参考链接:
https://blog.csdn.net/haveanybody/article/details/113092851
https://www.jianshu.com/p/dd6ce77bfb8a
1 介绍
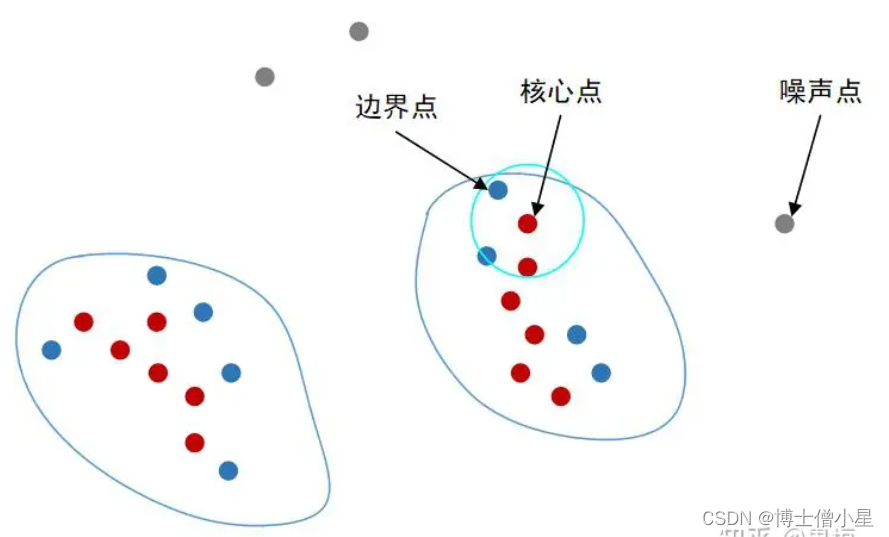
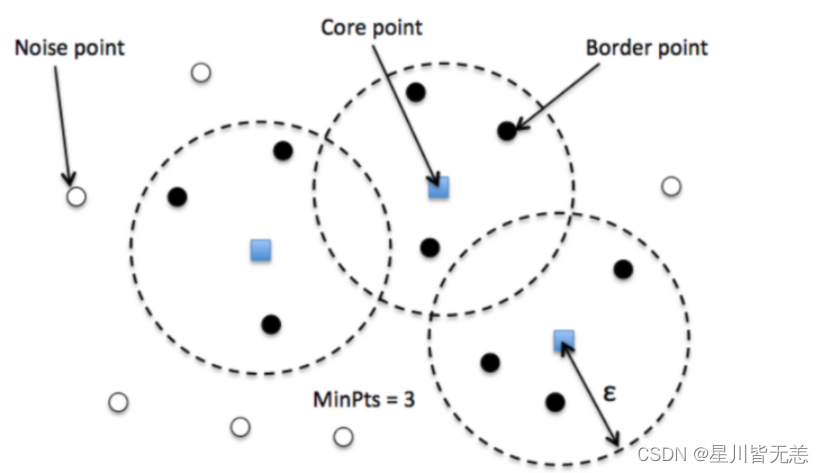
DBSCAN(Density-Based Spatial Clustering of Applica tion with Noise)算法是于1996年提出的一种简单的、有效的基于密度的聚类算法,该算法利用类的密度连通性快速发现任意形状的类。该算法的中心思想是:对于一个类中的每一个点P(不包括边界点),在给定的某个Eps邻域内数据点的个数不少于Minpts。
DBSCAN算法不属于图聚类算法。图聚类算法是一种基于图结构的聚类算法,它利用图中的顶点和边的信息来划分聚类。DBSCAN算法不需要构建图结构,它只需要计算数据点之间的距离,然后根据密度阈值和邻域半径来判断数据点是否属于某个聚类。
DBSCAN算法的主要优点是:
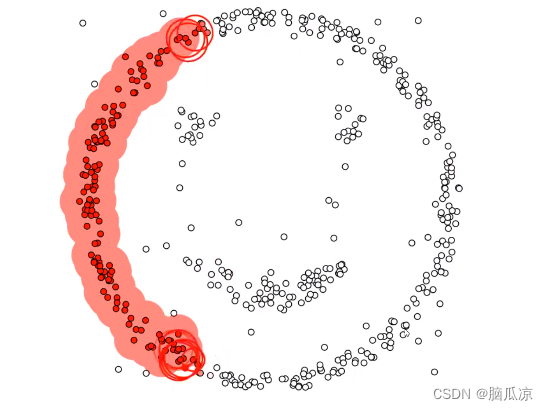
- 它可以发现任意形状的聚类,而不是像K-means算法那样只能发现球形的聚类。
- 它可以识别噪声点,并将它们从聚类中排除,而不是像层次聚类算法那样将所有的数据点都分配到某个聚类中。
- 它不需要事先指定聚类的个数,而是根据数据的密度自动确定聚类的个数。
DBSCAN算法的主要缺点是:
- 它对密度阈值和邻域半径的选择非常敏感,不同的参数设置可能导致不同的聚类结果。
- 它对高维数据的处理效果不佳,因为高维空间中的距离计算很难反映数据的真实相似度。
- 它对不同密度的聚类的划分效果不佳,因为它使用的是全局的密度阈值,而不是针对每个聚类的局部密度阈值。
2 代码
2.1 直接调用sklearn的接口
本小节最后会给出完整代码,在这之前,先对代码中出现的一些关键点做一个简单的笔记:
2.1.1 数据标准化方法
# 生成包含750个样本的聚类数据集,其中每个样本属于上述三个中心之一,cluster_std 控制聚类的标准差
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0)
X = StandardScaler().fit_transform(X) # 对样本数据进行标准化处理,确保每个特征的均值为0,标准差为1
# X = MinMaxScaler().fit_transform(X) # 对数据进行归一化处理
数据预处理方法有很多,像常用的标准化、归一化、特征工程之类,这里主要介绍一下标准化和归一化。
标准化处理通常是为了确保不同特征的尺度一致,使得模型更容易收敛并提高算法的性能。虽然标准化处理在大多数情况下是有益的,但对于不规则数据(如存在极端离群值或不符合正态分布的数据),有时候可能需要谨慎处理。
对于不规则数据,可以考虑使用其他数据预处理方法,例如:
- 归一化(Normalization): 将数据缩放到一个固定的范围,例如 [0, 1]。这对于受极端值影响较大的情况可能更合适。
- RobustScaler: 该方法对数据中的离群值具有鲁棒性,因此在存在离群值的情况下可能更适用。
- 特征工程: 根据数据的特点进行定制的特征变换,以满足特定的数据分布。
最终选择哪种预处理方法取决于数据的性质和模型的需求。在处理不规则数据时,建议进行实验比较不同的方法,以找到最适合特定数据集的预处理策略。
归一化(Normalization)和标准化(Standardization)是两种不同的数据缩放方法,尽管它们的目标都是使得特征在数值上更一致,但采用的处理方式略有不同。
归一化: 归一化的目标是将数据缩放到一个固定的范围,通常是 [0, 1]。最常见的归一化方法是使用最小-最大缩放,公式为:
