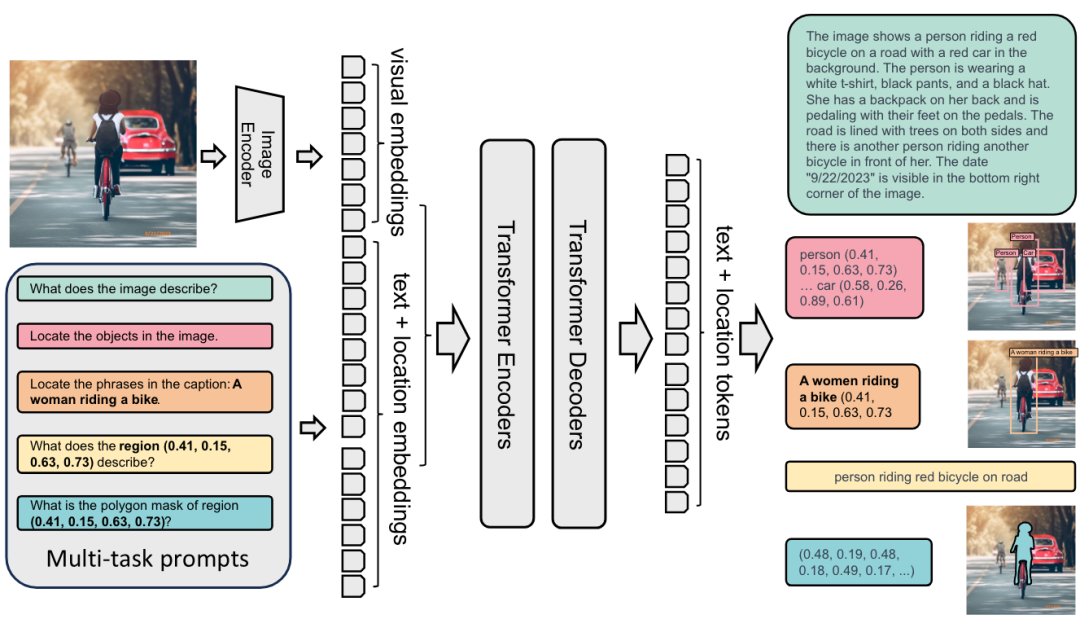
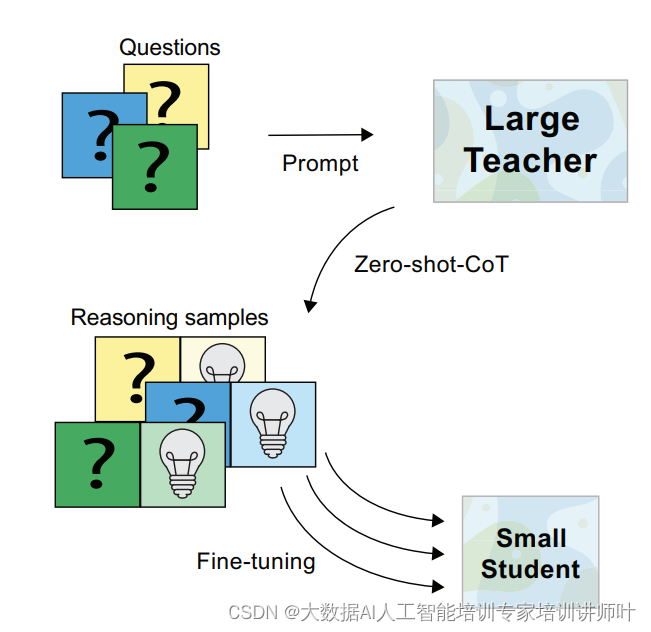
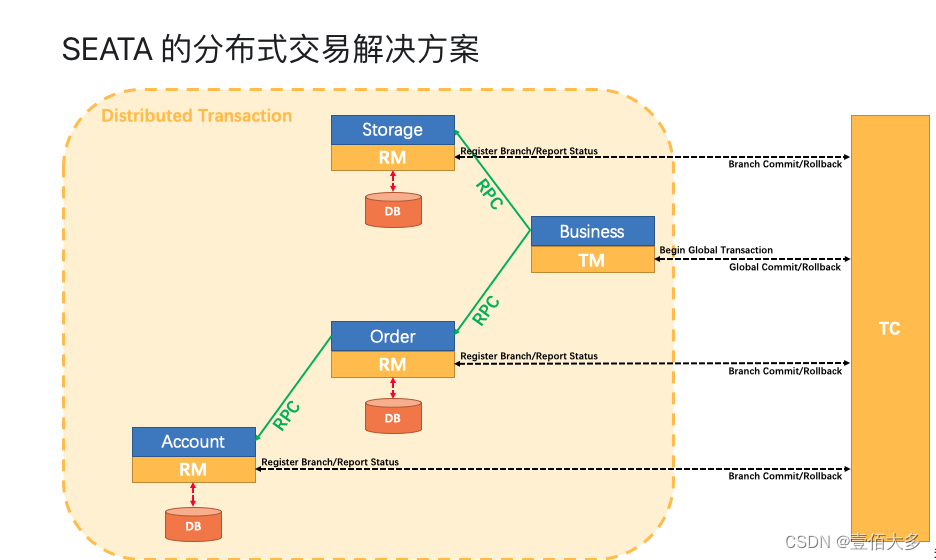
1. 传统基准的固有局限
- VQAv2:视觉问题回答数据集,主要用于评估视觉理解与推理能力。
- COCO Caption:图像描述生成数据集,用于评估模型对图像内容的理解与描述能力。
- GQA:结合常识的视觉问题回答数据集。
- OK-VQA:需要外部知识的视觉问题回答数据集。
- TextVQA:图像中包含文本的问题回答数据集。
- 主观性基准(例如mPLUG-Owl等):依赖人类评估
这些传统基准测试存在以下问题:
- 评价指标要求预测与参考答案完全匹配,可能导致许多误判样本。
- 基准测试侧重评估特定任务,无法对模型的多方面能力进行细粒度评估。
- 提供的反馈有限,难以指导模型的进一步优化。
本文提出的观点:论文链接:https://arxiv.org/pdf/2307.06281.pdf

2. 本文摘要
MMBench,是一个针对大规模多模态模型的新型评估基准。随着视觉语言模型在感知和推理能力方面的显著进步,如何有效地评估这些模型成为了一个主要难题。传统基准如VQAv2和COCO Caption提供了定量性能测量,但在细粒度能力和鲁棒性评估指标方面存在不足。而像OwlEval这样的主观性基准虽然能够全面评价模型能力,但其可扩展性差且易受偏见影响。
