paper:PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
official implementation:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.8/paddleseg/models/pp_liteseg.py
本文的创新点
- 提出了一种灵活的轻量级解码器(Flexible and Lightweight Decoder, FLD),减轻了解码器的冗余性,平衡了encoder和decoder的计算成本。
- 提出了一个新的注意力融合模块(Unified Attention Fusion Module, UAFM),利用空间和通道注意力来加强特征表示。
- 提出了Simple Pyramid Pooling Module(SPPM)来聚合全局上下文。
方法介绍
Flexible and Lightweight Decoder
encoder-decoder结构是常用的语义分割结构,一般来说,encoder通过分组为几个stage的若干卷积层来提取层级特征,从低层到高层,特征通道数逐渐增加,空间尺寸逐渐减小,这种设计平衡了各阶段的计算成本,保证了encoder的效率。decoder也分为几个stage,负责融合和上采样。尽管从高层到低层,特征的空间尺寸逐渐增加,但在最近的轻量模型中,decoder中的通道数保持不变。因此低层的计算成本远大于高层,为了提高decoder的效率,本文提出了一种灵活的轻量解码器FLD,如图3所示,从high-level到low-level,FLD逐渐减少通道数量,FLD可以很容易的调整计算成本实现编码器和解码器之间的平衡。

Unified Attention Fusion Module
