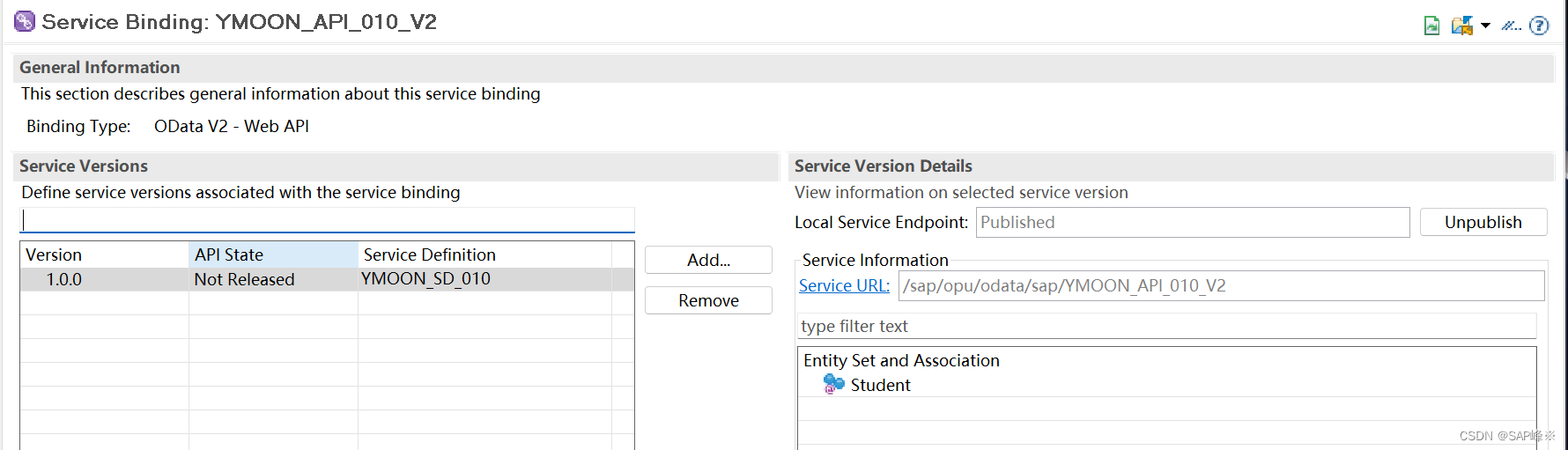
1、部署模式解析
1.1部署模式概述
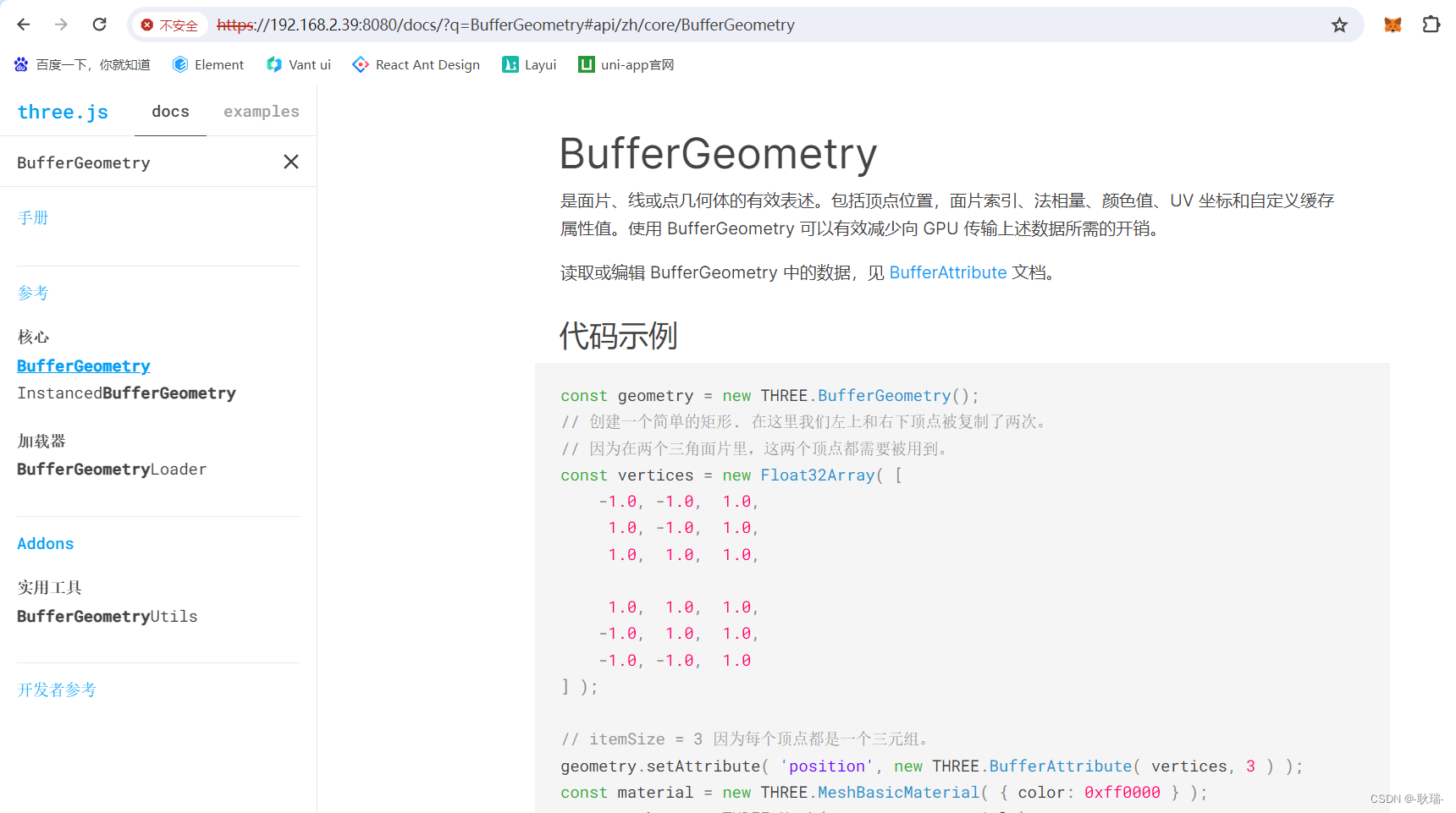
Spark支持的主要的三种分布式部署方式分别是standalone、spark on mesos和 spark on YARN。standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。它是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。而yarn是统一的资源管理机制,在上面可以运行多套计算框架,如map reduce、storm等根据driver在集群中的位置不同,分为yarn client和yarn cluster。而mesos是一个更强大的分布式资源管理框架,它允许多种不同的框架部署在其上,包括yarn。基本上,Spark的运行模式取决于传递给SparkContext的MASTER环境变量的值,个别模式还需要辅助的程序接口来配合使用,目前支持的Master字符串及URL包括:
用户在提交任务给Spark处理时,以下两个参数共同决定了Spark的运行方式。
· –master MASTER_URL :决定了Spark任务提交给哪种集群处理。
· –deploy-mode DEPLOY_MODE:决定了Driver的运行方式,可选值为Client或者Cluster。
1.2standalone框架
standalone集群由三个不同级别的节点组成,分别是
1)Master 主控节点,可以类比为董事长或总舵主,在整个集群之中,最多只有一个Master处在Active状态
2)Worker 工作节点 ,这个是manager,是分舵主, 在整个集群中,可以有多个worker,如果worker为零,什么事也做不了
3)Executor 干苦力活的,直接受worker掌控,一个worker可以启动多个executor,启动的个数受限于机器中的cpu核数
这三种不同类型的节点各自运行于自己的JVM进程之中。
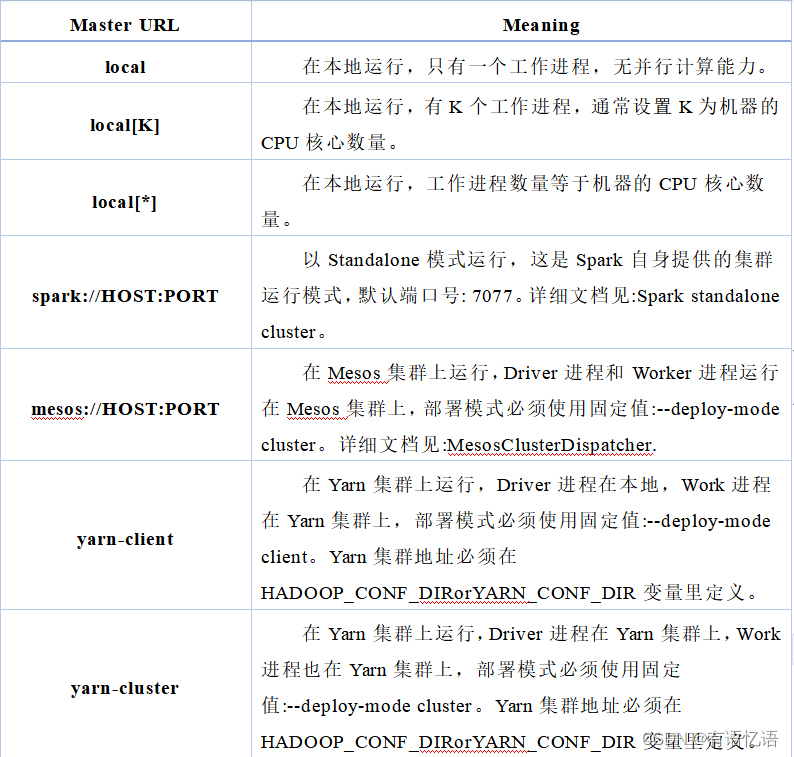
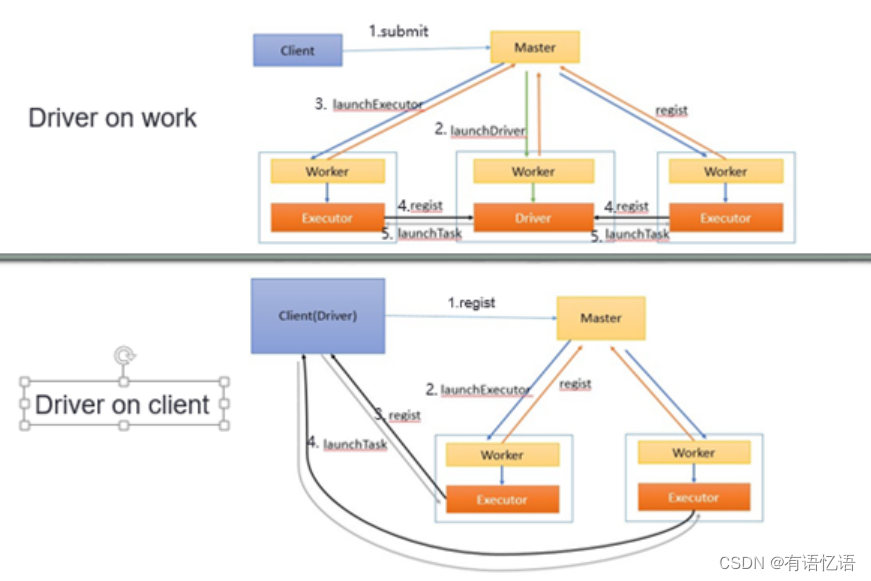
Standalone模式下,集群启动时包括Master与Worker,其中Master负责接收客户端提交的作业,管理Worker。根据作业提交的方式不同,分为driver on client 和drvier on worker。如下图7所示,上图为driver on work模式,下图为driver on client模式。两种模式的主要不同点在于driver所在的位置。
在standalone部署模式下又分为client模式和cluster模式,其中client模式下,driver和client运行于同一JVM中,不由worker启动,该JVM进程直到spark application计算完成返回结果后才退出。如下图所示。
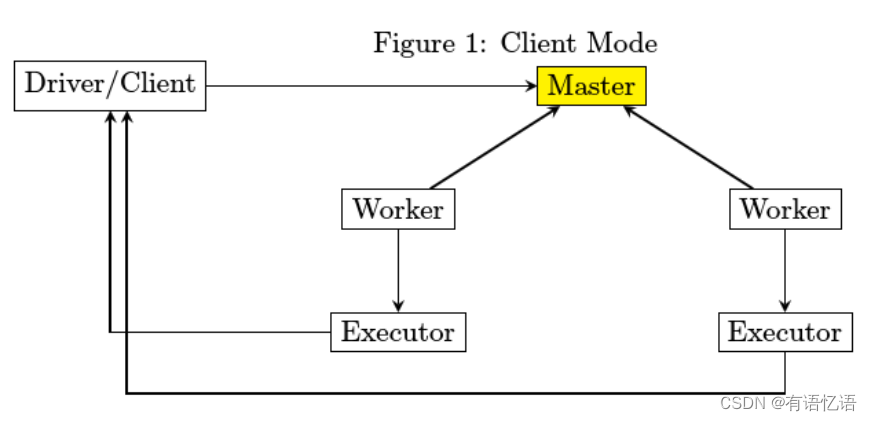
而在cluster模式下,driver由worker启动,client在确认spark application成功提交给cluster后直接退出,并不等待spark application运行结果返回。如下图所示
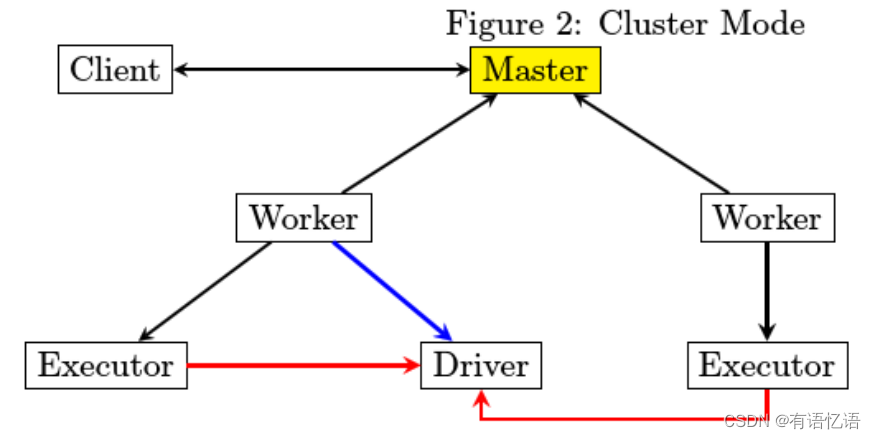