X normalized = X − X min X max − X min X_{\text{normalized}} = \frac{X - X_{\text{min}}}{X_{\text{max}} - X_{\text{min}}} Xnormalized=Xmax−XminX−Xmin
这确保了所有特征的值都在 0 到 1 之间。
标准化: 标准化的目标是使得数据的分布具有标准正态分布的特性,即均值为 0,标准差为 1。最常见的标准化方法是使用 Z 分数标准化,公式为:
X standardized = X − μ σ X_{\text{standardized}} = \frac{X - \mu}{\sigma} Xstandardized=σX−μ
其中 (\mu) 是均值,(\sigma) 是标准差。标准化处理后的数据集具有均值为 0,标准差为 1 的性质。
虽然这两种方法有不同的数学表达式,但它们的目的都是为了处理不同尺度的特征,使得模型更容易学习和收敛。选择使用归一化还是标准化通常取决于具体的任务和数据集的特点。
需要注意的是,在本文的示例代码中,直接将X = StandardScaler().fit_transform(X)换成X = MinMaxScaler().fit_transform(X)最后计算轮廓系数的时候会报错:ValueError: Number of labels is 1. Valid values are 2 to n_samples - 1 (inclusive),为啥我目前也还不知道,有知道的好兄弟记得评论区踢我。
2.1.2 算法评估指标
当对聚类结果进行评估时,这些指标提供了关于聚类性能的不同方面的信息:
- 同质性(Homogeneity): 衡量每个聚类中的成员是否都属于同一类别。同质性得分越高,表示聚类结果越好。
- 完整性(Completeness): 度量是否找到了每个真实类别的所有成员。完整性得分越高,表示聚类结果越完整。
- V-measure: 同质性和完整性的调和平均,提供了对聚类结果的整体评估。
- 调整兰德指数(Adjusted Rand Index): 用于度量聚类结果与真实标签之间的相似性,接近 1 表示较高的相似性。
- 调整互信息(Adjusted Mutual Information): 度量聚类结果与真实标签之间的信息一致性。
- 轮廓系数(Silhouette Coefficient): 用于度量聚类结果的紧密性和分离性,值越接近 1 表示聚类结果越好。
DBSCAN是一种无监督聚类算法,它不要求输入数据包含真实标签。在正常的使用情况下,DBSCAN 是无需真实标签的。然而,在示例代码中,labels_true 是提供的真实标签,主要是用于验证聚类算法的性能,以评估聚类结果与真实标签之间的相似性。
通常情况下,对于无监督聚类算法,我们在实际应用中不知道数据的真实标签,因此评估聚类算法的性能时使用的是无监督的内部评估指标,如轮廓系数、Calinski-Harabasz指数、DB指数等,它们不依赖于真实标签。这些指标可以在没有真实标签的情况下,通过对聚类结果自身进行评估,提供一些关于聚类质量的信息。
- Calinski-Harabasz指数
Calinski-Harabasz指数(也称为方差比标准)是一种用于评估聚类结果的有效性的指标。它通过计算簇内的离散度与簇间的分离度之间的比率来度量聚类的紧密度和分离度。指数值越高,表示聚类效果越好。
具体计算方式为:
Calinski-Harabasz指数 = 簇间离散度 簇内离散度 × 样本数量 − 簇数量 簇数量 − 1 \text{Calinski-Harabasz指数} = \frac{\text{簇间离散度}}{\text{簇内离散度}} \times \frac{\text{样本数量} - \text{簇数量}}{\text{簇数量} - 1} Calinski-Harabasz指数=簇内离散度簇间离散度×簇数量−1样本数量−簇数量
