目录
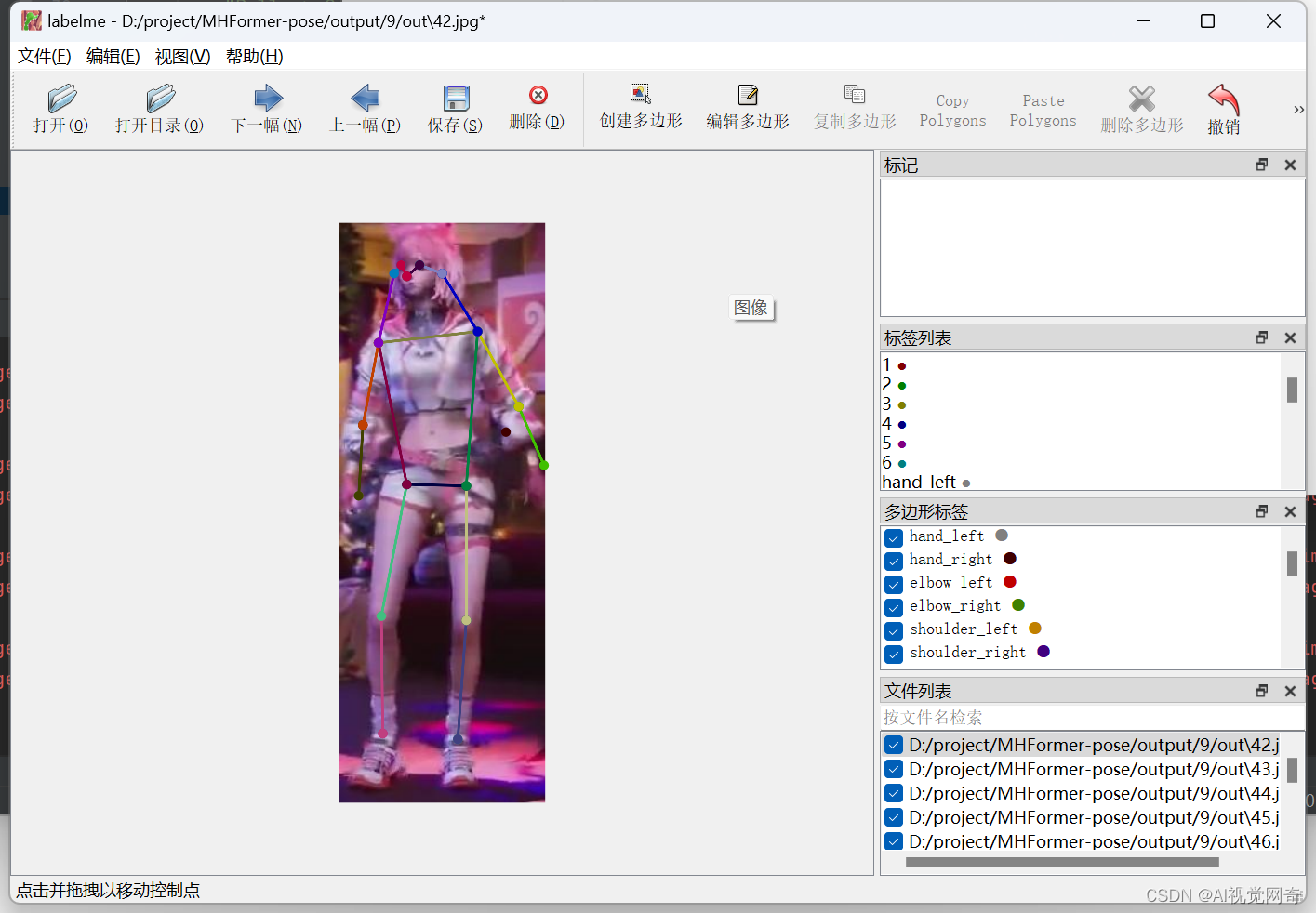
mhformer 也是先进行人体检测,输出2d关键点,再估计3d关键点,
预测并可视化代码
需要注释掉plt.switch_backend('agg')
调整部分代码:
output_dir_3D = output_dir +'pose3D/'
os.makedirs(output_dir_3D, exist_ok=True)
plt.show()
# plt.savefig(output_dir_3D + str(('%04d'% i)) + '_3D.png', dpi=200, format='png', bbox_inches = 'tight')可视化推理:
import sys
import argparse
import cv2
from demo.lib.preprocess import h36m_coco_format, revise_kpts
from demo.lib.hrnet.gen_kpts import gen_video_kpts as hrnet_pose
import os
import numpy as np
import torch
import glob
from tqdm import tqdm
import copy
sys.path.append(os.getcwd())
from model.mhformer import Model
from common.camera import *
import matplotlib
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.gridspec as gridspec
# plt.switch_backend('agg')
matplotlib.rcParams['pdf.fonttype'] = 42
matplotlib.rcParams['ps.fonttype'] = 42
def show2Dpose(kps, img):
connections = [[0, 1], [1, 2], [2, 3], [0, 4], [4, 5],
[5, 6], [0, 7], [7, 8], [8, 9], [9, 10],
[8, 11], [11, 12], [12, 13], [8, 14], [14, 15], [15, 16]]
LR = np.array([0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], dtype=bool)
lcolor = (255, 0, 0)
rcolor = (0, 0, 255)
thickness = 3
for j,c in enumerate(connections):
start = map(int, kps[c[0]])
end = map(int, kps[c[1]])
start = list(start)
end = list(end)
cv2.line(img, (start[0], start[1]), (end[0], end[1]), lcolor if LR[j] else rcolor, thickness)
cv2.circle(img, (start[0], start[1]), thickness=-1, color=(0, 255, 0), radius=3)
cv2.circle(img, (end[0], end[1]), thickness=-1, color=(0, 255, 0), radius=3)
return img
def show3Dpose(vals, ax):
ax.view_init(elev=15., azim=70)
lcolor=(0,0,1)
rcolor=(1,0,0)
I = np.array( [0, 0, 1, 4, 2, 5, 0, 7, 8, 8, 14, 15, 11, 12, 8, 9])
J = np.array( [1, 4, 2, 5, 3, 6, 7, 8, 14, 11, 15, 16, 12, 13, 9, 10])
LR = np.array([0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0], dtype=bool)
for i in np.arange( len(I) ):
x, y, z = [np.array( [vals[I[i], j], vals[J[i], j]] ) for j in range(3)]
ax.plot(x, y, z, lw=2, color = lcolor if LR[i] else rcolor)
RADIUS = 0.72
RADIUS_Z = 0.7
xroot, yroot, zroot = vals[0,0], vals[0,1], vals[0,2]
ax.set_xlim3d([-RADIUS+xroot, RADIUS+xroot])
ax.set_ylim3d([-RADIUS+yroot, RADIUS+yroot])
ax.set_zlim3d([-RADIUS_Z+zroot, RADIUS_Z+zroot])
ax.set_aspect('equal') # works fine in matplotlib==2.2.2 or 3.7.1