从部署图来进行分析,每个JVM进程在启动时的文件依赖如何得到满足。
1)Master进程最为简单,除了spark jar包之外,不存在第三方库依赖
2)Driver和Executor在运行的时候都有可能存在第三方包依赖,分开来讲
3)Driver比较简单,spark-submit在提交的时候会指定所要依赖的jar文件从哪里读取
4)Executor由worker来启动,worker需要下载Executor启动时所需要的jar文件,那么从哪里下载呢。
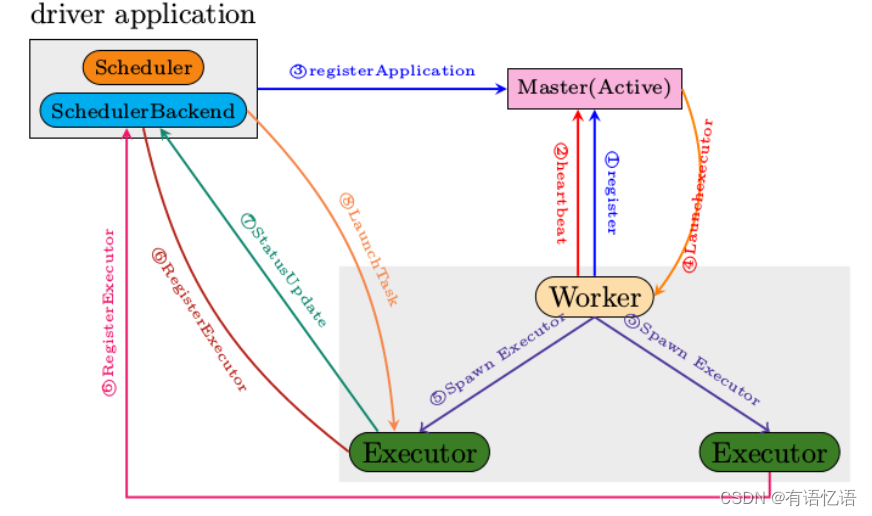
Spark Standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖其他资源管理系统。在该模式下,用户可以通过手动启动Master和Worker来启动一个独立的集群。其中,Master充当了资源管理的角色,Workder充当了计算节点的角色。在该模式下,Spark Driver程序在客户端(Client)运行,而Executor则在Worker节点上运行。
以下是一个运行在Standalone模式下,包含一个Master节点,两个Worker节点的Spark任务调度交互部署架构图。
从上面的Spark任务调度过程可以看到:
1)整个集群分为Master节点和Worker节点,其中Driver程序运行在客户端。Master节点负责为任务分配Worker节点上的计算资源,两者会通过相互通信来同步资源状态,见途中红色双向箭头。
2)客户端启动任务后会运行Driver程序,Driver程序中会完成SparkContext对象的初始化,并向Master进行注册。
3)每个Workder节点上会存在一个或者多个ExecutorBackend进程。每个进程包含一个Executor对象,该对象持有一个线程池,每个线程池可以执行一个任务(task)。ExecutorBackend进程还负责跟客户端节点上的Driver程序进行通信,上报任务状态。
1.2.1Standalone模式下任务运行过程
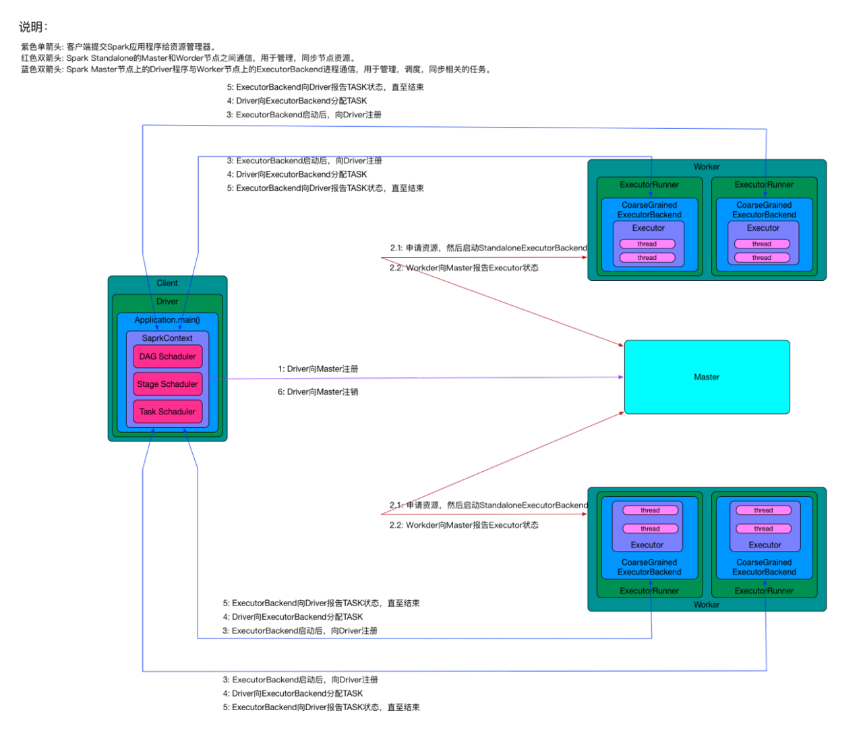
上面的过程反映了Spark在standalone模式下,整体上客户端、Master和Workder节点之间的交互。对于一个任务的具体运行过程需要更细致的分解,分解运行过程见图中的小字。
1.用户通过bin/spark-submit部署工具或者bin/spark-class启动应用程序的Driver进程,Driver进程会初始化SparkContext对象,并向Master节点进行注册。
1.Master节点接受Driver程序的注册,检查它所管理的Worker节点,为该Driver程序分配需要的计算资源Executor。Worker节点完成Executor的分配后,向Master报告Executor的状态。
2.Worker节点上的ExecutorBackend进程启动后,向Driver进程注册。
2.Driver进程内部通过DAG Schaduler,Stage Schaduler,Task Schaduler等过程完成任务的划分后,向Worker节点上的ExecutorBackend分配TASK。
1.ExecutorBackend进行TASK计算,并向Driver报告TASK状态,直至结束。
2.Driver进程在所有TASK都处理完成后,向Master注销。
1.2.2总结