其中,簇内离散度是各个簇内样本与其簇内均值的距离的总和,簇间离散度是所有簇中心与数据整体均值的距离的总和。
Calinski-Harabasz指数越高,表示簇间的分离度较高,簇内的离散度较低,聚类效果越好。
在 scikit-learn 中,可以使用 metrics.calinski_harabasz_score 函数来计算Calinski-Harabasz指数。例如:
from sklearn import metrics
calinski_harabasz_score = metrics.calinski_harabasz_score(X, labels)
print("Calinski-Harabasz指数:%0.3f" % calinski_harabasz_score)
- DB指数
对于密度聚类算法(如DBSCAN),DB指数(Davies-Bouldin指数)是一种用于评估聚类结果的指标。DB指数考虑了簇的紧密度和分离度,越小的值表示聚类结果越好。
DB指数的计算方式是对每个簇,计算该簇内每个点与簇内其他点的平均距离(紧密度),然后找到与该簇最近的其他簇,计算两个簇中心的距离(分离度)。DB指数是紧密度与分离度的加权平均值,公式如下:
D B = 1 k ∑ i = 1 k max j ≠ i ( S i + S j d ( C i , C j ) ) DB = \frac{1}{k} \sum_{i=1}^{k} \max_{j \neq i} \left( \frac{S_i + S_j}{d(C_i, C_j)} \right) DB=k1i=1∑kj=imax(d(Ci,Cj)Si+Sj)
其中:
- (k) 是簇的数量。
- (S_i) 是簇内点到簇中心的平均距离。
- (d(C_i, C_j)) 是簇中心之间的距离。
DB指数的优点是越小越好,表示簇内紧密度越高,簇间分离度越好。但请注意,DB指数的计算也涉及到对距离的定义,这在密度聚类中可能涉及到一些具体的选择。
在 scikit-learn 中,可以使用 metrics.davies_bouldin_score 函数来计算DB指数。例如:
from sklearn import metrics
db_score = metrics.davies_bouldin_score(X, labels)
print("DB指数:%0.3f" % db_score)
DB指数是一种适用于密度聚类算法的评估指标,对于不同形状和大小的簇都比较稳健。
在计算DB指数时,涉及到对距离的定义,特别是在密度聚类中,选择距离的度量方式可能会影响DB指数的计算结果。通常来说,DB指数的计算可以使用不同的距离度量方法,其中 Euclidean 距离是最常见的选择。
在 scikit-learn 中,默认的距离度量方式通常是 Euclidean 距离,因为 Euclidean 距离在许多情况下都是一种合理的选择。然而,对于一些特定的密度聚类场景,也可以考虑使用其他距离度量方法,例如 Mahalanobis 距离,特别是当数据具有不同的方差和协方差结构时。
在使用 metrics.davies_bouldin_score 函数计算DB指数时,你可以通过传递 metric 参数来指定距离度量方式。例如,使用 Mahalanobis 距离:
from sklearn import metrics
from scipy.spatial.distance import mahalanobis
# 自定义 Mahalanobis 距离的度量方式
def mahalanobis_distance(X, Y):
# 在这里实现 Mahalanobis 距离的计算方式
# ...
# 计算DB指数,使用 Mahalanobis 距离
db_score = metrics.davies_bouldin_score(X, labels, metric=mahalanobis_distance)
