简单爬取历史房价
需求
爬取的网站汇聚数据的城市房价
https://fangjia.gotohui.com/
功能
选择城市
https://fangjia.gotohui.com/fjdata-3
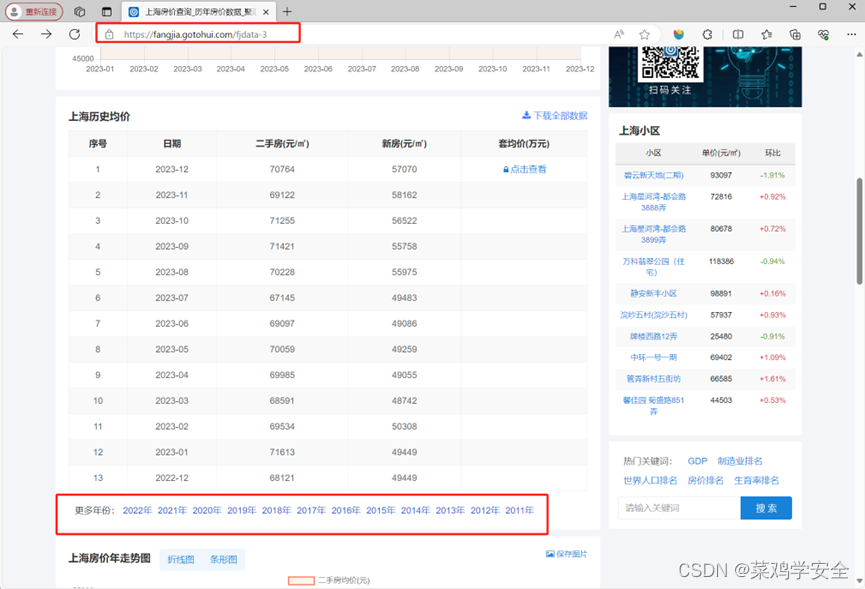
需要爬取年份的数据,等等
https://fangjia.gotohui.com/years/3/2018/
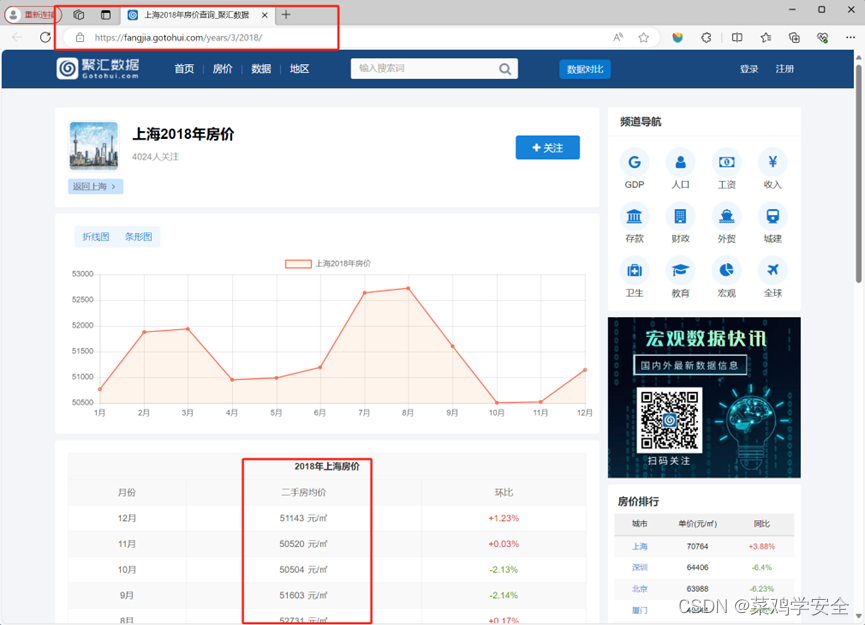
使用bs4模块
使用bs4模块快速定义需要爬取的表格
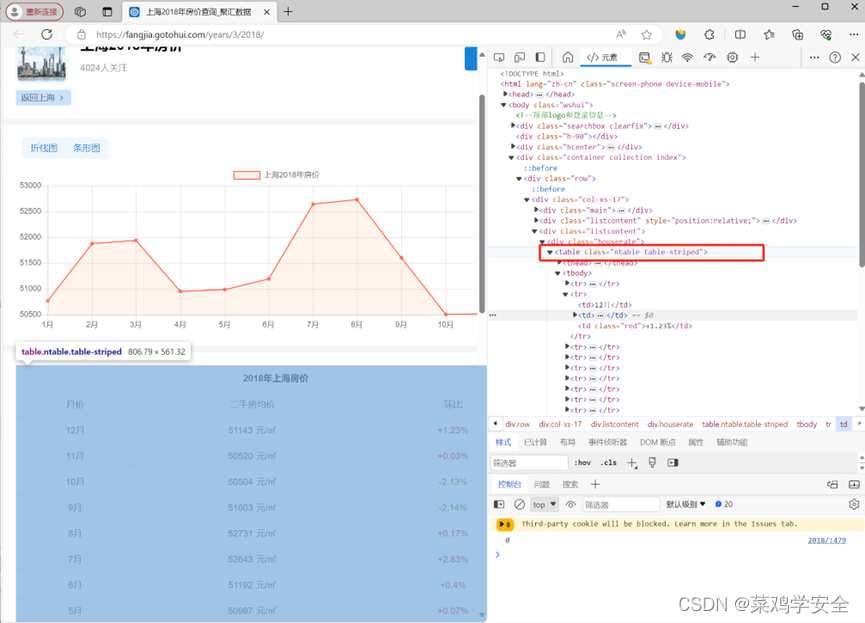
代码
from urllib.request import urlopen
import pandas as pd
from bs4 import BeautifulSoup
import urllib.request
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54'}
# 发送网络请求获取网页内容
def get_page_data(data_url, headers):
req = urllib.request.Request(data_url, headers=headers)
content = urllib.request.urlopen(req).read() # .decode('GBK')
content = content.decode('utf-8') # python3
page = BeautifulSoup(content, 'html.parser')
return page
# 按格式输出价格
def get_date(date, year):
date_str = ''
if date == '1月':
date_str = year + '-' + '01'