Spark能够以standalone模式运行,这是Spark自身提供的运行模式,用户可以通过手动启动master和worker进程来启动一个独立的集群,也可以在一台机器上运行这些守护进程进行测试。standalone模式可以用在生产环境,它有效的降低了用户学习、测试Spark框架的成本。
standalone模式目前只支持跨应用程序的简单FIFO调度。然而,为了允许多个并发用户,你可以控制每个应用使用的资源的最大数。默认情况下,它会请求使用集群的全部CUP内核。
缺省情况下,standalone任务调度允许worker的失败(在这种情况下它可以将失败的任务转移给其他的worker)。但是,调度器使用master来做调度,这会产生一个单点问题:如果master崩溃,新的应用不会被创建。为了解决这个问题,可以zookeeper的选举机制在集群中启动多个master,也可以使用本地文件实现单节点恢复。
1.3yarn集群模式
Apache yarn是apache Hadoop开源项目的一部分。设计之初是为了解决mapreduce计算框架资源管理的问题。到haodoop 2.0使用yarn将mapreduce的分布式计算和资源管理区分开来。它的引入使得Hadoop分布式计算系统进入了平台化时代,即各种计算框架可以运行在一个集群中,由资源管理系统YRAN进行统一的管理和调度,从而共享整个集群资源、提高资源利用率。
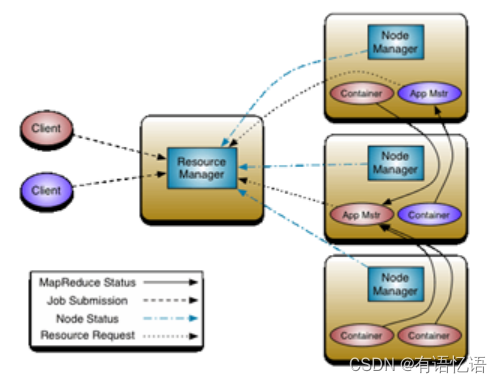
YARN总体上也Master/slave架构——ResourceManager/NodeManager。前者(RM)负责对各个NodeManager(NM)上的资源进行统一管理和调度。而container是资源分配和调度的基本单位,其中封装了机器资源,如内存、CPU、磁盘和网络等,每个任务会被分配一个Container,该任务只能在该Container中执行,并使用该Container封装的资源。NodeManager的作用则是负责接收并启动应用的container、而向RM回报本节点上的应用Container运行状态和资源使用情况。ApplicationMaster与具体的Application相关,主要负责同ResourceManager协商以获取合适的Container,并跟踪这些Container的状态和监控其进度。如下图所示为yarn集群的一般模型。
Spark在yarn集群上的部署方式分为两种,yarn client(driver运行在客户端)和yarn cluster(driver运行在master上),driver on master如下图所示。
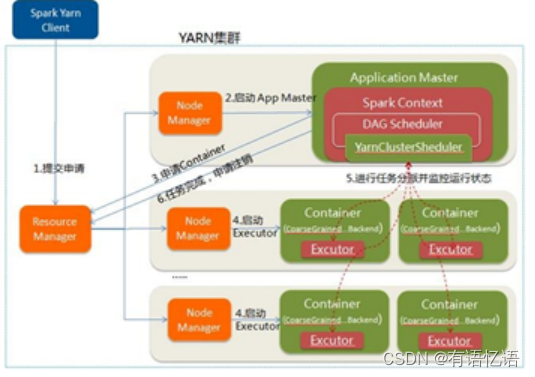
(1) Spark Yarn Client向YARN中提交应用程序,包括Application Master程序、启动Application Master的命令、需要在Executor中运行的程序等;
(2) Resource manager收到请求后,在其中一个node manager中为应用程序分配一个container,要求它在container中启动应用程序的Application Master,Application master初始化sparkContext以及创建DAG Scheduler和Task Scheduler。
(3) Application master根据sparkContext中的配置,向resource manager申请container,同时,Application master向Resource manager注册,这样用户可通过Resource manager查看应用程序的运行状态