print("DB指数:%0.3f" % db_score)
需要注意的是,Mahalanobis 距离的计算需要对每个簇内的协方差矩阵进行估计,这可能会增加计算的复杂性。选择合适的距离度量方式应该根据具体的数据特点和任务需求来进行。
- 轮廓系数
轮廓系数(Silhouette Coefficient)是一种用于评估聚类结果好坏的指标,它结合了簇内的紧密度和簇间的分离度。轮廓系数的取值范围在 [-1, 1] 之间,具体定义如下:
对于每个样本:
- 计算该样本与同簇内其他样本的平均距离,记为 (a)(簇内紧密度)。
- 计算该样本与最近的其他簇中所有样本的平均距离,记为 (b)(簇间分离度)。
- 轮廓系数 (s) 的计算方式为 ( b − a ) / max ( a , b ) (b - a) / \max(a, b) (b−a)/max(a,b)。
对于整个数据集,轮廓系数是所有样本轮廓系数的平均值。
轮廓系数的解释:
- 轮廓系数接近1表示簇内样本距离紧密,簇间样本距离相对较远,聚类效果较好。
- 轮廓系数接近0表示簇内样本距离和簇间样本距离相近,表明聚类结果不清晰。
- 轮廓系数接近-1表示簇内样本距离松散,簇间样本距离较近,聚类效果差。
轮廓系数可以用于选择合适的聚类数目,因为它在聚类数目选择上的峰值通常对应于较好的聚类结果。在使用轮廓系数时,需要注意对于某些不适合聚类的数据集,轮廓系数可能并不是一个有效的指标。
2.1.3 绘图颜色
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
这行代码用于生成一组颜色,以便在可视化中为不同的聚类标签选择不同的颜色。
np.linspace(0, 1, len(unique_labels)): 生成一个从 0 到 1 的等差数列,数列的长度与聚类标签的数量相同。这个数列将用于确定颜色映射的位置,确保每个聚类标签都有一个对应的颜色。plt.cm.Spectral(each): 使用Spectral颜色映射,根据上面生成的等差数列中的每个值,获取相应位置的颜色。这样就得到了一组不同的颜色,每个颜色对应一个聚类标签。
这种方式确保了在可视化中使用了一组视觉上区分度较高的颜色,以区分不同的聚类。每个聚类标签都被分配一种颜色,使得在可视化中可以清晰地区分不同的簇。
2.1.4 完整代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 生成三个聚类中心的样本数据
centers = [[1, 1], [-1, -1], [1, -1], [-1,1]]
# 生成包含750个样本的聚类数据集,其中每个样本属于上述三个中心之一,cluster_std 控制聚类的标准差
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0)
X = StandardScaler().fit_transform(X) # 对样本数据进行标准化处理,确保每个特征的均值为0,标准差为1
# X = MinMaxScaler().fit_transform(X) # 对数据进行归一化处理
# 使用 DBSCAN 算法进行聚类
# eps 控制邻域的半径,min_samples 指定一个核心点所需的最小样本数
db = DBSCAN(eps=0.3, min_samples=20).fit(X)
# 创建一个布尔掩码,标记核心样本点
core_samples_mask = np.zeros_like(db.labels_, dtype=bool) # 创建一个与 db.labels_ 具有相同形状的全零数组,数据类型为布尔型
core_samples_mask[db.core_sample_indices_] = True # 将核心样本的位置标记为True
# 获取每个样本点的聚类标签
labels = db.labels_ # labels_ 属性可以返回聚类结果,-1表示是离群点。
