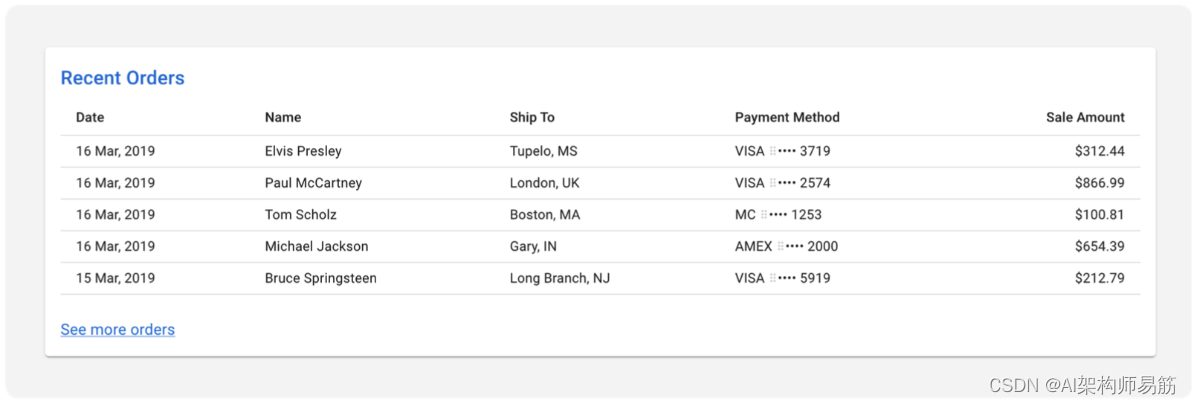
Using MPI with C
并行程序使用户能够充分利用超级计算集群的多节点结构。消息传递接口 (MPI) 是一种标准,用于允许集群上的多个不同处理器相互通信。在本教程中,我们将使用英特尔 C++ 编译器、GCC、IntelMPI 和 OpenMPI 用 C++ 创建多处理器“hello world”程序。本教程假设用户具有 Linux 终端和 C++ 经验。
Setup and “Hello, World”
这应该为您的环境准备好编译和运行 MPI 代码所需的所有工具。现在让我们开始构建我们的 C++ 文件。在本教程中,我们将命名我们的代码文件:hello_world_mpi.cpp
打开 hello_world_mpi.cpp 并首先包含 C 标准库 <stdio.h> 和 MPI 库 <mpi.h> ,并构建 C++ 代码的 main 函数:
#include <stdio.h>
#include <mpi.h>
int main(int argc, char** argv){
return 0;
}
现在让我们设置几个 MPI 指令来并行化我们的代码。在这个“Hello World”教程中,我们将使用以下四个指令:
- MPI_Init():
该函数初始化 MPI 环境。它接收 C++ 命令行参数 argc 和 argv 的地址。
- MPI_Comm_size():
此函数通过进程数量返回环境的总大小。该函数接受 MPI 环境和整型变量的内存地址。
- MPI_Comm_rank():
该函数返回调用该函数的处理器的进程ID。该函数接受 MPI 环境和整型变量的内存地址。
- MPI_Finalize():
该函数清理 MPI 环境并结束 MPI 通信。
这四个指令应该足以让我们的并行“hello world”运行。我们将首先创建两个变量 process_Rank 和 size_Of_Cluster,分别存储每个并行进程的标识符和集群中运行的进程数。我们还将实现 MPI_Init 函数,该函数将初始化 mpi 通信器:
#include <stdio.h>
#include <mpi.h>
int main(int argc, char** argv){
int process_Rank, size_Of_Cluster
MPI_Init(&argc, &argv);
return 0;
}
现在让我们获取有关处理器集群的一些信息并为用户打印该信息。我们将使用函数 MPI_Comm_size() 和 MPI_Comm_rank() 分别获取进程计数和进程排名:
#include <stdio.h>
#include <mpi.h>
int main(int argc, char** argv){
int process_Rank, size_Of_Cluster;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size_Of_Cluster);
MPI_Comm_rank(MPI_COMM_WORLD, &process_Rank);
printf("Hello World from process %d of %d\n", process_Rank, size_Of_Cluster);
return 0;
}
最后让我们使用 MPI_Finalize() 关闭环境:
#include <stdio.h>
#include <mpi.h>
int main(int argc, char** argv){
int process_Rank, size_Of_Cluster;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size_Of_Cluster);
MPI_Comm_rank(MPI_COMM_WORLD, &process_Rank);
printf("Hello World from process %d of %d\n", process_Rank, size_Of_Cluster);
MPI_Finalize();
return 0;
}
现在代码已经完成并可以编译了。因为这是一个MPI程序,所以我们必须使用专门的编译器。请务必根据您加载的编译器使用正确的命令。
OpenMPI
mpic++ hello_world_mpi.cpp -o hello_world_mpi.exe
这将生成一个可执行文件,我们可以将其作为作业传递给集群。为了执行 MPI 编译代码,必须使用特殊命令:
mpirun -np 4 ./hello_world_mpi.exe
标志 -np 指定在执行程序时要使用的处理器数量。
在作业脚本中,加载上面用于编译程序的相同编译器和 OpenMPI 选择,并使用 Slurm 运行作业以执行应用程序。您的作业脚本应如下所示:
OpenMPI
#!/bin/bash
#SBATCH -N 1
#SBATCH --ntasks 4
#SBATCH --job-name parallel_hello
#SBATCH --constraint ib
#SBATCH --partition atesting
#SBATCH --time 0:01:00
#SBATCH --output parallel_hello_world.out
module purge
module load gcc
module load openmpi
mpirun -np 4 ./hello_world_mpi.exe
重要的是要注意,在AIpine,每个节点共有64个核心。对于需要超过64个流程的应用程序,您需要在工作中要求多个节点。我们的输出文件应该看起来像这样:
Hello World from process 3 of 4
Hello World from process 2 of 4
Hello World from process 1 of 4
Hello World from process 0 of 4





















![[嵌入式软件][启蒙篇][仿真平台] STM32F103实现SPI控制OLED屏幕](https://img-blog.csdnimg.cn/direct/928e1eaef4bc4be2a007da5a70fe7df6.png)