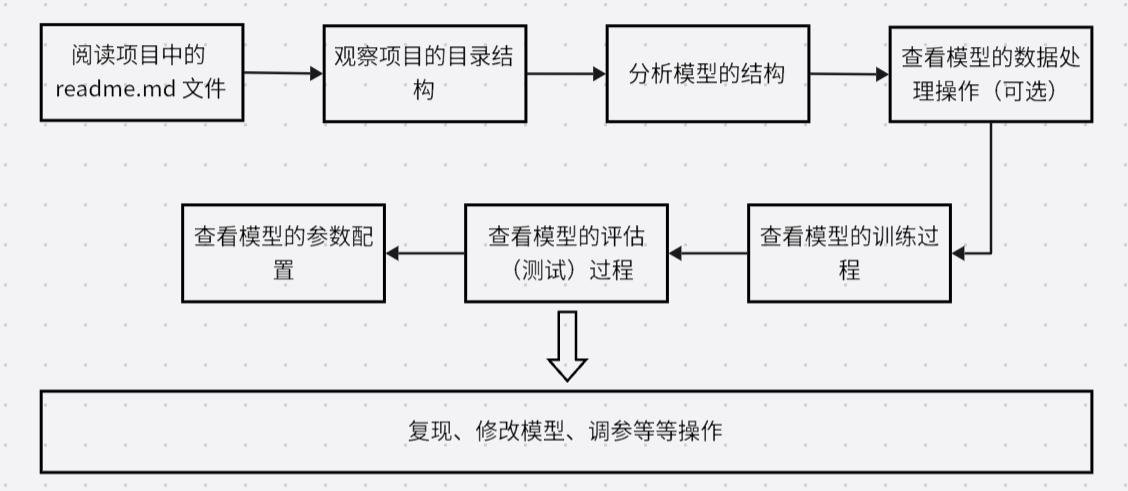
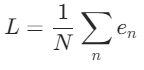PyTorch
PyTorch(Python Torch)是一个开源的机器学习库,主要用于深度学习任务。它由 Facebook 的人工智能研究小组开发,提供了灵活的张量(tensor)数据结构和强大的深度学习工具。以下是 PyTorch 提供的一些基础数据结构和主要功能:
基础结构:
Tensor(张量):
PyTorch 中的基本数据结构是张量,它是一个多维数组,类似于 NumPy 的数组。张量可以在 GPU 上加速运算,支持自动求导,是深度学习中的核心数据类型。import torch # 创建张量 x = torch.tensor([[1, 2, 3], [4, 5, 6]])Autograd(自动求导):
PyTorch 的 Autograd 模块提供了自动求导的功能,允许计算图中的梯度。这对于训练神经网络和优化模型参数非常重要。import torch # 创建需要求导的张量 x = torch.tensor([2.0], requires_grad=True) # 定义计算图 y = x**2 # 计算梯度 y.backward() # 打印梯度 print(x.grad)
主要功能:
神经网络模块:
PyTorch 提供了torch.nn模块,其中包含了构建神经网络的基本组件,如层(Layer)、激活函数、损失函数等。通过继承torch.nn.Module类,用户可以定义自己的神经网络模型。import torch import torch.nn as nn # 定义一个简单的神经网络模型 class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.fc = nn.Linear(10, 5) def forward(self, x): return self.fc(x) # 创建模型实例 model = SimpleModel()优化器:
PyTorch 提供了多种优化器,如随机梯度下降(SGD)、Adam 等,用于更新模型的参数以最小化损失函数。import torch.optim as optim # 创建优化器 optimizer = optim.SGD(model.parameters(), lr=0.01) # 在训练循环中使用优化器 optimizer.zero_grad() output = model(input_data) loss = loss_function(output, target) loss.backward() optimizer.step()数据加载与处理:
PyTorch 提供了torch.utils.data模块,用于构建数据加载器(DataLoader)和数据集(Dataset),方便高效地加载和处理数据。import torch from torch.utils.data import Dataset, DataLoader # 定义自己的数据集类 class MyDataset(Dataset): def __init__(self, data, labels): self.data = data self.labels = labels def __len__(self): return len(self.data) def __getitem__(self, index): return self.data[index], self.labels[index] # 创建数据集实例和数据加载器 dataset = MyDataset(data, labels) dataloader = DataLoader(dataset, batch_size=32, shuffle=True)GPU 加速支持:
PyTorch 允许张量在 GPU 上运行,通过使用.cuda()方法可以将张量移动到 GPU 上进行计算。import torch # 创建张量 x = torch.tensor([1, 2, 3]) # 将张量移动到 GPU 上 x_gpu = x.cuda()模型保存与加载:
PyTorch 允许将模型保存为文件以及从文件加载模型。这使得在训练后保存模型状态,以及在需要时加载预训练模型变得非常方便。import torch # 保存模型 torch.save(model.state_dict(), 'model.pth') # 加载模型 loaded_model = SimpleModel() loaded_model.load_state_dict(torch.load('model.pth'))
这些功能使得 PyTorch 成为深度学习领域中一个广泛使用的框架,支持从基础的张量操作到构建复杂神经网络的全面深度学习工作。
Tensor