# print(labels)
# 统计聚类结果的一些信息
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # 计算聚类的数量,忽略噪声点(标签为-1的点)
n_noise_ = list(labels).count(-1) # 统计噪声点的数量
print('估计的聚类数量:%d' % n_clusters_)
print('估计的噪声点数量:%d' % n_noise_)
# 同质性和完整性的得分越高越好
print("同质性:%0.3f" % metrics.homogeneity_score(labels_true, labels)) # 同质性,衡量每个群集中的成员是否都属于同一类别
print("完整性:%0.3f" % metrics.completeness_score(labels_true, labels)) # 完整性,度量是否找到了每个真实类别的所有成员
print("V-measure:%0.3f" % metrics.v_measure_score(labels_true, labels)) # V-measure,同质性和完整性的调和平均
# 调整兰德指数越接近1,说明聚类结果与真实标签之间具有越高的相似度
print("调整兰德指数:%0.3f" % metrics.adjusted_rand_score(labels_true, labels)) # 调整兰德指数,用于度量聚类结果与真实标签之间的相似性
print("调整互信息:%0.3f" % metrics.adjusted_mutual_info_score(labels_true, labels)) # 调整互信息,度量聚类结果与真实标签之间的信息一致性
print("轮廓系数:%0.3f" % metrics.silhouette_score(X, labels)) # 轮廓系数,度量聚类结果的紧密性和分离性,接近1表示聚类结果越好
print("DB指数:%0.3f" % metrics.davies_bouldin_score(X, labels)) # DB指数,衡量簇内紧密度和簇间分离度的指标,越小越好
# 画图
# 移除黑色(表示噪声),用于标识噪声点
unique_labels = set(labels) # 聚类得到的标签,即聚类得到的簇,标记为{0,1,2,-1},其中-1为噪声点
colors = [plt.cm.Spectral(each) for each in
np.linspace(0, 1, len(unique_labels))] # 生成一组颜色,以便在可视化中为不同的聚类标签选择不同的颜色,color.shape=(4,4)
# 遍历每个聚类标签,为每个簇选择颜色进行可视化
for k, col in zip(unique_labels, colors):
if k == -1:
# 对于标签为-1的噪声点,使用黑色
col = (0, 0, 0, 1)
# 获取属于当前聚类的样本点
class_member_mask = (labels == k)
# 绘制核心样本点(大圆点)
xy1 = X[class_member_mask & core_samples_mask]
plt.plot(xy1[:, 0], xy1[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=8)
# 绘制非核心样本点(小圆点)
xy2 = X[class_member_mask & ~core_samples_mask]
plt.plot(xy2[:, 0], xy2[:, 1], 'o', markerfacecolor=tuple(col),
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
2.2 不使用sklearn接口
(待补充)