MMBench设计了一套综合的评估流水线,包含两大核心元素:
- 一是精心构建的超越现有同类基准的数据集,该数据集包括2,974个经过细致挑选的问题,覆盖了20种不同类型的细粒度技能;
- 二是引入了创新的CircularEval策略,并结合使用ChatGPT技术来将模型生成的自由格式预测转化为预定义选项,以实现对模型预测的更可靠评估。
通过MMBench对14个知名视觉语言模型进行全面评估后发现,现有模型在多项选择题上的表现普遍不尽人意,大多数模型在MMBench测试集上面对最多4个选项的选择题时,Top-1准确率未达到50%,表明当前VLMs在应对不同提示下的预测一致性以及跨实例理解与逻辑推理等方面的能力有限。特别是跨实例理解和逻辑推理能力显得尤为薄弱,需要作为未来研究的重要方向加以改进。
此外,文档提到对象定位数据的引入有望提高模型性能,其中Kosmos-2和Shikra等模型在应用了此类数据后显示出明显的性能提升。同时,文中列举了多个视觉语言模型及其参数规模,并报告了它们在MMBench开发集上的具体表现,强调了采用更加严格、合理的CircularEval评估策略的重要性。

3. 核心知识点
- 视觉语言模型评估挑战:
-
- 文章指出当前大规模视觉语言模型的发展迅速,但对其有效评估仍是一大挑战。
- 传统评估基准(如VQAv2、COCO Caption)侧重于定量性能指标,但缺乏对模型细粒度能力的精细评估及评估指标的鲁棒性。
- MMBench基准介绍ÿ