elif date == '2月':
date_str = year + '-' + '02'
elif date == '3月':
date_str = year + '-' + '03'
elif date == '4月':
date_str = year + '-' + '04'
elif date == '5月':
date_str = year + '-' + '05'
elif date == '6月':
date_str = year + '-' + '06'
elif date == '7月':
date_str = year + '-' + '07'
elif date == '8月':
date_str = year + '-' + '08'
elif date == '9月':
date_str = year + '-' + '09'
elif date == '10月':
date_str = year + '-' + '10'
elif date == '11月':
date_str = year + '-' + '11'
elif date == '12月':
date_str = year + '-' + '12'
return date_str
# 使用bs4内网页内容进行提取
def analyse_data(page, year):
table = page.find('table', attrs={
'class': 'ntable table-striped'})
trs = table.find_all('tr')[3:]
df_data = pd.DataFrame(columns=['date', 'price'])
time.sleep(1)
count = 0
for tr in trs:
tds = tr.find_all('td')
date = tds[0].text
date = get_date(date,year)
new = tds[1].text
new = new[:6]
df_data.loc[count] = [date, new]
count += 1
return df_data
if __name__ == '__main__':
data_url = 'https://fangjia.gotohui.com/fjdata-3'
year = ['2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022', '2023']
all_datas = []
file_path = "data.txt"
# 遍历多年的数据
for i in year:
url = 'https://fangjia.gotohui.com/years/3/' + i + '/'
page = get_page_data(url, headers)
df_data = analyse_data(page, i)
print(df_data)
# 将数据保存到txt文件文件中,(存在编码问题后续解决)
df_data1 = str(df_data)
with open(file_path, 'a',encoding='utf-8') as file:
file.write(df_data1)
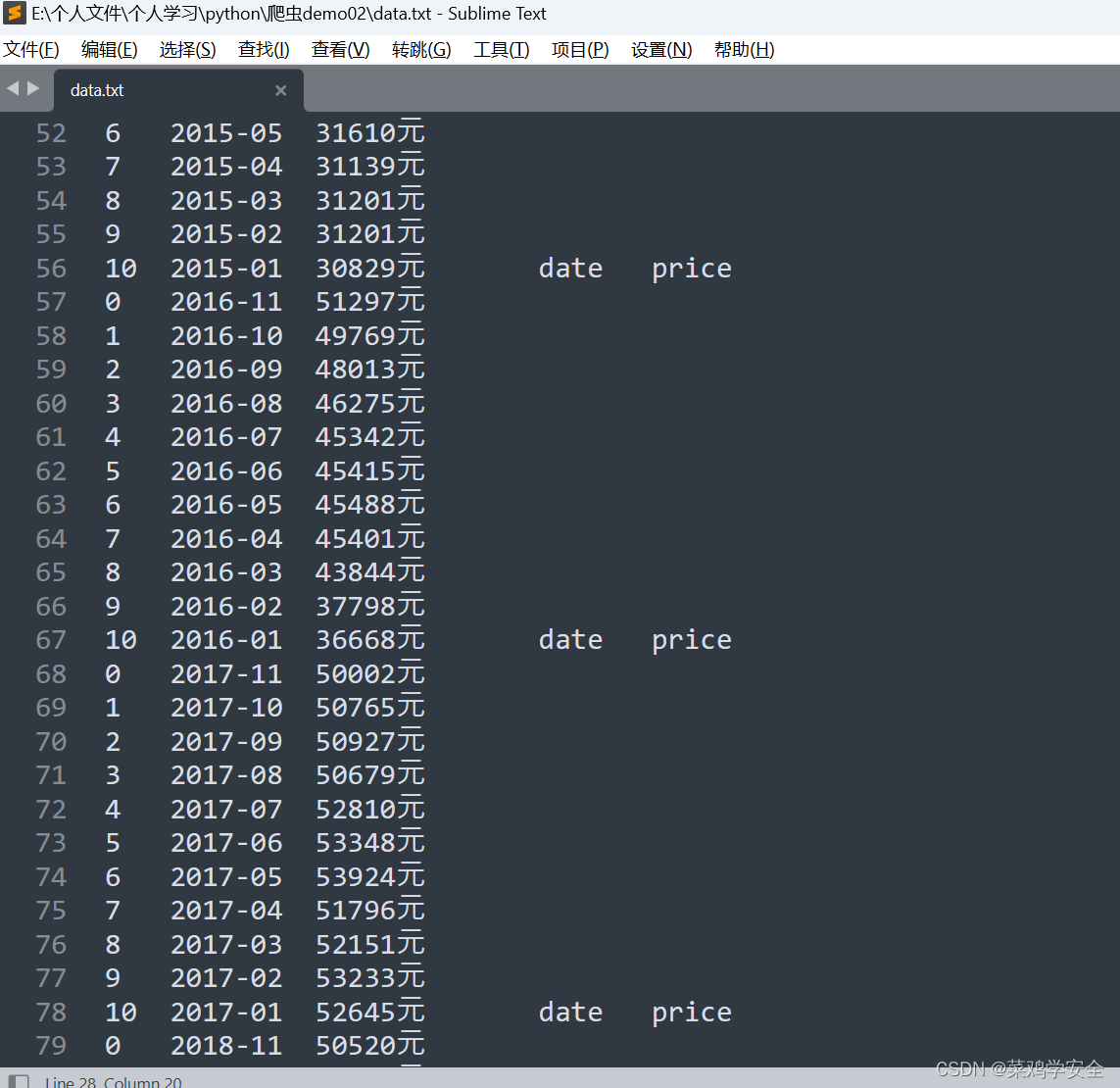
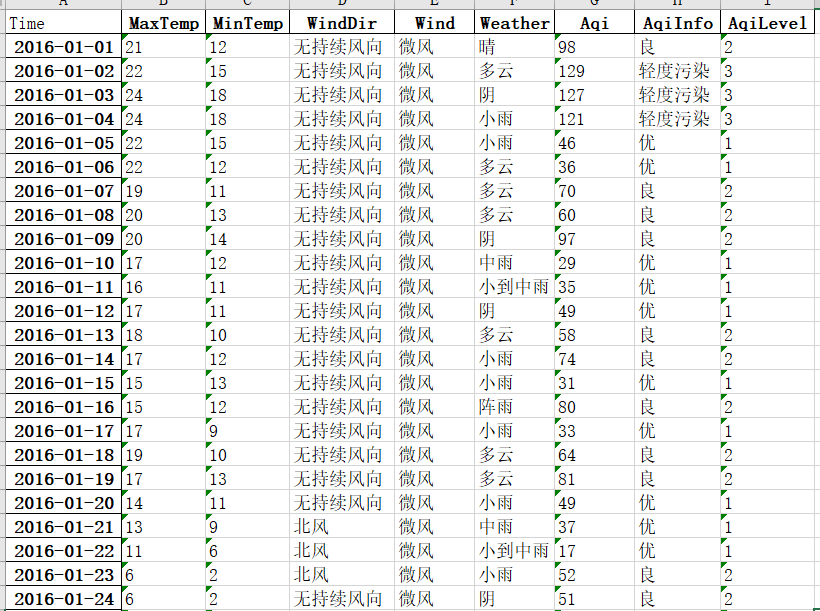
运行效果
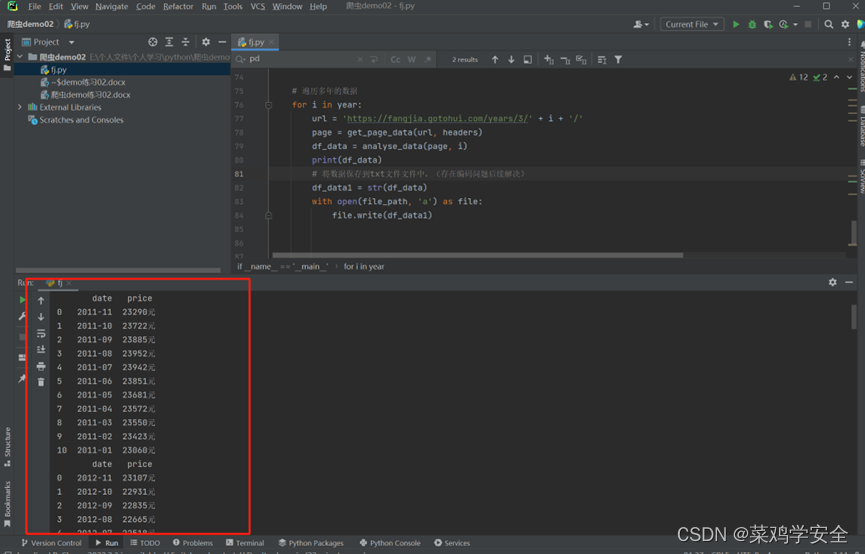
保存到文件































![[BUUCTF 2018]Online Tool(特详解)](https://img-blog.csdnimg.cn/direct/4ea1ffb76cd94d458d5cecace4964d3a.png)

