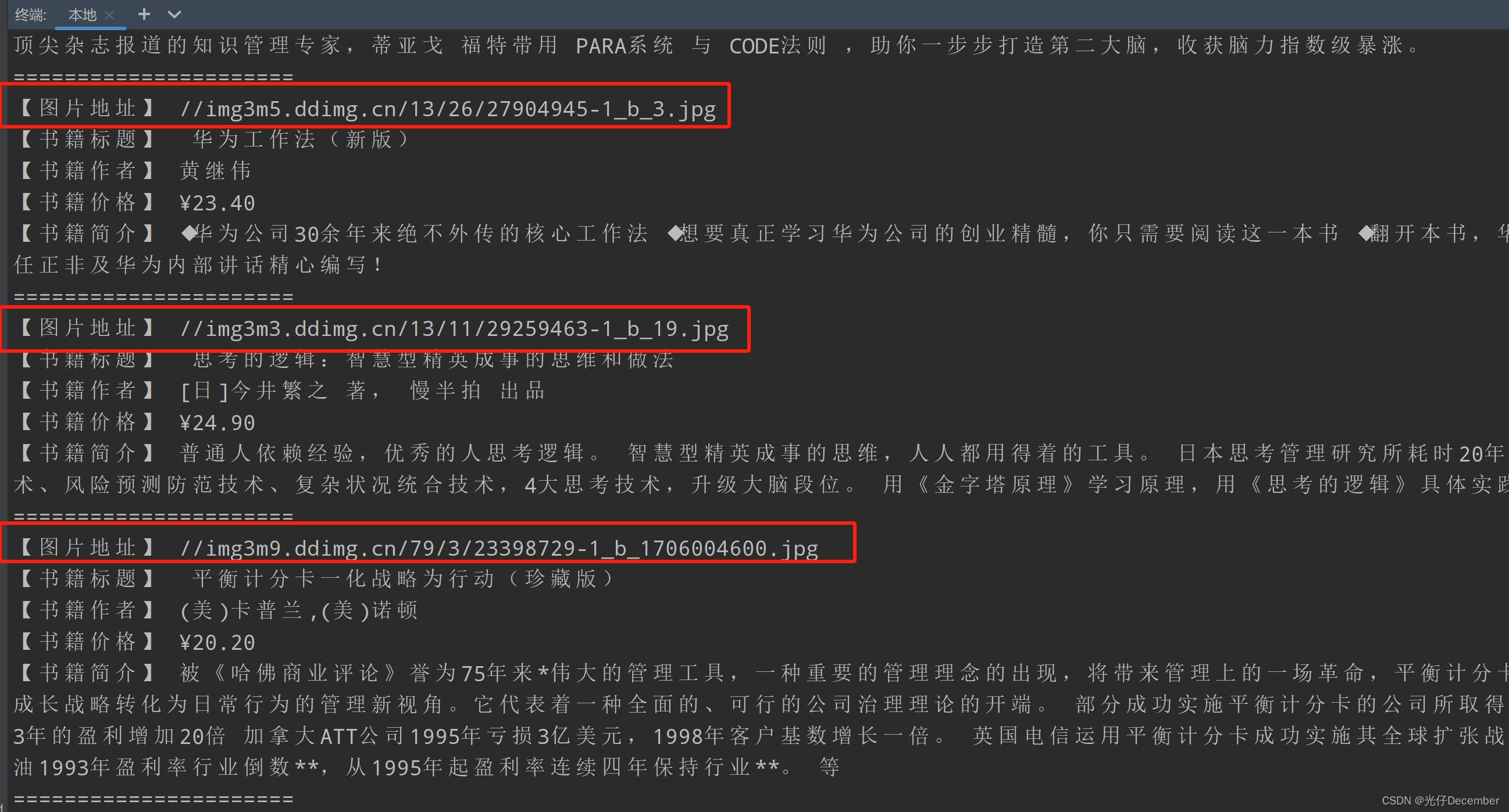
但是细心的朋友会发现,更改为“data-original”属性后,第一本书籍的图片地址就“空”了: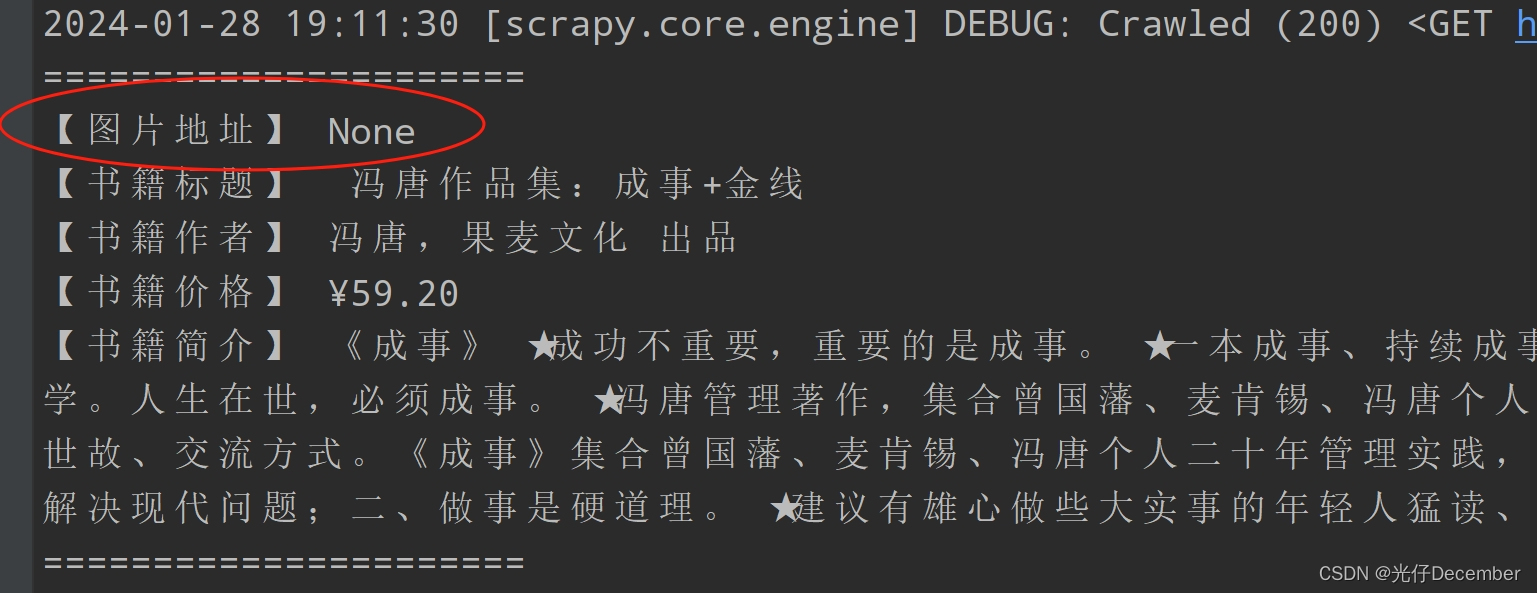
我们观察一下网页,发现第一个图书的图片信息汇总,没有“data-original”属性,只有一个src: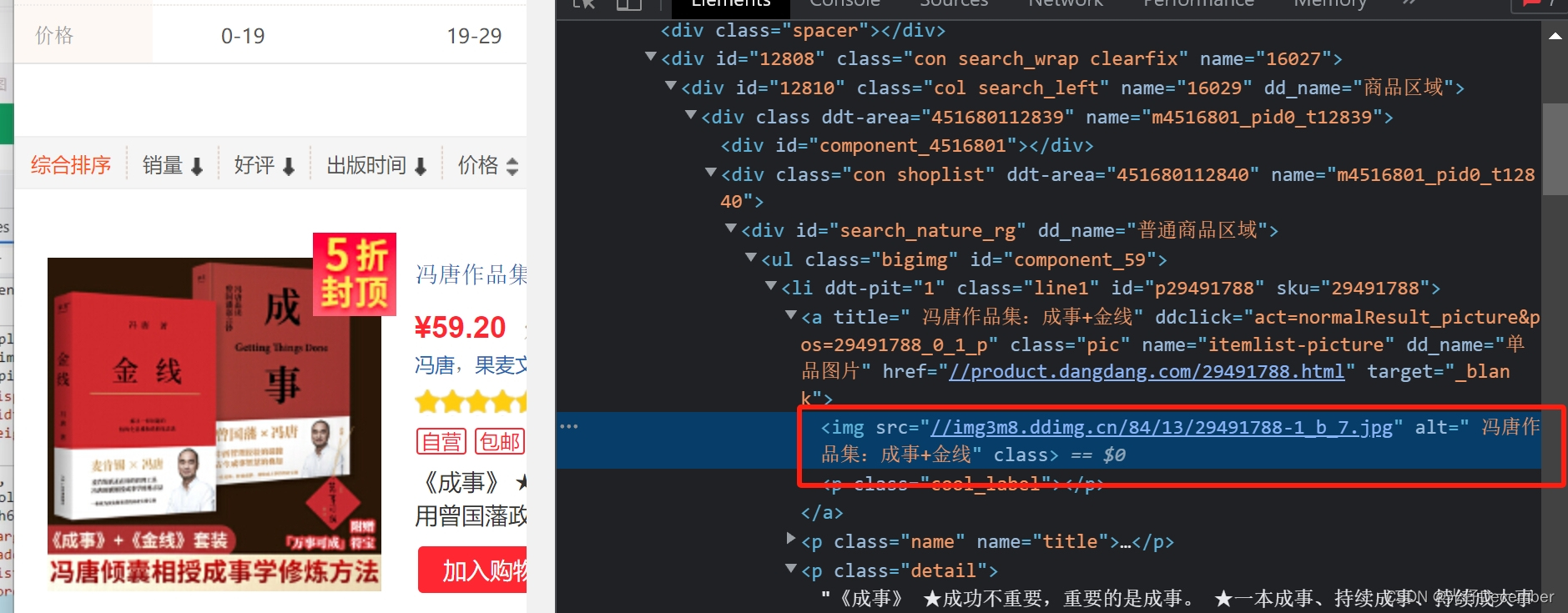
我们需要单独处理一下第一张图片的地址,代码优化如下:
# 书籍图片
src = li.xpath('.//img/@data-original').extract_first()
# 第一张图片没有@data-original属性,所以会获取到空值,此时需要获取src属性值
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()修改之后,我们重新运行爬虫,此时可以看到获取到了第一张图片及后面所有图片的地址: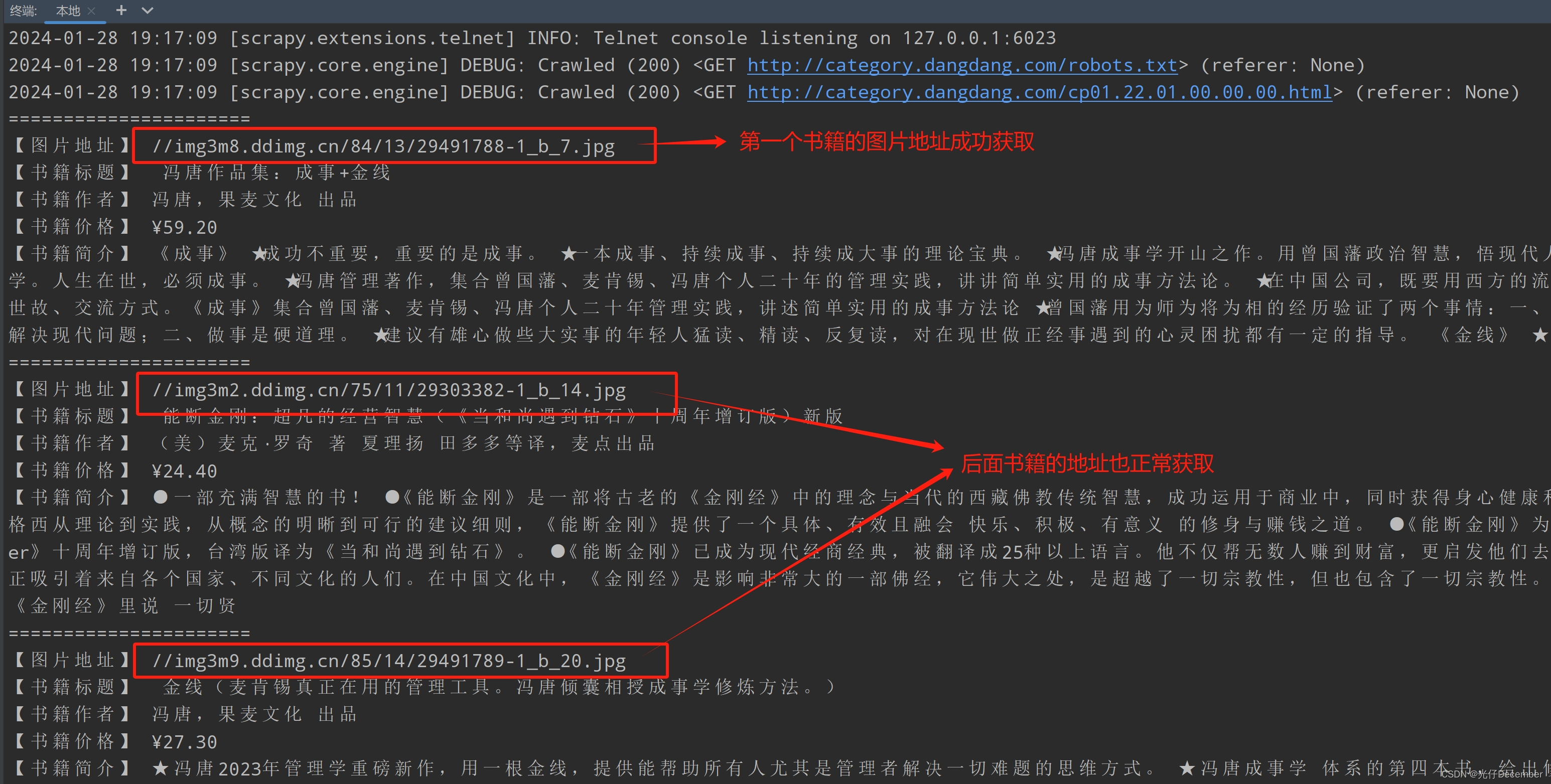
至此,第一部分就讲解完毕。下一篇我们继续编写该当当网的项目,讲解刚刚编写的Spider与item之间的关系,以及如何使用item,以及使用pipelines管道进行数据下载的操作。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/135899211



















![[论文阅读] |RAG评估_Retrieval-Augmented Generation Benchmark](https://img-blog.csdnimg.cn/direct/77abf882e4ca477fa70852e5cd7bcc7a.png)