PyTorch 中的 Tensor 是多维数组,类似于 NumPy 的数组。Tensor 是 PyTorch 中的基本数据类型,用于构建神经网络模型并进行各种数学运算。以下是一些基本的 Tensor 操作和主要用法:
创建 Tensor:
从列表或数组创建:
import torch # 从列表创建一维 Tensor tensor1d = torch.tensor([1, 2, 3]) # 从数组创建二维 Tensor tensor2d = torch.tensor([[1, 2, 3], [4, 5, 6]])使用特殊方法创建:
import torch # 创建全零 Tensor zeros_tensor = torch.zeros((3, 3)) # 创建全一 Tensor ones_tensor = torch.ones((2, 2)) # 创建随机 Tensor random_tensor = torch.rand((3, 3))指定数据类型和设备:
import torch # 指定数据类型为浮点型 float_tensor = torch.tensor([1, 2, 3], dtype=torch.float) # 将 Tensor 移动到 GPU gpu_tensor = tensor1d.cuda()
Tensor 基本操作:
索引和切片:
import torch tensor = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 获取单个元素 element = tensor[0, 1] # 切片操作 sliced_tensor = tensor[:, 1:3]形状操作:
import torch tensor = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 获取 Tensor 形状 shape = tensor.shape # 改变形状 reshaped_tensor = tensor.view(3, 2)数学运算:
import torch # 创建两个 Tensor tensor1 = torch.tensor([1, 2, 3], dtype=torch.float) tensor2 = torch.tensor([4, 5, 6], dtype=torch.float) # 加法 sum_tensor = tensor1 + tensor2 # 矩阵乘法 product_tensor = torch.matmul(tensor1, tensor2)自动求导:
import torch # 创建需要求导的 Tensor x = torch.tensor([2.0], requires_grad=True) # 定义计算图 y = x**2 # 计算梯度 y.backward() # 打印梯度 print(x.grad)
Tensor 的其他用法:
转换为 NumPy 数组:
import torch tensor = torch.tensor([1, 2, 3]) # 转换为 NumPy 数组 numpy_array = tensor.numpy()拼接和拆分:
import torch tensor1 = torch.tensor([[1, 2], [3, 4]]) tensor2 = torch.tensor([[5, 6]]) # 拼接操作 concatenated_tensor = torch.cat((tensor1, tensor2), dim=0) # 拆分操作 split_tensors = torch.split(tensor1, split_size_or_sections=1, dim=1)统计操作:
import torch tensor = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 计算平均值 mean_value = tensor.mean() # 计算标准差 std_value = tensor.std()
这些是一些基本的 Tensor 操作和主要用法。Tensor 在 PyTorch 中是一个非常灵活且功能强大的数据结构,适用于构建深度学习模型和进行各种数学运算。在深度学习中,对 Tensor 的熟练使用是非常重要的。
Autograd
Autograd(自动求导)是 PyTorch 中的一个计算图和自动求导系统。它是 PyTorch 提供的一个功能,用于动态计算图和自动计算梯度。
在 PyTorch 中,Autograd 能够自动追踪在张量上进行的操作,并构建一个计算图。计算图是由节点(表示操作)和边(表示张量)组成的图形结构,描述了数据流和操作的关系。Autograd 在执行操作时会记录这些节点和边,使得后续可以方便地进行梯度计算。
Autograd 的主要组成部分包括:
Variable(变量):