(4) Resource manager 在集群中寻找符合条件的node manager,在node manager启动container,要求container启动executor,
(5) Executor启动后向Application master注册,并接收Application master分配的task
(6) 应用程序运行完成后,Application Master向Resource Manager申请注销并关闭自己。
Driver on client如下图所示:
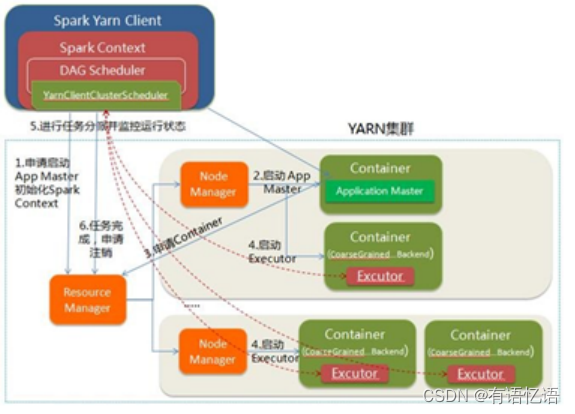
(1) Spark Yarn Client向YARN的Resource Manager申请启动Application Master。同时在SparkContent初始化中将创建DAG Scheduler和TASK Scheduler等
(2) ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派
(3) Client中的SparkContext初始化完毕后,与Application Master建立通讯,向Resource Manager注册,根据任务信息向Resource Manager申请资源(Container)
(4) 当application master申请到资源后,便与node manager通信,要求它启动container
(5) Container启动后向driver中的sparkContext注册,并申请task
(6) 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
从下图11:Yarn-client和Yarn cluster模式对比可以看出,在Yarn-client(Driver on client)中,Application Master仅仅从Yarn中申请资源给Executor,之后client会跟container通信进行作业的调度。如果client离集群距离较远,建议不要采用此方式,不过此方式有利于交互式的作业。
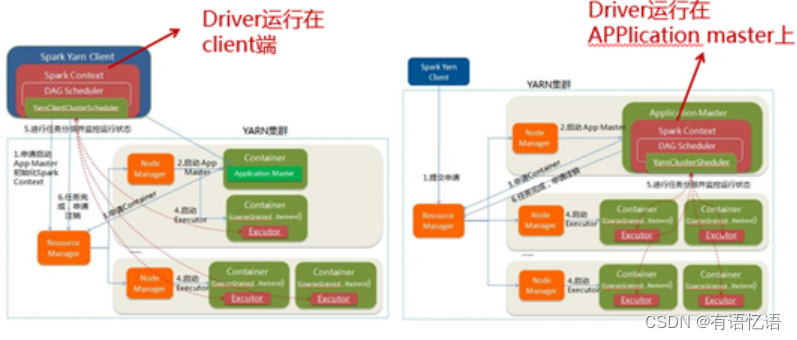
Spark能够以集群的形式运行,可用的集群管理系统有Yarn,Mesos等。集群管理器的核心功能是资源管理和任务调度。以Yarn为例,Yarn以Master/Slave模式工作,在Master节点运行的是Resource Manager(RM),负责管理整个集群的资源和资源分配。在Slave节点运行的Node Manager(NM),是集群中实际拥有资源的工作节点。我们提交Job以后,会将组成Job的多个Task调度到对应的Node Manager上进行执行。另外,在Node Manager上将资源以Container的形式进行抽象,Container包括两种资源内存和CPU。
以下是一个运行在Yarn集群上,包含一个Resource Manager节点,三个Node Manager节点(其中,两个是Worker节点,一个Master节点)的Spark任务调度交换部署架构图。
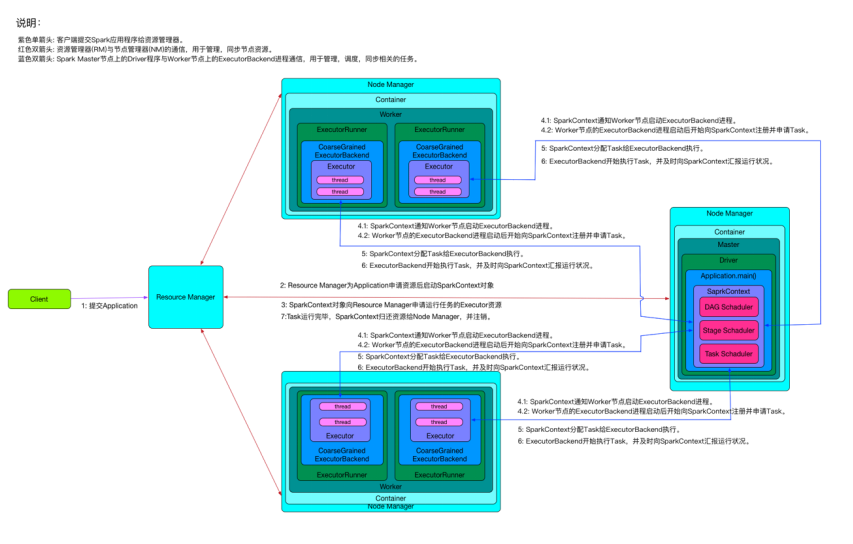
从上面的Spark任务调度过程图可以看到:
1)整个集群分为Master节点和Worker节点,它们都存在于Node Manager节点上,在客户端提交任务时由Resource Manager统一分配,运行Driver程序的节点被称为Master节点,执行具体任务的节点被称为Worder节点。Node Manager节点上资源的变化都需要及时更新给Resource Manager,见图中红色双向箭头。
2)Master节点上常驻Master守护进程 —— Driver程序,Driver程序中会创建SparkContext对象,并负责跟各个Worker节点上的ExecutorBackend进程进行通信,管理Worker节点上的任务,同步任务进度。实际上,在Yarn中Node Manager之间的关系是平等的,因此Driver程序会被调度到任何一个Node Manager节点。
3)每个Worker节点上会存在一个或者多个ExecutorBackend进程。每个进程包含一个Executor对象,该对象持有一个线程池,每个线程池可以执行一个任务(task)。ExecutorBackend进程还负责跟Master节点上的Driver程序进行通信,上报任务状态。
1.3.1集群下任务运行过程
上面的过程反映出了Spark在集群模式下,整体上Resource Manager和Node Manager节点间的交互,Master和Worker之间的交互。对于一个任务的具体运行过程需要更细致的分解,分解运行过程见图中的小字。
1)用户通过bin/spark-submit部署工具或者bin/spark-class向Yarn集群提交应用程序。
2)Yarn集群的Resource Manager为提交的应用程序选择一个Node Manager节点并分配第一个container,并在该节点的container上启动SparkContext对象。
3)SparkContext对象向Yarn集群的Resource Manager申请资源以运行Executor。
4)Yarn集群的Resource Manager分配container给SparkContext对象,SparkContext和相关的Node Manager通讯,在获得的container上启动ExecutorBackend守护进程,ExecutorBackend启动后开始向SparkContext注册并申请Task。
5)SparkContext分配Task给ExecutorBackend执行。
6)ExecutorBackend开始执行Task,并及时向SparkContext汇报运行状况。
Task运行完毕,SparkContext归还资源给Node Manager,并注销退。
1.4mesos集群模式
Mesos是apache下的开源分布式资源管理框架。起源于加州大学伯克利分校,后被twitter推广使用。Mesos上可以部署多种分布式框架,Mesos的架构图如下图12所示,其中Framework是指外部的计算框架,如Hadoop,Mesos等,这些计算框架可通过注册的方式接入mesos,以便mesos进行统一管理和资源分配。
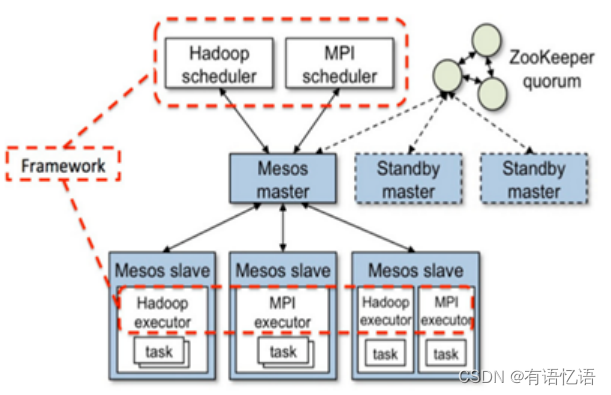
图12 mesos一般部署图
在 Mesos 上运行的 framework 由两部分组成:一个是 scheduler ,通过注册到master 来获取集群资源。另一个是在 slave 节点上运行的executor进程,它可以执行 framework 的 task 。 Master 决定为每个framework 提供多少资源,framework 的 scheduler来选择其中提供的资源。当 framework同意了提供的资源,它通过master将 task发送到提供资源的slaves 上运行。Mesos的资源分配图如下图13。