white = (1.0, 1.0, 1.0, 0.0)
ax.xaxis.set_pane_color(white)
ax.yaxis.set_pane_color(white)
ax.zaxis.set_pane_color(white)
ax.tick_params('x', labelbottom = False)
ax.tick_params('y', labelleft = False)
ax.tick_params('z', labelleft = False)
def get_pose2D(video_path, output_dir):
cap = cv2.VideoCapture(video_path)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
print('\nGenerating 2D pose...')
with torch.no_grad():
# the first frame of the video should be detected a person
keypoints, scores = hrnet_pose(video_path, det_dim=416, num_peroson=1, gen_output=True)
keypoints, scores, valid_frames = h36m_coco_format(keypoints, scores)
re_kpts = revise_kpts(keypoints, scores, valid_frames)
print('Generating 2D pose successfully!')
output_dir += 'input_2D/'
os.makedirs(output_dir, exist_ok=True)
output_npz = output_dir + 'keypoints.npz'
np.savez_compressed(output_npz, reconstruction=keypoints)
def img2video(video_path, output_dir):
cap = cv2.VideoCapture(video_path)
fps = int(cap.get(cv2.CAP_PROP_FPS)) + 5
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
names = sorted(glob.glob(os.path.join(output_dir + 'pose/', '*.png')))
img = cv2.imread(names[0])
size = (img.shape[1], img.shape[0])
videoWrite = cv2.VideoWriter(output_dir + video_name + '.mp4', fourcc, fps, size)
for name in names:
img = cv2.imread(name)
videoWrite.write(img)
videoWrite.release()
def showimage(ax, img):
ax.set_xticks([])
ax.set_yticks([])
plt.axis('off')
ax.imshow(img)
def get_pose3D(video_path, output_dir):
args, _ = argparse.ArgumentParser().parse_known_args()
args.layers, args.channel, args.d_hid, args.frames = 3, 512, 1024, 351
args.pad = (args.frames - 1) // 2
args.previous_dir = 'checkpoint/pretrained/351'
args.n_joints, args.out_joints = 17, 17
## Reload
model = Model(args).cuda()
model_dict = model.state_dict()
# Put the pretrained model of MHFormer in 'checkpoint/pretrained/351'
model_path = sorted(glob.glob(os.path.join(args.previous_dir, '*.pth')))[0]
pre_dict = torch.load(model_path)
for name, key in model_dict.items():
model_dict[name] = pre_dict[name]
model.load_state_dict(model_dict)
model.eval()
## input
keypoints = np.load(output_dir + 'input_2D/keypoints.npz', allow_pickle=True)['reconstruction']
cap = cv2.VideoCapture(video_path)
video_length = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
## 3D
print('\nGenerating 3D pose...')
