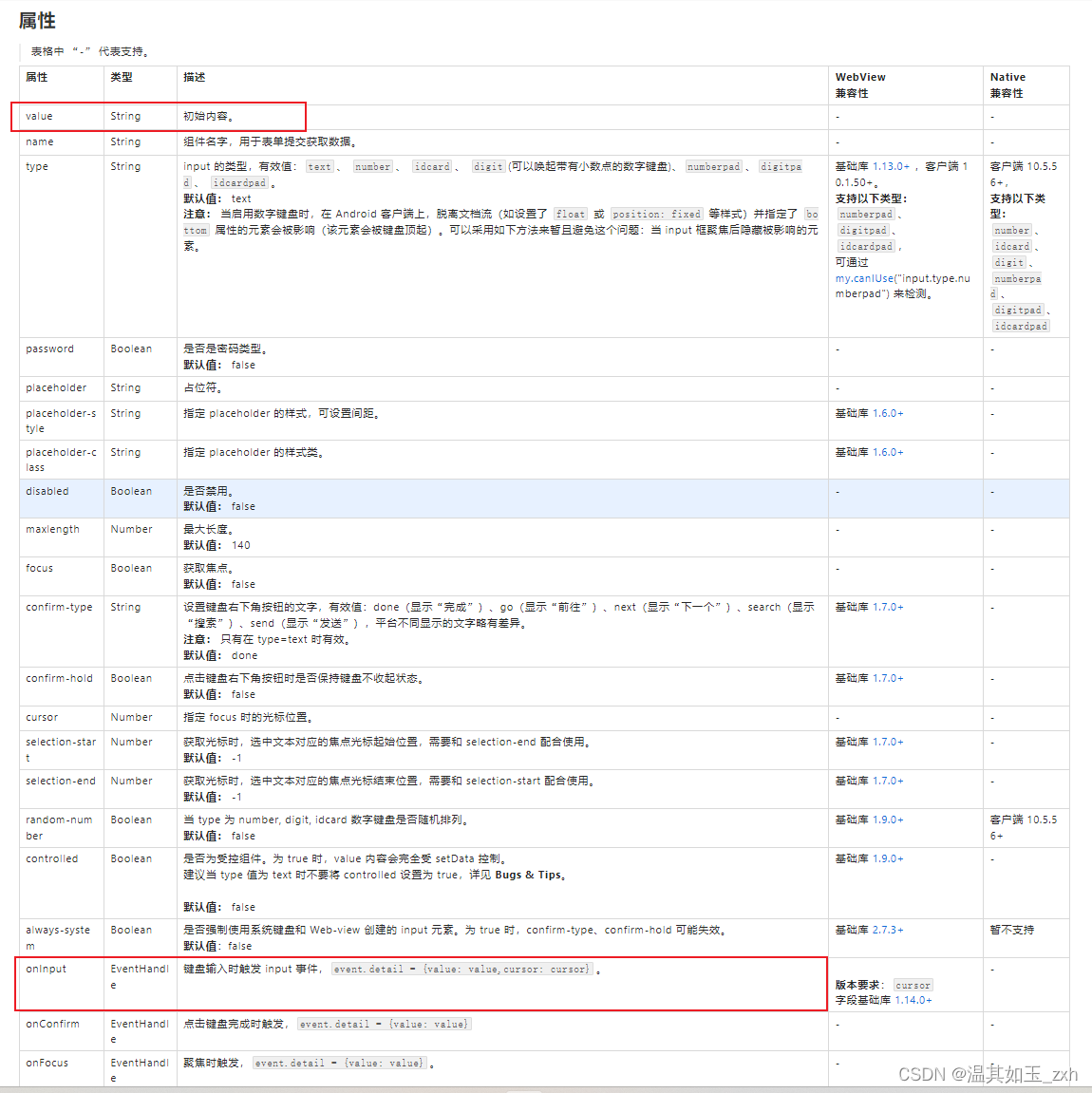
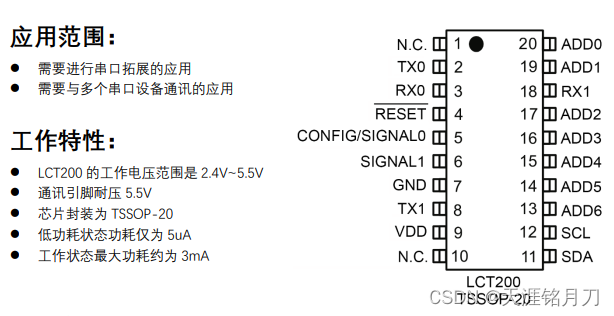
为什么要进行数据扩充
数据扩充在机器学习中扮演着重要的角色,原因如下:
1. 解决数据稀缺问题:
- 数据量不足: 在实际应用中,获取大量高质量标记数据可能很困难或昂贵。数据扩充能帮助充分利用有限数据集,增加训练数据数量,减少模型过拟合风险。
2. 提高模型泛化能力:
- 增加样本多样性: 数据扩充可以通过引入各种变换、旋转、翻转等方式,生成多样化的样本,使模型更好地理解数据的不同变化和情况,提高泛化能力。
3. 提升模型鲁棒性:
- 对抗噪声和变化: 引入数据扩充技术可以使模型对噪声、图像变换、光照变化等更加鲁棒,提升模型的稳健性。
4. 数据平衡处理:
- 类别不平衡: 在分类问题中,某些类别可能数据量很少。数据扩充可以帮助平衡不同类别的数据分布,防止模型偏向于数量较多的类别。
5. 降低过拟合风险:
- 限制模型依赖性: 数据扩充有助于减少模型对特定样本的过度依赖,降低过拟合的风险,使模型更具泛化能力。
6. 提高模型效果和性能:
- 增加训练样本: 更多的数据意味着模型可以更好地学习特征和模式,进而提高预测效果和性能