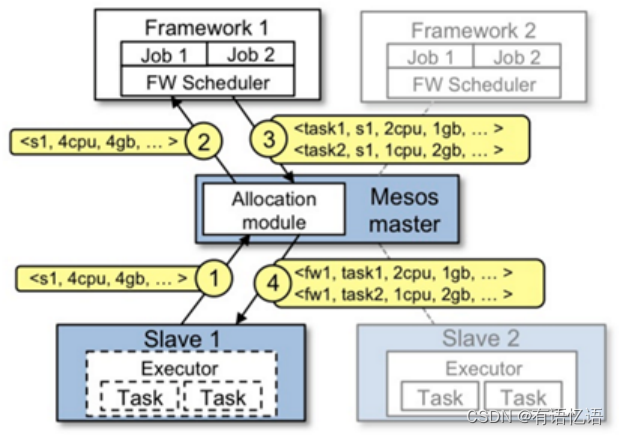
图13 mesos资源分配图
(1) Slave1 向 Master 报告,有4个CPU和4 GB内存可用
(2) Master 发送一个 Resource Offer 给 Framework1 来描述 Slave1 有多少可用资源
(3) FrameWork1 中的 FW Scheduler会答复 Master,我有两个 Task 需要运行在 Slave1,一个 Task 需要<2个CPU,1 GB内存=“”>,另外一个Task需要<1个CPU,2 GB内存=“”>
(4) 最后,Master 发送这些 Tasks 给 Slave1。然后,Slave1还有1个CPU和1 GB内存没有使用,所以分配模块可以把这些资源提供给 Framework2
Spark可作为其中一个分布式框架部署在mesos上,部署图与mesos的一般框架部署图类似,如下图14,这里不再重述。
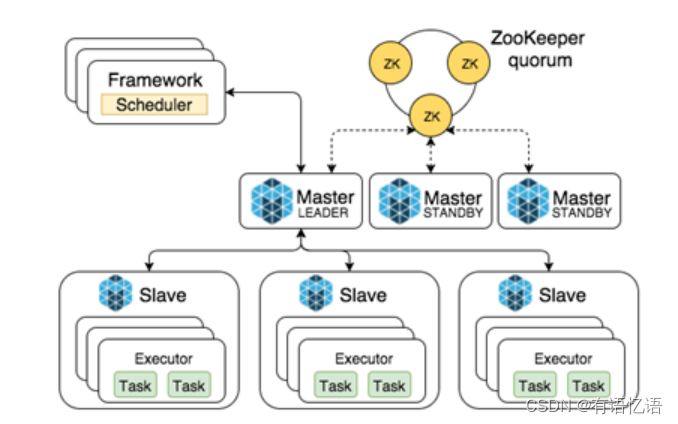
1.5spark 三种部署模式的区别
在这三种部署模式中,standalone作为spark自带的分布式部署模式,是最简单也是最基本的spark应用程序部署模式,这里就不再赘述。这里就讲一下yarn和mesos的区别:
(1) 就两种框架本身而言,mesos上可部署yarn框架。而yarn是更通用的一种部署框架,而且技术较成熟。
(2) mesos双层调度机制,能支持多种调度模式,而Yarn通过Resource Mananger管理集群资源,只能使用一种调度模式。Mesos 的双层调度机制为:mesos可接入如yarn一般的分布式部署框架,但Mesos要求可接入的框架必须有一个调度器模块,该调度器负责框架内部的任务调度。当一个framework想要接入mesos时,需要修改自己的调度器,以便向mesos注册,并获取mesos分配给自己的资源, 这样再由自己的调度器将这些资源分配给框架中的任务,也就是说,整个mesos系统采用了双层调度框架:第一层,由mesos将资源分配给框架;第二层,框架自己的调度器将资源分配给自己内部的任务。
(3) mesos可实现粗、细粒度资源调度,可动态分配资源,而Yarn只能实现静态资源分配。其中粗粒度和细粒度调度定义如下:
粗粒度模式(Coarse-grained Mode):程序运行之前就要把所需要的各种资源(每个executor占用多少资源,内部可运行多少个executor)申请好,运行过程中不能改变。
细粒度模式(Fine-grained Mode):为了防止资源浪费,对资源进行按需分配。与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
从yarn和mesos的区别可看出,它们各自有优缺点。因此实际使用中,选择哪种框架,要根据本公司的实际需要而定,可考虑现有的大数据生态环境。如我司采用yarn部署spark,原因是,我司早已有较成熟的hadoop的框架,考虑到使用的方便性,采用了yarn模式的部署。
1.6异常场景分析
上面说明的是正常情况下,各节点的消息分发细节。那么如果在运行中,集群中的某些节点出现了问题,整个集群是否还能够正常处理Application中的任务呢?