output_3d_all = []
for i in tqdm(range(video_length)):
ret, img = cap.read()
img_size = img.shape
## input frames
start = max(0, i - args.pad)
end = min(i + args.pad, len(keypoints[0])-1)
input_2D_no = keypoints[0][start:end+1]
left_pad, right_pad = 0, 0
if input_2D_no.shape[0] != args.frames:
if i < args.pad:
left_pad = args.pad - i
if i > len(keypoints[0]) - args.pad - 1:
right_pad = i + args.pad - (len(keypoints[0]) - 1)
input_2D_no = np.pad(input_2D_no, ((left_pad, right_pad), (0, 0), (0, 0)), 'edge')
joints_left = [4, 5, 6, 11, 12, 13]
joints_right = [1, 2, 3, 14, 15, 16]
input_2D = normalize_screen_coordinates(input_2D_no, w=img_size[1], h=img_size[0])
input_2D_aug = copy.deepcopy(input_2D)
input_2D_aug[ :, :, 0] *= -1
input_2D_aug[ :, joints_left + joints_right] = input_2D_aug[ :, joints_right + joints_left]
input_2D = np.concatenate((np.expand_dims(input_2D, axis=0), np.expand_dims(input_2D_aug, axis=0)), 0)
input_2D = input_2D[np.newaxis, :, :, :, :]
input_2D = torch.from_numpy(input_2D.astype('float32')).cuda()
N = input_2D.size(0)
## estimation
output_3D_non_flip = model(input_2D[:, 0])
output_3D_flip = model(input_2D[:, 1])
output_3D_flip[:, :, :, 0] *= -1
output_3D_flip[:, :, joints_left + joints_right, :] = output_3D_flip[:, :, joints_right + joints_left, :]
output_3D = (output_3D_non_flip + output_3D_flip) / 2
output_3D = output_3D[0:, args.pad].unsqueeze(1)
output_3D[:, :, 0, :] = 0
post_out = output_3D[0, 0].cpu().detach().numpy()
output_3d_all.append(post_out)
rot = [0.1407056450843811, -0.1500701755285263, -0.755240797996521, 0.6223280429840088]
rot = np.array(rot, dtype='float32')
post_out = camera_to_world(post_out, R=rot, t=0)
post_out[:, 2] -= np.min(post_out[:, 2])
input_2D_no = input_2D_no[args.pad]
## 2D
image = show2Dpose(input_2D_no, copy.deepcopy(img))
output_dir_2D = output_dir +'pose2D/'
os.makedirs(output_dir_2D, exist_ok=True)
cv2.imwrite(output_dir_2D + str(('%04d'% i)) + '_2D.png', image)
## 3D
fig = plt.figure( figsize=(9.6, 5.4))
gs = gridspec.GridSpec(1, 1)
gs.update(wspace=-0.00, hspace=0.05)
ax = plt.subplot(gs[0], projection='3d')
show3Dpose( post_out, ax)
output_dir_3D = output_dir +'pose3D/'
os.makedirs(output_dir_3D, exist_ok=True)
plt.show()
# plt.savefig(output_dir_3D + str(('%04d'% i)) + '_3D.png', dpi=200, format='png', bbox_inches = 'tight')
## save 3D keypoints
output_3d_all = np.stack(output_3d_all, axis = 0)
os.makedirs(output_dir + 'output_3D/', exist_ok=True)
output_npz = output_dir + 'output_3D/' + 'output_keypoints_3d.npz'
np.savez_compressed(output_npz, reconstruction=output_3d_all)
print('Generating 3D pose successfully!')
## all
image_dir = 'results/'
image_2d_dir = sorted(glob.glob(os.path.join(output_dir_2D, '*.png')))
image_3d_dir = sorted(glob.glob(os.path.join(output_dir_3D, '*.png')))
print('\nGenerating demo...')
for i in tqdm(range(len(image_2d_dir))):
image_2d = plt.imread(image_2d_dir[i])
image_3d = plt.imread(image_3d_dir[i])
## crop
edge = (image_2d.shape[1] - image_2d.shape[0]) // 2
image_2d = image_2d[:, edge:image_2d.shape[1] - edge]
edge = 102
image_3d = image_3d[edge:image_3d.shape[0] - edge, edge:image_3d.shape[1] - edge]
## show
font_size = 12
fig = plt.figure(figsize=(9.6, 5.4))
ax = plt.subplot(121)
showimage(ax, image_2d)
ax.set_title("Input", fontsize = font_size)
ax = plt.subplot(122)
showimage(ax, image_3d)
ax.set_title("Reconstruction", fontsize = font_size)
## save
output_dir_pose = output_dir +'pose/'
os.makedirs(output_dir_pose, exist_ok=True)
plt.show()
# plt.savefig(output_dir_pose + str(('%04d'% i)) + '_pose.png', dpi=200, bbox_inches = 'tight')
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--video', type=str, default='CUSTOM_390-1.mp4', help='input video')
# parser.add_argument('--video', type=str, default='sample_video.mp4', help='input video')
parser.add_argument('--gpu', type=str, default='0', help='input video')
args = parser.parse_args()
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
video_path = './demo/video/' + args.video
video_name = video_path.split('/')[-1].split('.')[0]
output_dir = './demo/output/' + video_name + '/'
get_pose2D(video_path, output_dir)
get_pose3D(video_path, output_dir)
img2video(video_path, output_dir)
print('Generating demo successful!')