融合多尺度特征是实现高精度分割的关键,本文提出了一个新的注意力融合模块(Unified Attention Fusion Module, UAFM),它应用通道和空间注意力来丰富融合特征的表示。
UFAM framework
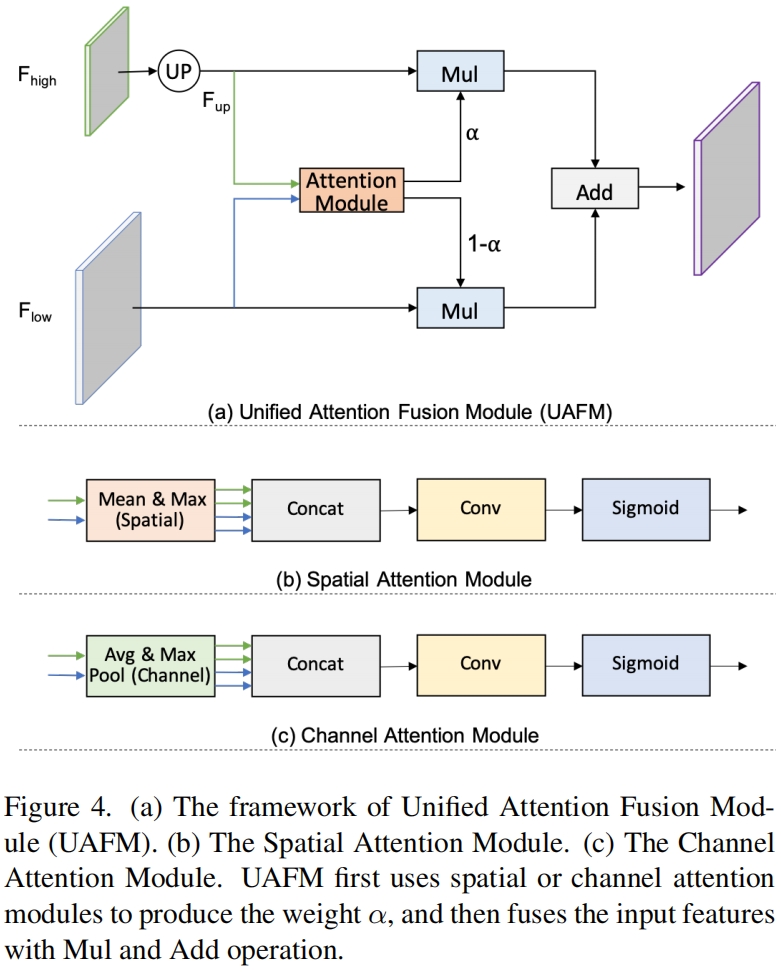
如图4(a)所示,UFAM利用一个注意力模块得到权重 \(\alpha\),并通过Mul和Add操作用权重 \(\alpha\) 融合输入特征。具体而言,输入特征表示为 \(F_{high}\) 和 \(F_{low}\),\(F_{high}\) 是深层模块的输出,\(F_{low}\) 是encoder中的对应输出,它们通道数相同。UFAM首先通过双线性插值上采样 \(F_{high}\) 和 \(F_{low}\) 相同尺度大小得到 \(F_{up}\)。然后注意力模块以 \(F_{up}\) 和 \(F_{low}\) 作为输入得到权重 \(\alpha\),这里注意力模块是一个plugin,可以是通道注意力模块、空间注意力模块等。然后分别对 \(F_{up}\) 和 \(F_{low}\) 进行element-wise Mul操作最后两者进行element-wise Add得到最终输出。如下
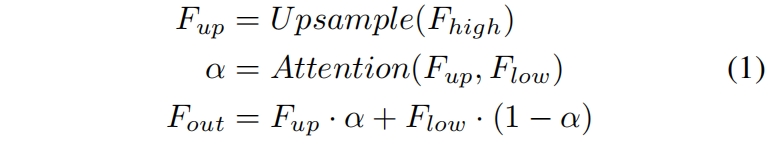
Spatial Attention Module
空间注意力模块利用inter-spatial关系得到一个权重,它表示的是输入特征中每个像素位置的重要性。如图4(b)所示,给定输入 \(F_{up}\in R^{C\times H\times W}\) 和 \(F_{low}\in R^{C\times H\times W}\),首先沿通道维度计算mean、max得到四个维度 \(R^{1\times H\times W}\) 的特征,然后拼接得到 \(F_{cat}\in R^{4\times H\times W}\),然后接一层卷积和sigmoid得到权重 \(\alpha\in R^{1\times H\times W}\)。具体如式2,这里具体的实现方式是灵活的,比如可以去掉max操作来降低计算成本。