1.6.1异常分析1: worker异常退出
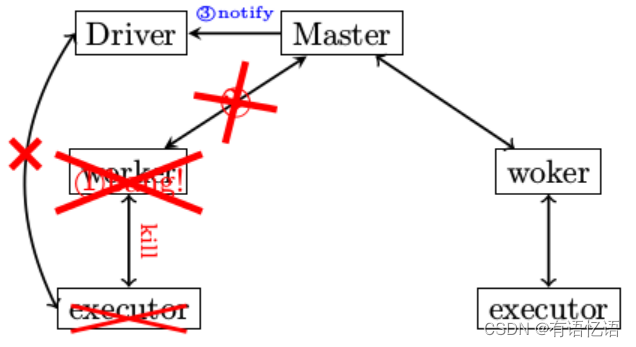
在Spark运行过程中,经常碰到的问题就是worker异常退出,当worker退出时,整个集群会有哪些故事发生呢? 请看下面的具体描述
1)worker异常退出,比如说有意识的通过kill指令将worker杀死
2)worker在退出之前,会将自己所管控的所有小弟executor全干掉
3)worker需要定期向master改善心跳消息的,现在worker进程都已经玩完了,哪有心跳消息,所以Master会在超时处理中意识到有一个“分舵”离开了
4)Master非常伤心,伤心的Master将情况汇报给了相应的Driver
5)Driver通过两方面确认分配给自己的Executor不幸离开了,一是Master发送过来的通知,二是Driver没有在规定时间内收到Executor的StatusUpdate,于是Driver会将注册的Executor移除
1.6.1.1 后果分析
worker异常退出会带来哪些影响
1)executor退出导致提交的task无法正常结束,会被再一次提交运行
2)如果所有的worker都异常退出,则整个集群不可用
3)需要有相应的程序来重启worker进程,比如使用supervisord或runit
1.6.1.2 测试步骤
1)启动Master
2)启动worker
3)启动spark-shell
4)手工kill掉worker进程
5)用jps或ps -ef|grep -i java来查看启动着的java进程
1.6.1.3 异常退出的代码处理
定义于ExecutorRunner.scala的start函数
def start() {
workerThread = new Thread("ExecutorRunner for " + fullId) {
override def run() {
fetchAndRunExecutor() }
}
workerThread.start()
// Shutdown hook that kills actors on shutdown.
shutdownHook = new Thread() {
override def run() {
killProcess(Some("Worker shutting down"))
}
}
Runtime.getRuntime.addShutdownHook(shutdownHook)
}
killProcess的过程就是停止相应CoarseGrainedExecutorBackend的过程。
worker停止的时候,一定要先将自己启动的Executor停止掉。
1.6.1.4 小结
需要特别指出的是,当worker在启动Executor的时候,是通过ExecutorRunner来完成的,ExecutorRunner是一个独立的线程,和Executor是一对一的关系,这很重要。Executor作为一个独立的进程在运行,但会受到ExecutorRunner的严密监控。
1.6.2异常分析2: executor异常退出
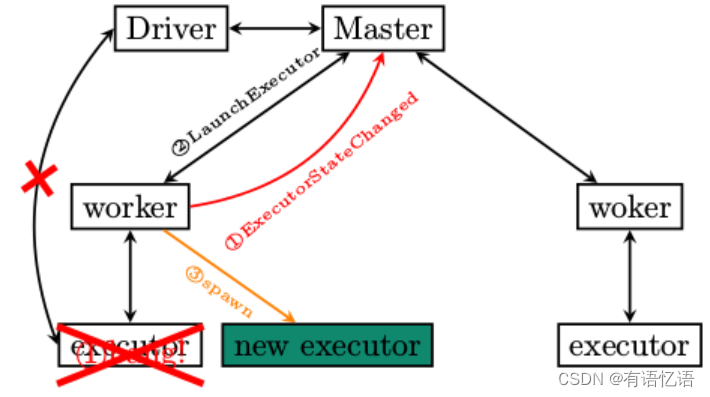
Executor作为Standalone集群部署方式下的最底层员工,一旦异常退出,其后果会是什么呢?
executor异常退出,ExecutorRunner注意到异常,将情况通过ExecutorStateChanged汇报给Master
Master收到通知之后,非常不高兴,尽然有小弟要跑路,那还了得,要求Executor所属的worker再次启动
Worker收到LaunchExecutor指令,再次启动executor
1.6.2.1 测试步骤
1)启动Master
2)启动Worker
3)启动spark-shell
4)手工kill掉CoarseGrainedExecutorBackend
1.6.2.2 fetchAndRunExecutor
fetchAndRunExecutor负责启动具体的Executor,并监控其运行状态,具体代码逻辑如下所示
def fetchAndRunExecutor() {
try {
// Create the executor's working directory
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// Launch the process
val command = getCommandSeq
logInfo("Launch command: " + command.mkString("\"", "\" \"", "\""))
val builder = new ProcessBuilder(command: _*).directory(executorDir)
val env = builder.environment()
for ((key, value) {
logInfo("Runner thread for executor " + fullId + " interrupted")
state = ExecutorState.KILLED
killProcess(None)
}
case e: Exception => {
logError("Error running executor", e)
state = ExecutorState.FAILED
killProcess(Some(e.toString))
}
}
}
1.6.3异常分析3: master 异常退出
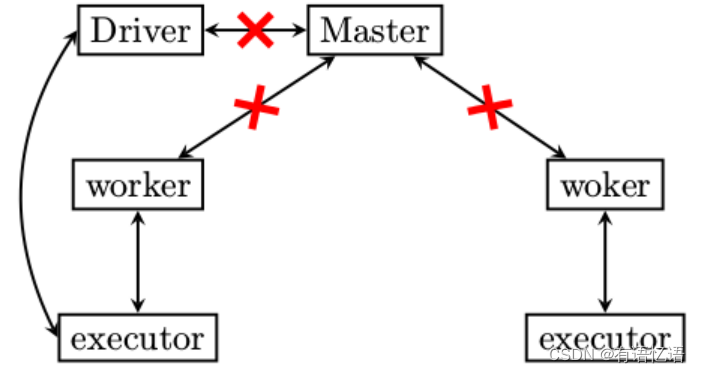
worker和executor异常退出的场景都讲到了,我们剩下最后一种情况了,master挂掉了怎么办?