Variable是 Autograd 的核心数据结构之一,它包装了张量(Tensor)并封装了计算图中的节点。Variable具有两个重要的属性:data存储原始张量,grad存储梯度。用户通常不直接创建Variable对象,而是通过操作张量获得。import torch # 创建 Variable(在 PyTorch 1.0 后,Tensor 本身即为 Variable) x = torch.tensor([2.0], requires_grad=True)计算图:
Autograd 构建的计算图记录了张量上的操作,这使得在进行反向传播时能够自动计算梯度。计算图是由张量操作(节点)和张量(边)组成的有向无环图。import torch # 创建计算图 x = torch.tensor([2.0], requires_grad=True) y = x**2 z = y.mean() # 计算梯度 z.backward() # 查看梯度 print(x.grad)梯度计算:
Autograd 通过反向传播算法自动计算梯度。在计算图的反向遍历过程中,Autograd 计算了每个节点对应的梯度,并将梯度存储在相应的grad属性中。import torch # 创建计算图 x = torch.tensor([2.0], requires_grad=True) y = x**2 z = y.mean() # 计算梯度 z.backward() # 查看梯度 print(x.grad)
Autograd 提供了一个强大的机制,使得在 PyTorch 中进行梯度计算变得非常方便。它支持动态计算图,允许用户根据需要构建和修改计算图,是深度学习中反向传播的基础。
简单示例
下面是一个简单的示例,演示如何使用 PyTorch 搭建一个多层的深度神经网络(MLP),进行训练、测试并保存模型。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.metrics import accuracy_score
# 检查是否有可用的 CUDA 设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 载入手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 转换为 PyTorch 张量
X_train_tensor = torch.tensor(X_train, dtype=torch.float32).to(device)
y_train_tensor = torch.tensor(y_train, dtype=torch.long).to(device)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32).to(device)
y_test_tensor = torch.tensor(y_test, dtype=torch.long).to(device)
# 创建数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 定义一个多层感知机(MLP)模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 初始化模型、损失函数和优化器
input_size = X_train.shape[1]
hidden_size = 64
output_size = 10
model = MLP(input_size, hidden_size, output_size).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch [{
epoch+1}/{
num_epochs}], Loss: {
loss.item():.4f}')
# 测试模型
model.eval()
with torch.no_grad():
y_pred = model(X_test_tensor)
_, predicted = torch.max(y_pred, 1)
acc = accuracy_score(y_test, predicted.cpu().numpy())
print(f'Test Accuracy: {
acc:.4f}')
# 保存模型
torch.save(model.state_dict(), 'mlp_model.pth')
在这个示例中:
- 加载手写数字数据集,并划分为训练集和测试集。
- 创建 PyTorch 的 Tensor,并使用
DataLoader构建数据加载器。 - 定义一个简单的多层神经网络(MLP)模型。
- 初始化损失函数(交叉熵损失)和优化器(Adam)。
- 进行模型训练。
- 在测试集上评估模型的准确性。
- 保存训练好的模型参数。
这个示例展示了一个完整的训练、测试和保存模型的流程。在实际应用中,你可能需要根据任务的不同进行更复杂的模型设计和调参。
写在最后
本文采用了 ChatGPT 辅助进行内容的书写和完善