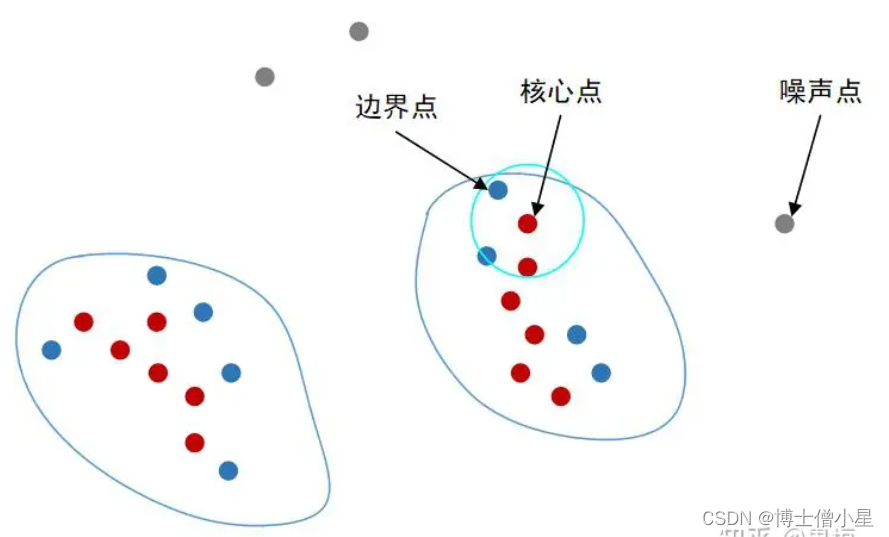
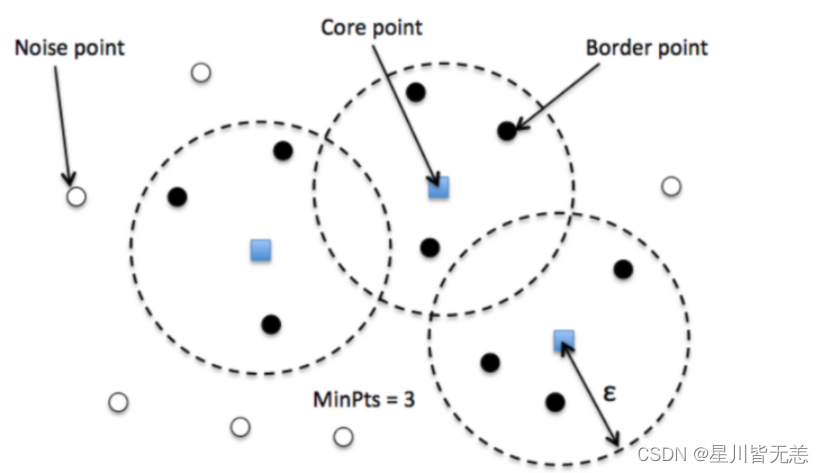
DBSCAN 即 Density of Based Spatial Clustering of Applications with Noise,带噪声的基于空间密度聚类算法。
算法步骤:
- 初始化:
- 首先,为每个数据点分配一个初始聚类标签,这里设为0,表示该点尚未被分配到一个聚类中。
- 设置一个聚类ID(cluster_id),初始化为0,用于标识不同的聚类。
- 遍历数据点:
遍历数据集中的每个点。如果某点已经被标记(即不属于聚类0),则跳过该点。 - 查找邻居点:
对于每个尚未被标记的点,使用get_neighbors函数查找其ε-邻域内的所有邻居点。这通常是通过计算该点与数据集中其他点之间的欧氏距离,并比较距离与ε来实现的。 - 处理邻居点数量:
- 如果找到的邻居点数量小于min_pts(最小邻居数量),则将当前点标记为噪声点(标签设为-1)。
- 如果邻居点数量大于或等于min_pts,则将该点标记为一个新的聚类(将cluster_id加1,并将该点标签设为新的cluster_id)。
- 扩展聚类:
- 对于每个新发现的聚类中的点(即刚被标记为当前cluster_id的点),执行expand_cluster函数以进一步扩展聚类。
- 在expand_cluster函数中,遍历当前点的所有邻居点,并根据其标签进行处理:
- 如果邻居点是噪声点(标签为-1),则将其标记为当前聚类(将标签改为cluster_id)。
- 如果邻居点尚未被标记(标签为0),则将其标记为当前聚类,并递归地查找并标记其邻居点(如果其邻居点数量也满足min_pts)。
- 返回结果:
当所有点都被处理完毕后,算法返回每个数据点的最终聚类标签。
下面是代码实现:
from collections import Counter
import numpy as np
from sklearn.datasets import make_blobs
def dbscan(data, eps, min_pts):
# 初始化每个数据点的聚类标签为 0
labels = [0] * len(data)
# 聚类 id
cluster_id = 0
for i in range(len(data)):
if labels[i] != 0:
# 如果数据点已经被标记过,则跳过该点,继续下一个点
continue
# 获取当前点的邻居点
neighbors = get_neighbors(data, i, eps)
# 如果邻居点的数量小于最小邻居数量,则将当前点标记为噪声点
if len(neighbors) < min_pts:
labels[i] = -1
else:
# 否则,增加聚类 id
cluster_id += 1
# 将当前点标记为当前聚类 id
labels[i] = cluster_id
# 扩展聚类
expand_cluster(data, labels, neighbors, cluster_id, eps, min_pts)
# 返回每个数据点的聚类标签
return labels
def expand_cluster(data, labels, neighbors, cluster_id, eps, min_pts):
# 遍历每个邻居点
for neighbor in neighbors:
# 如果邻居点的标签为 -1
if labels[neighbor] == -1:
# 将噪声点标记为当前聚类 id
labels[neighbor] = cluster_id
# 如果邻居点的标签为 0
elif labels[neighbor] == 0:
# 将邻居点标记为当前聚类 id
labels[neighbor] = cluster_id
# 获取邻居点的邻居点
new_neighbors = get_neighbors(data, neighbor, eps)
# 如果新的邻居点数量满足最小邻居数量要求,则将其加入邻居列表
if len(new_neighbors) >= min_pts:
neighbors += new_neighbors
def get_neighbors(data, point_idx, eps):
# 邻居点列表
neighbors = []
for i in range(len(data)):
# 计算当前点与目标点之间的欧氏距离,如果距离小于邻域半径 eps
if np.linalg.norm(data[i] - data[point_idx]) < eps:
# 将目标点的索引加入邻居点列表
neighbors.append(i)
# 返回邻居点列表
return neighbors
np.random.seed(0)
# 生成样例数据
data, y = make_blobs(n_samples=200, centers=5, cluster_std=0.6)
print(Counter(y))
eps, min_pts = 0.6, 3
# 进行聚类
labels = dbscan(data, eps, min_pts)
print(Counter(labels))
上述代码实现了一个简单的 DBSCAN 算法。注意,在实际应用中,你需要根据实际情况调整邻域半径参数和核心点周围最小数据点数。
一般情况下,最小数据点数取数据维度值的 2 倍数,最小取 3。 该参数越大,可能的噪声点会被聚类,同样的邻域半径越小,噪声点也会被分类。