带头大哥如果不在了,会是什么后果呢?
1)worker没有汇报的对象了,也就是如果executor再次跑飞,worker是不会将executor启动起来的,大哥没给指令
2)无法向集群提交新的任务
3)老的任务即便结束了,占用的资源也无法清除,因为资源清除的指令是Master发出的
2、wordcount程序运行原理窥探
2.1spark之scala实现wordcount
在spark中使用scala来实现wordcount(统计单词出现次数模型)更加简单,相对java代码上更加简洁,其函数式编程的思维逻辑也更加直观。
package com.spark.firstApp
import org.apache.spark.{
SparkContext, SparkConf}
/**
* Created by atguigu,scala实现wordcount
*/
object WordCount1 {
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: WordCount1 <file1>")
System.exit(1)
}
/**
* 1、实例化SparkConf;
* 2、构建SparkContext,SparkContext是spark应用程序的唯一入口
* 3. 通过SparkContext的textFile方法读取文本文件
*/
val conf = new SparkConf().setAppName("WordCount1").setMaster("local")
val sc = new SparkContext(conf)
/**
* 4、通过flatMap对文本中每一行的单词进行拆分(分割符号为空格),并利用map进行函数转换形成(K,V)形式,再进行reduceByKey,打印输出10个结果
* 函数式编程更加直观的反映思维逻辑
*/
sc.textFile(args(0)).flatMap(_.split(" ")).map(x => (x, 1)).reduceByKey(_ + _).take(10).foreach(println)
sc.stop()
}
}
2.2原理
在spark集群中运行wordcount程序其主要业务逻辑比较简单,涵盖一下3个过程:
1)读取存储介质上的文本文件(一般存储在hdfs上);
2)对文本文件内容进行解析,按照单词进行分组统计汇总;
3)将过程2的分组结果保存到存储介质上。(一般存储在hdfs或者RMDB上)
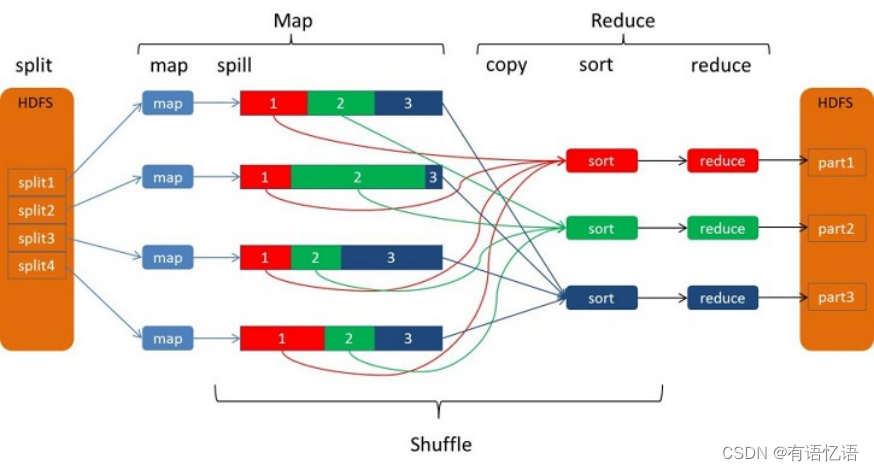
虽然wordcount的业务逻辑非常简单,但其应用程序在spark中的运行过程却巧妙得体现了spark的核心精髓——分布式弹性数据集、内存迭代以及函数式编程等特点。下图对spark集群中wordcount的运行过程进行剖析,加深对spark技术原理窥探。
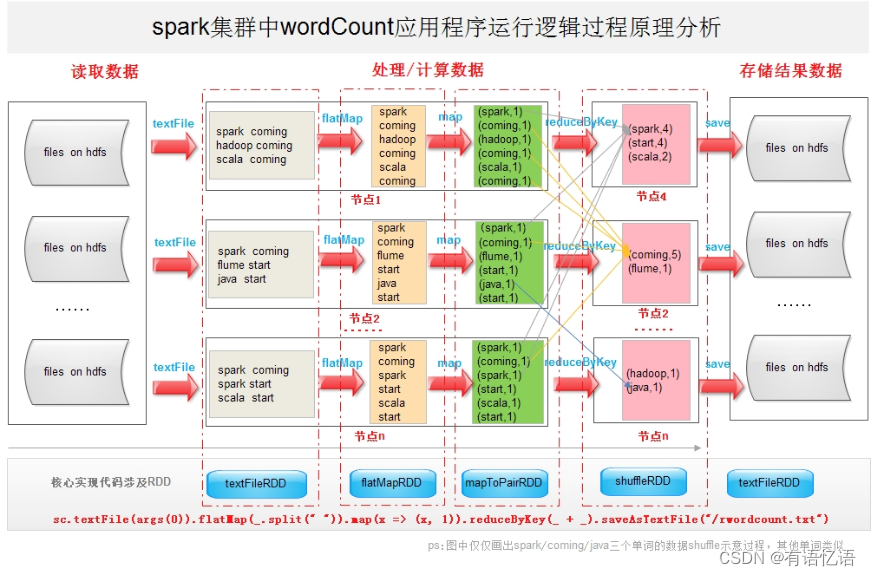
该图横向分割下面给出了wordcount的scala核心程序实现,该程序在spark集群的运行过程涉及几个核心的RDD,主要有textFileRDD、flatMapRDD、mapToPairRDD、shuffleRDD(reduceByKey)等。
应用程序通过textFile方法读取hdfs上的文本文件,数据分片的形式以RDD为统一模式将数据加载到不同的物理节点上,如上图所示的节点1、节点2到节点n;并通过一系列的数据转换,如利用flatMap将文本文件中对应每行数据进行拆分(文本文件中单词以空格为分割符号),形成一个以每个单词为核心新的数据集合RDD;之后通过MapRDD继续转换形成形成(K,V)数据形式,以便进一步使用reduceByKey方法,该方法会触发shuffle行为,促使不同的单词到对应的节点上进行汇聚统计(实际上在夸节点进行数据shuffle之前会在本地先对相同单词进行合并累加),形成wordcount的统计结果;最终通过saveAsTextFile方法将数据保存到hdfs上。具体的运行逻辑原理以及过程上图给出了详细的示意说明。