Channel Attention Module
通道注意力模块的关键是利用inter-channel关系得到一个权重,它表示的是输入特征中每个通道的重要性。如图4(c)所示,首先利用average-pooling和max-pooling得到四个维度为 \(R^{C\times 1\times 1}\) 的输出,然后沿通道拼接并接一层卷积和sigmoid得到权重 \(\alpha \in R^{C\times 1\times 1}\),具体过程如下
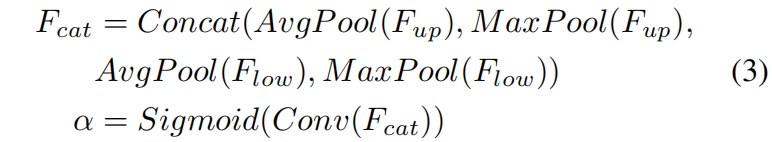
Simple Pyramid Pooling Module

如图5所示,本文提出的SPPM,它首先利用金字塔池化模块来融合输入特征,其中包含三个average pooling,bin size分别为1x1、2x2、4x4。然后分别进行卷积和上采样,卷积大小为1x1,输出通道数小于输入通道,最后将三个特征相加再接一层卷积得到输出特征。和原始的PPM相比,SPPM减少了中间和输出的通道数,去掉了short-cut,将concatenate替换为add,因此SPPM更高效也更适合实时模型。
实验结果
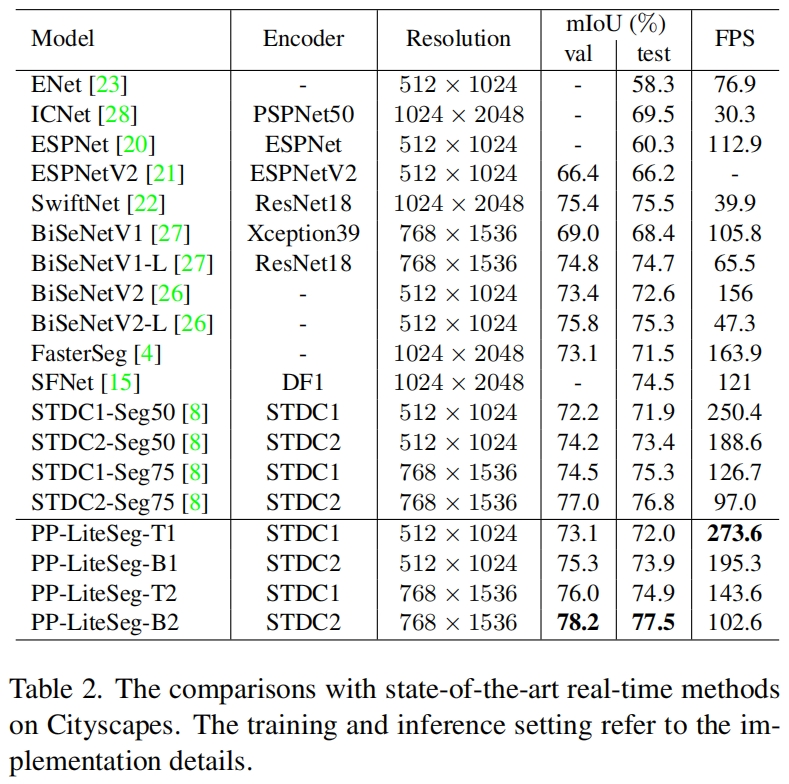
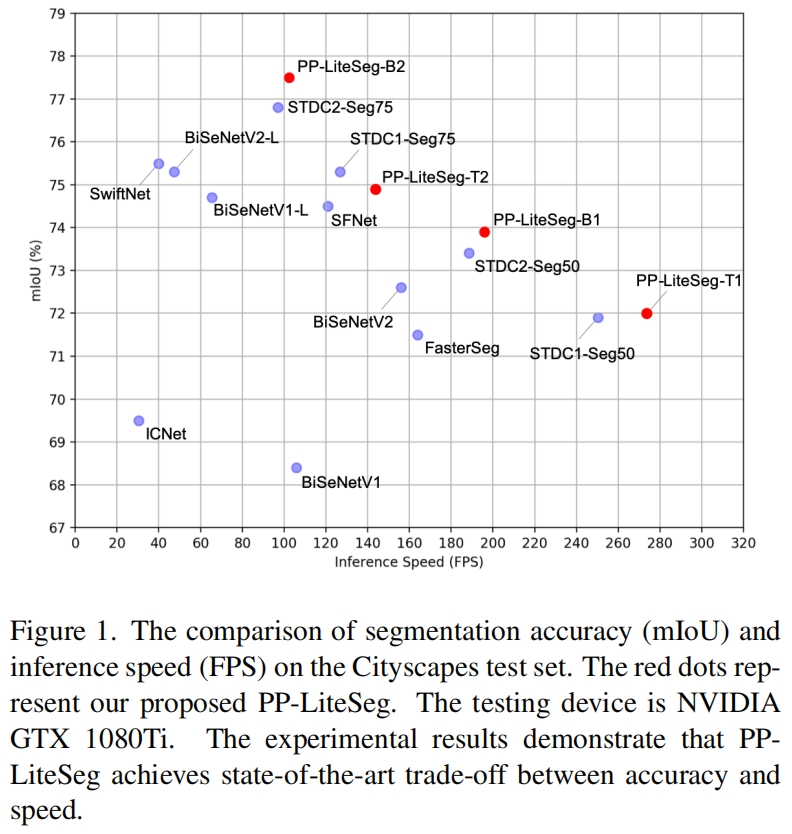
PP-LiteSeg和其它sota模型在Cityscapes数据集上的结果比较如下
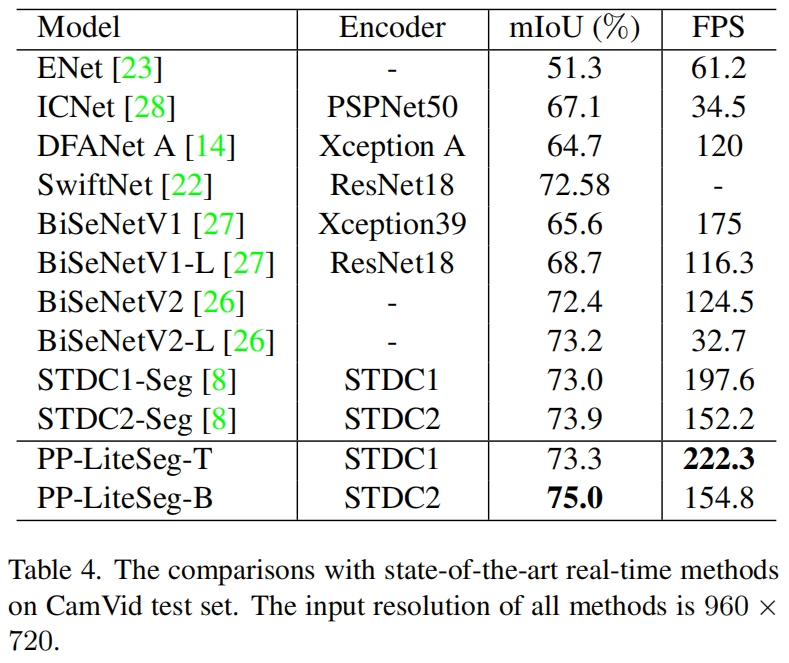
在CamVid测试集上的结果对比如下